SmoothOperator: reducing power fragmentation and improving power utilization in large-scale datacenters Hsu et al., ASPLOS’18
What do you do when your theory of constraints analysis reveals that power has become your major limiting factor? That is, you can’t add more servers to your existing datacenter(s) without blowing your power budget, and you don’t want to build a new datacenter just for that? In this paper, Hsu et al. analyse power utilisation in Facebook datacenters and find that overall power budget utilisation can be comparatively low, even while peak requirements are at capacity. We can’t easily smooth the workload (that’s driven by business and end-user requirements), but maybe we can do something to smooth the power usage.
Our experiments based on real production workload and power traces show that we are able to host up to 13% more machines in production, without changing the underlying power infrastructure. Utilizing the unleashed power headroom with dynamic reshaping, we achieve up to an estimated total of 15% and 11% throughput improvement for latency-critical service and batch service respectively at the same time, with up to 44% of energy slack reduction.
No more headroom and low utilisation…
There’s a maximum safe amount of power that the power infrastructure at a given datacenter can supply. Naturally, we need the peak power demand to remain under this budget. Given user facing workloads with fluctuating levels of demand (typically, diurnal patterns), it’s easy to end up with highly underutilised power budgets during the rest of the day.
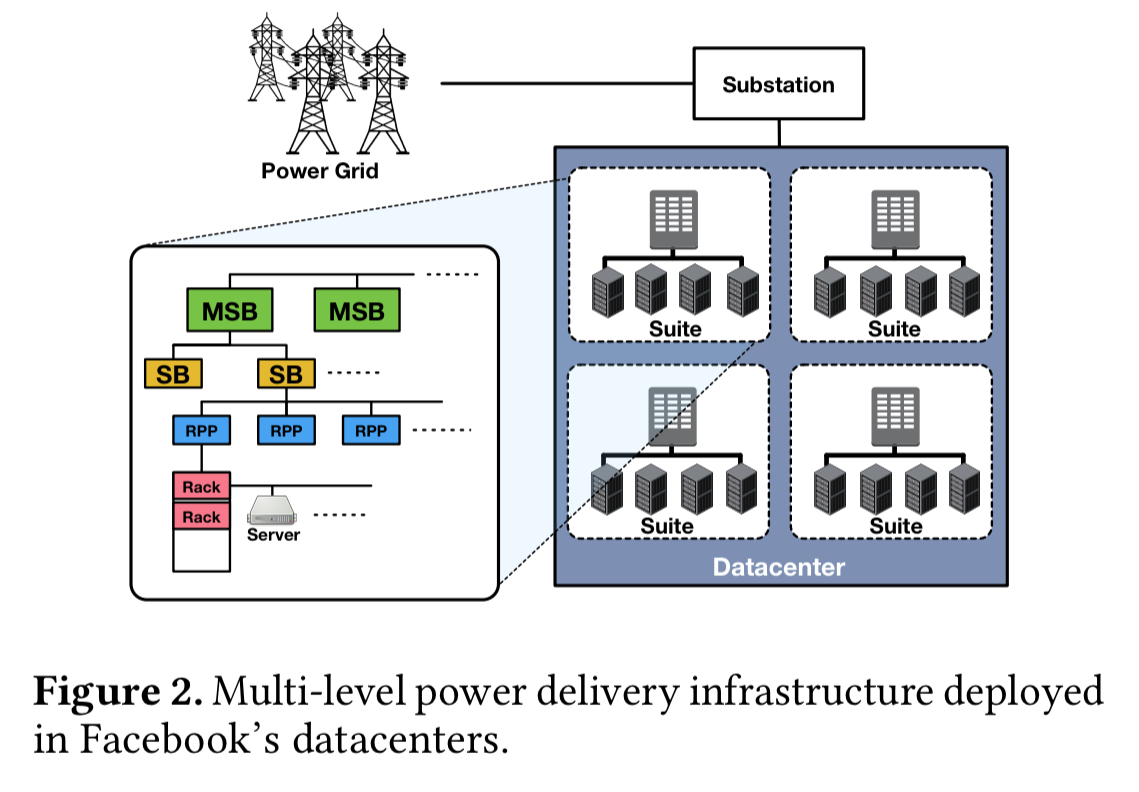
The situation is made worse by the multi-level power delivery infrastructure . Facebook datacenters are composed of multiple rooms (called suites). Suites have multiple main switching boards (MSBs), each of which supplies some second-level switching boards (SBs), which further feed a set of reactive power panels (RPPs). From here the power is fed into racks, each composed of tens of servers. The power budget of each node is approximately the sum of the budgets of its children.
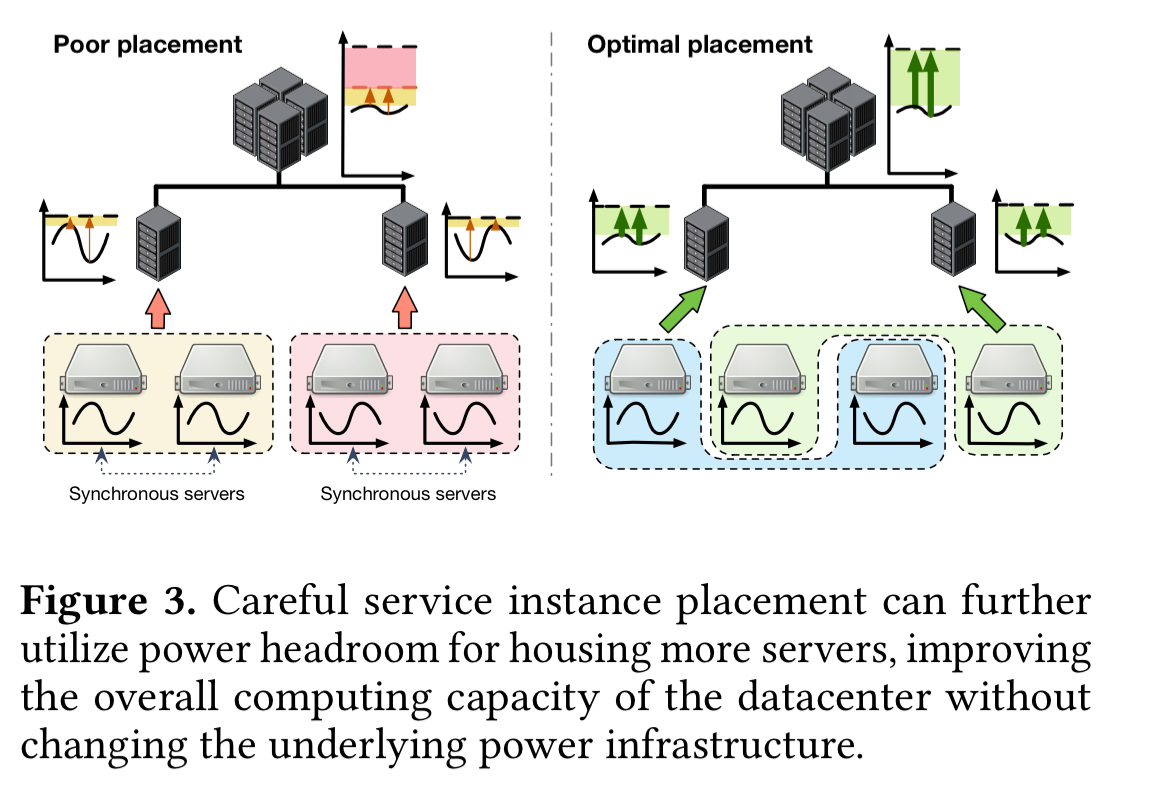
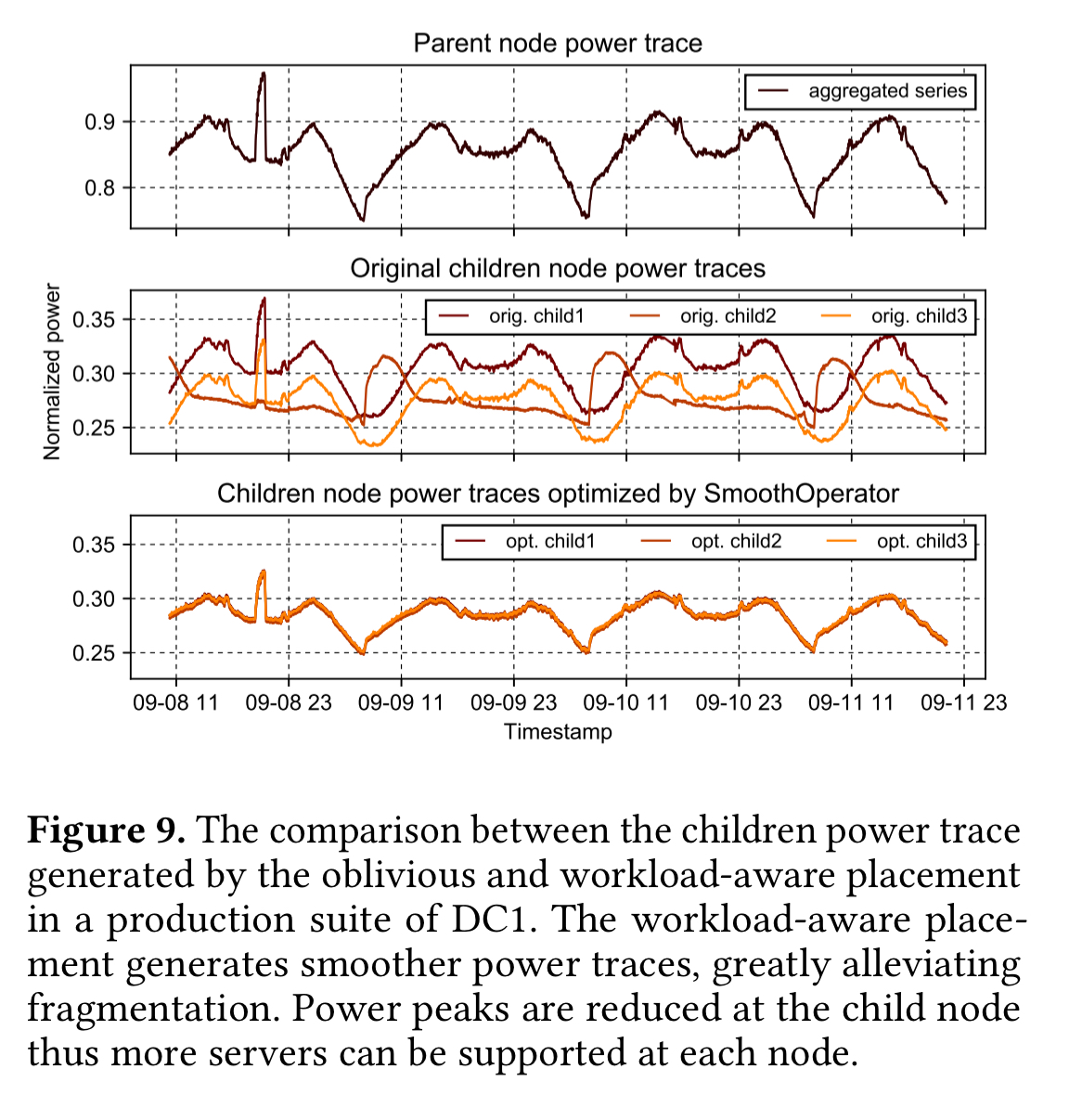
Power budget-fragmentation exists because servers hosting the services with synchronous power consumption patterns are grouped together under the same sub-tree of the multi-level power infrastructure. Such a placement creates rapid, unbalanced peaks with a high amplitude, which consume the power budget of the supplying power node fast.
(If you go over the budget of course, a circuit-breaker— a real circuit-breaker ;)— trips and you lose power in the whole sub-tree).
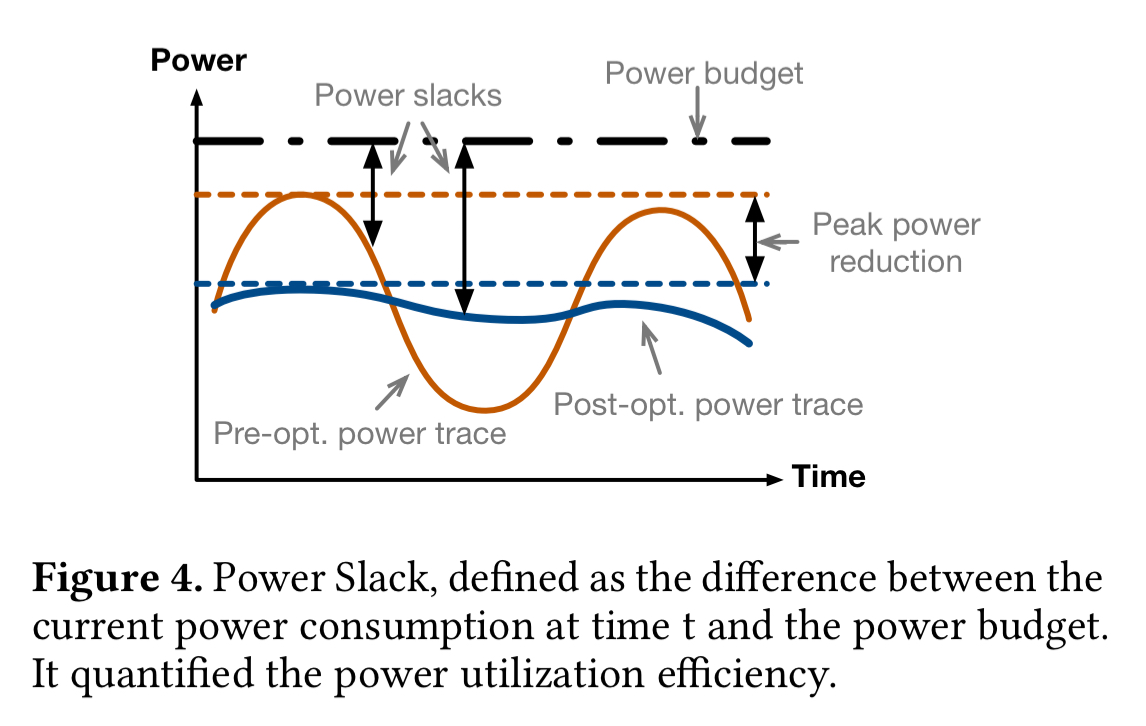
The level of power budget fragmentation and the inefficiencies in the power budget utilisation are captured in two main metrics: sum of peaks, and power slack.
- Sum of peaks simply adds up the peak power demand (during the period of measurement, one week in this study) at each of the power nodes in the datacenter. With an unbalanced placement, each node may see a high peak at some point in time, leading to a larger ‘sum of peaks’ value overall.
- Power-slack measures the unused power budget at a given point in time (the total power budget minus the current demand). Lower slack equals higher utilisation. Energy slack is the integral of power slack over a given timespan. Low energy slack means the power budget is highly utilised over the corresponding timespan.
Workload aware placement and remapping
The basic idea is easy to grasp. Instead of co-locating services synchronised power demands (leading to high peaks and low troughs), strive for a balanced mix of power demands under each power node, to smooth things out.
Take a look at the diurnal power demand patterns for three major Facebook services: web clusters, db clusters, and hadoop. These reveal the opportunity for blending.
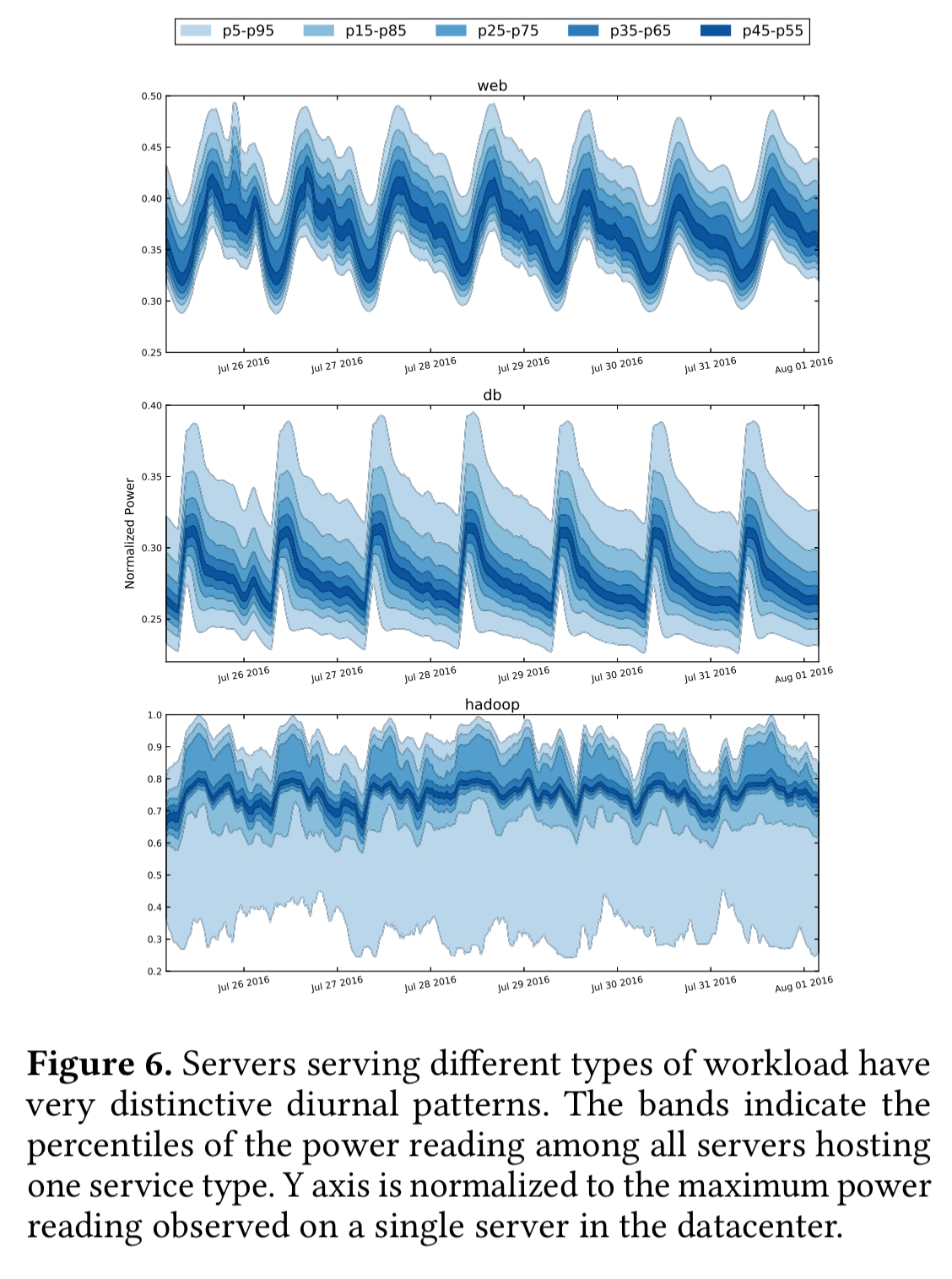
The web clusters serve end user traffic and are one of the largest consumers of power budget. The servers in these clusters have highly synchronous power patterns, following the typical user activity level.
The db servers are shielded by caching layer(s) and are more I/O-bound, thus even when the front-end servers are experienced heavy load they do not exhibit high power consumption. At night though, when performing the daily backup they do a lot of data compression which drives high power usage. Thus the db servers also have a diurnal pattern, but their peaks occur during the night.
Hadoop clusters are optimised for high throughput, but are not tied to any direct user interaction. Their power consumption is constantly high.
A service is a collection of hundreds to thousands of server instances (interesting side note, all deployed directly as native processes – no VMs or containers in sight). Even within the same service, there can be significant amounts of instance-level heterogeneity in power demands. This usually stems from imbalanced access patterns or skewed popularity amongst different service instances.
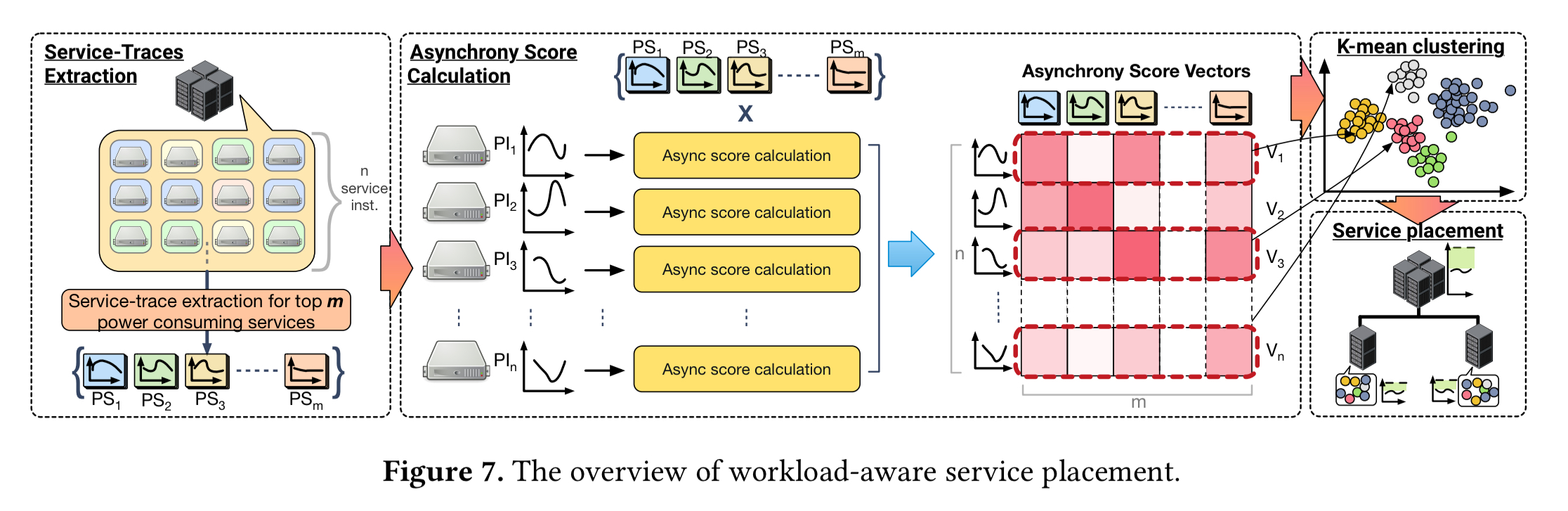
The SmoothOperator placement framework aims to take all of this into account to find power-balanced instance placements. It can also monitor the datacenter over time to make fine-tuned adjustments if things start to move out of balance. There are four main stages to the SmoothOperator workflow:
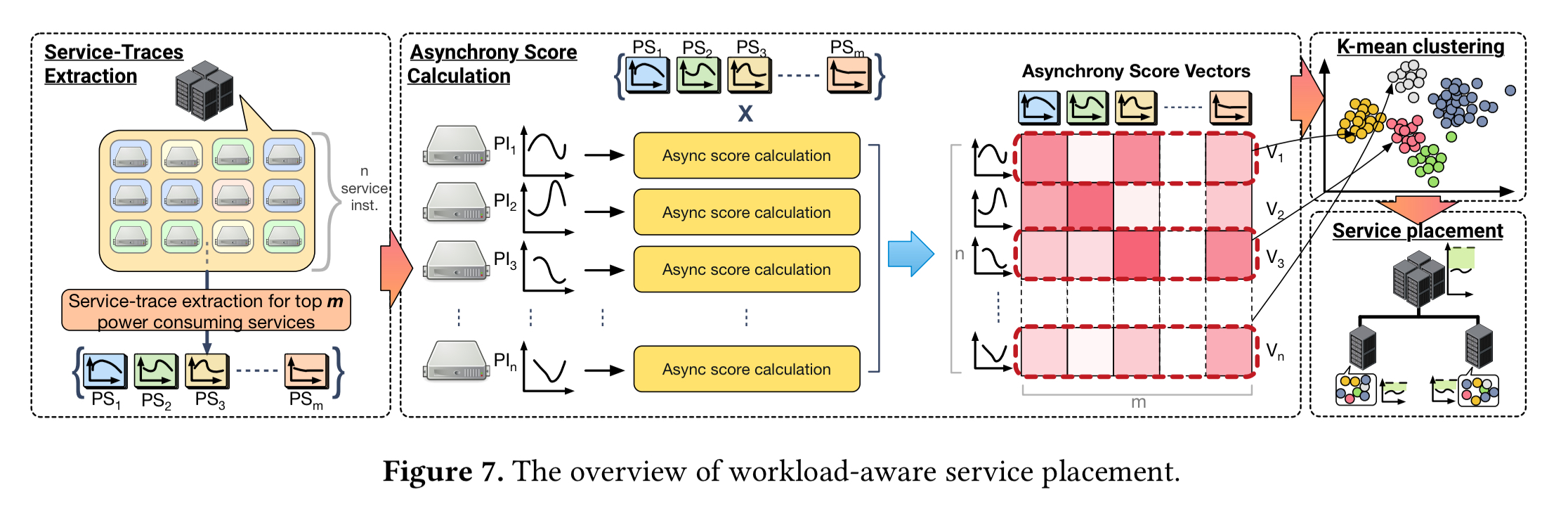
- Collecting traces (over multiple weeks) for each service instance. These are also combined to create overall service power traces for each of the top power-consuming services. The service power traces capture the in-aggregate behaviour of the service instances.
- Calculating asynchrony scores. Each service instance is compared against the overall service power trace for each of the services. The result is an n-dimensional vector (where n is the number of services) in which each element indicates how aligned power requirements of the instance are with that service. A low asynchrony score indicates the power demands move more closely together, a high asynchrony scores indicates they are more independent.
- We take the asynchrony score vectors and run a clustering algorithm to find clusters that exhibit largely synchronous power consumption.
- The clustering results are used to guide workload placement. The goal is to have high asynchrony scores at all levels of power nodes, which maximises the power headroom and mitigates fragmentation.
Placement works as follows. Starting at the top level in the multi-level power delivery system, we know that we need to divide service instances across q second-level nodes. We use k-means clustering to obtain h clusters, where h is a multiple of q. An additional constraint in this process is that each cluster must have the same number of instances (which must result in some strained clusters!). Now we simply iterate through all the clusters and assign 1/q of the service instances in each to each second-level power node. We can repeat this process at each level of the hierarchy until the leaf nodes are reached.
Here you can see the smoothing of power demand achieved by the algorithm at a sample node in the hierarchy:
There are three datacenters involved in the study. For each of these datacenters, the following chart shows the peak-power reduction achieved at each level in the datacentre (from suites all the way down to the reactive power panels).
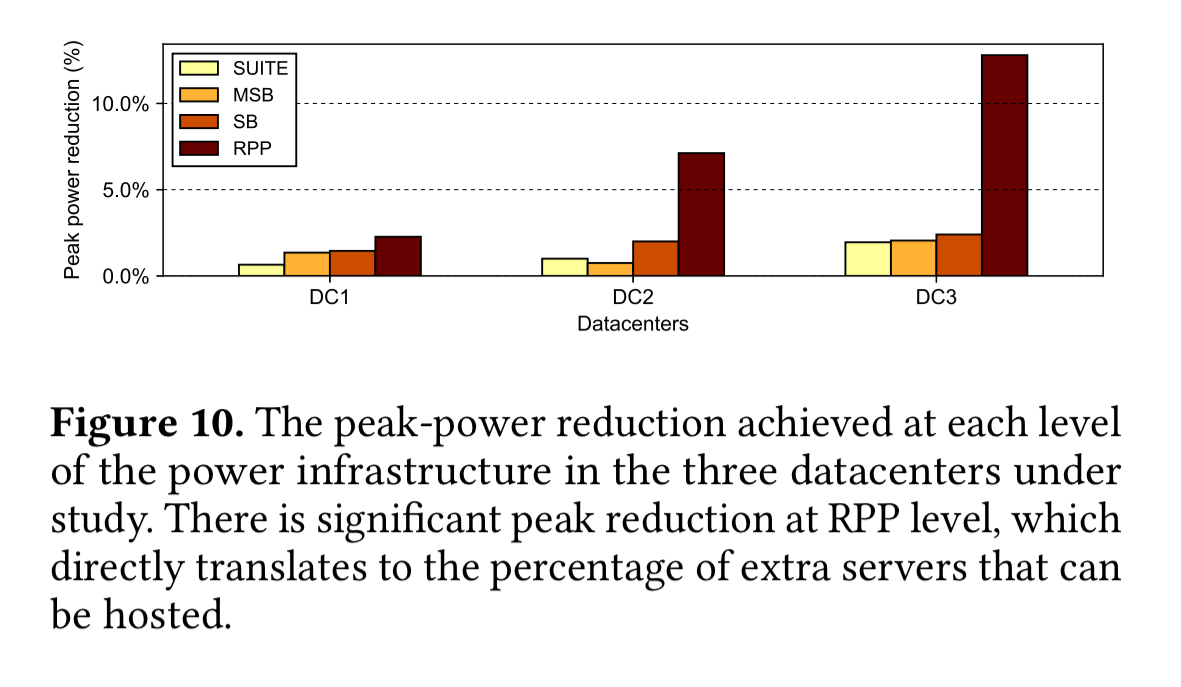
Our workload-aware service instance placement can reduce the peak power by 2.3%, 7.1%, and 13.1% for the three datacenters respectively.
(The effects are less pronounced as you move up the hierarchy because you naturally include more instances in your ‘sample’, which leads to more heterogeneity).
What should we do with the new servers we can now squeeze in?
With the peak power demands reduced, we can now squeeze more servers into our datacenters! But where should we put them, and what should they do? If we dedicate them to latency critical workloads (e.g., web) we’ll be able to handle more traffic at peak, but they’ll be under-utilised off peak. It would be better if we could use the new servers to help with latency critical workloads under peak loads, and batch throughput during off-peak hours. (We seem to be rediscovering the idea of auto-scaling here!!).
Facebook has recently been widely deploying storage-disaggregated servers, in which the main storage components (e.g. flash memory) are accessed over the network. (I.e., a move from directly-attached storage to network-attached storage). Fast networks make this approach make sense. With your storage subsystem decoupled from your compute, it’s easy to switch the service a given node is running because data remains intact and accessible from anywhere. (I can almost hear Google saying ‘I told you so…’ ;) ).
The main novelty here then, is switching the job that a given server is handling based on power-budget considerations. When the average power load level of latency-critical workload services falls below a threshold some of them are converted to run batch workloads (and vice versa). Throughput is further maximised by throttling the power consumption of batch clusters during peak hours.
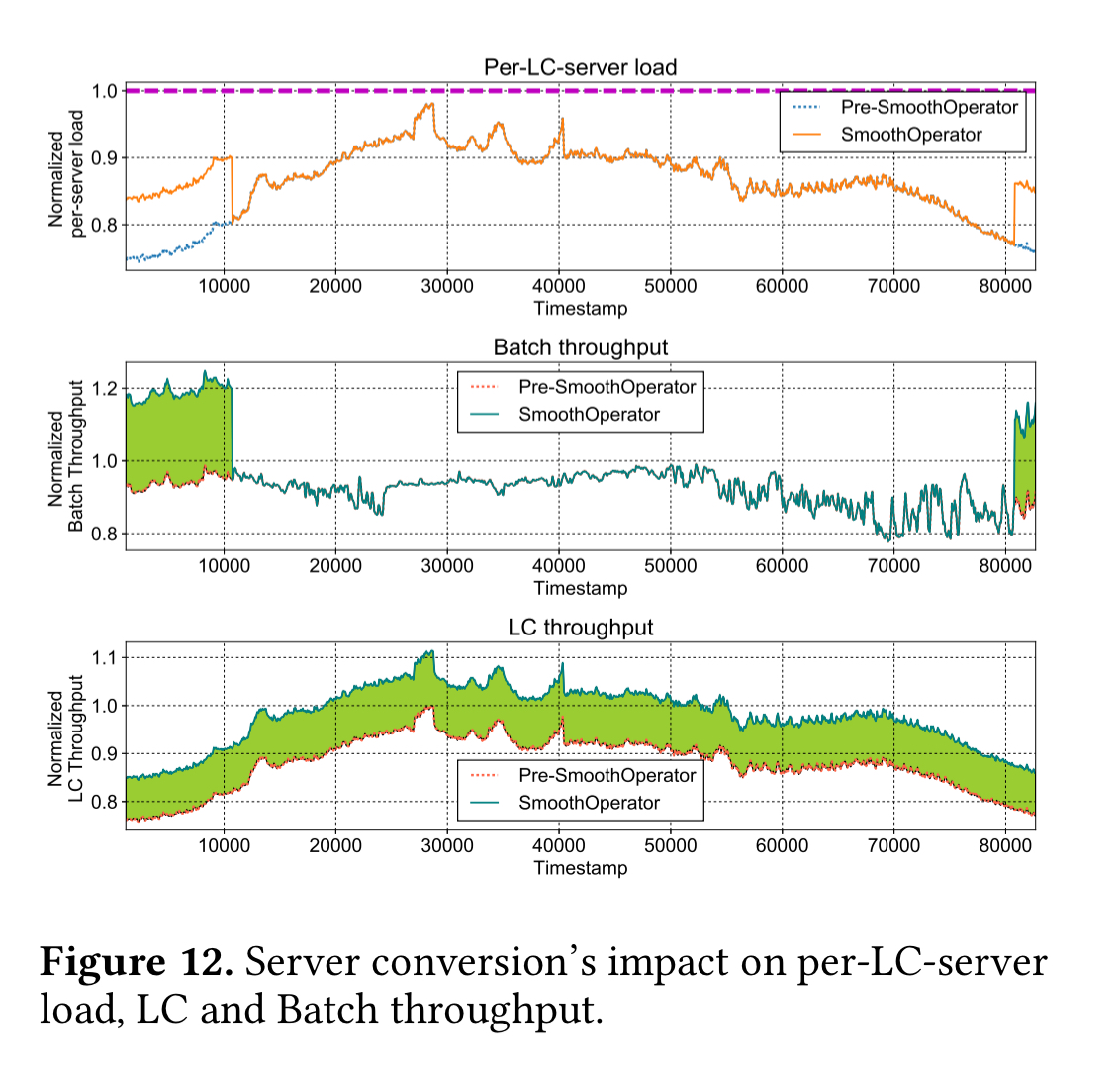
Across the three datacenters, this policy improves latency critical workload throughput by (an additional) 7.2%, 8%, and 1.8% respectively: a capacity gain that can accommodate many millions of extra queries per second.
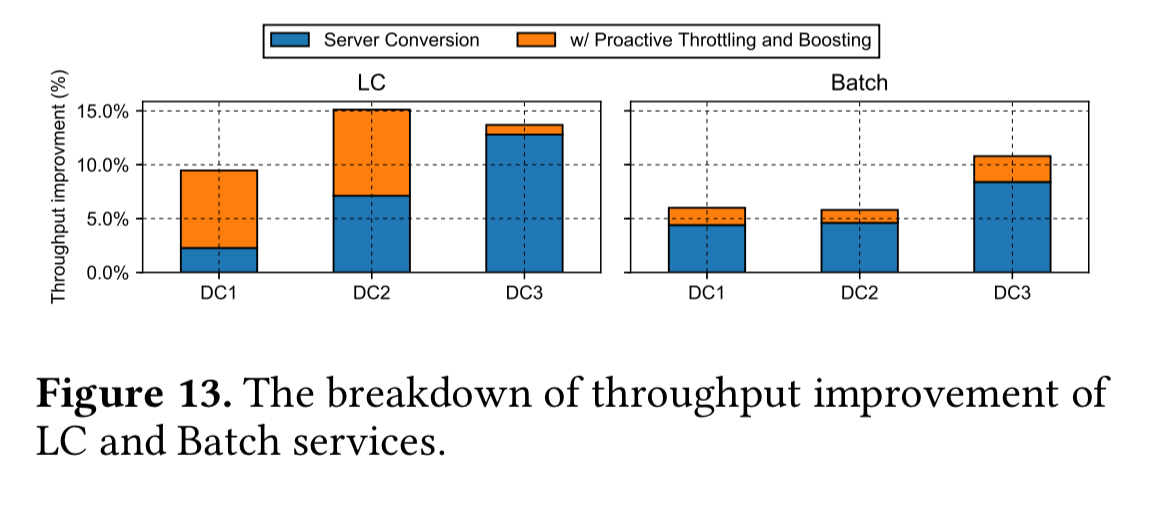
The overall slack measurements give us an indication of improvement at the datacenter level. Datacenter 3 shows the least improvement since it has a heavier skew towards latency critical services (meaning less batch workload is available for balancing).
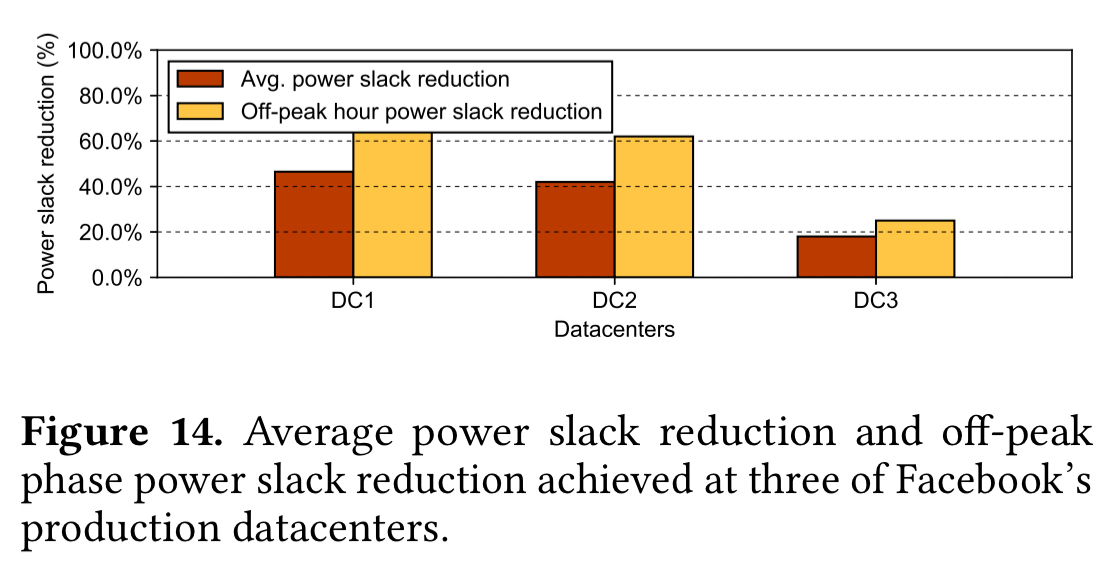
The dynamic power profile reshaping achieves 44%, 41%, and 18% average power slack reduction, respectively in the three datacenters.

{kind=link}