NetChain: Scale-free sub-RTT coordination Jin et al., NSDI’18
NetChain won a best paper award at NSDI 2018 earlier this month. By thinking outside of the box (in this case, the box is the chassis containing the server), Jin et al. have demonstrated how to build a coordination service (think Apache ZooKeeper) with incredibly low latency and high throughput. We’re talking 9.7 microseconds for both reads and writes, with scalability on the order of tens of billions of operations per second. Similarly to KV-Direct that we looked at last year, NetChain achieves this stunning performance by moving the system implementation into the network. Whereas KV-Direct used programmable NICs though, NetChain takes advantage of programmable switches, and can be incrementally deployed in existing datacenters.
We expect a lightning fast coordination system like NetChain can open the door for designing a new generation of distributed systems beyond distributed transactions.
It’s really exciting to watch all of the performance leaps being made by moving compute and storage around (accelerators, taking advantage of storage pockets e.g. processing-in-memory, non-volatile memory, in-network processing, and so on). The sheer processing power we’ll have at our disposal as all of these become mainstream is staggering to think about.
The big idea
Coordination services (e.g. ZooKeeper, Chubby) are used to synchronise access to resources in distributed systems providing services such as configuration management, group membership, distributed locking, and barriers. Because they offer strong consistency guarantees, their usage can become a bottleneck. Today’s server based solutions require multiple RTTs to process a query. Client’s send requests to coordination servers, which execute a consensus protocol (e.g. Paxos), and then send a reply back to the client. The lower bound is one RTT (as achieved by e.g. NOPaxos).
Suppose for a moment we could distributed coordination service state among the network switches instead of using servers, and that we could run the consensus protocol among those switches. Switches process packets pretty damn fast, meaning that the query latency can come down to less than one RTT!

We stress that NetChain is not intended to provide a new theoretical answer to the consensus problem, but rather to provide a systems solution to the problem. Sub-RTT implies that NetChain is able to provide coordination within the network, and thus reduces the query latency to as little as half of an RTT. Clients only experience processing delays caused by their own software stack plus a relatively small network delay. Additionally, as merchant switch ASICs can process several billion packets per second (bpps), NetChain achieves orders of magnitude higher throughput, and scales out by partitioning data across multiple switches…
Modern programmable switch ASICs provide on-chip storage for user-defined data that can be read and modified for each packet at line rate. Commodity switches have tens of megabytes of on-chip SRAM. Datacenter networks don’t use of all this, and so a large proportion can be allocated to NetChain. A datacenter with 100 switches, allocating 10MB per switch, can store 1GB in total, or 333MB effective storage with a replication factor of three. That’s enough for around 10 million concurrent locks for example. With distributed transactions that take 100 µs, NetChain could provide 100 billion locks per second – which should be enough for a while at least! Even just three switches would accommodate 0.3 million concurrent locks, or about 3 billion locks per second. There’s a limitation on individual value sizes of about 192 bytes though for full speed.
We suggest that NetChain is best suited for small values that need frequent access, such as configuration parameters, barriers, and locks.
Consistent hashing is used to partition the key-value store over multiple switches.
In-Network processing + Chain replication = NetChain
So we’ve convinced ourselves that there’s enough in-switch storage to potentially build an interesting coordination system using programmable switches. But how do we achieve strong consistency and fault-tolerance?
Vertical Paxos divides the consensus protocol into two parts; a steady state protocol, and a reconfiguration protocol. These two parts can be naturally mapped to the network data and control planes respectively. Both read and write requests are therefore processed directly in the switch data plane without controller involvement. The controller handles system reconfigurations such as switch failures, and doesn’t need to be as fast because these are comparatively rare events.
For the steady state protocol, NetChain using a variant of chain replication. Switches are organised in a chain structure with read queries handled by the tail and write queries sent to the head, processed by each node along the chain, and replied to at the tail.
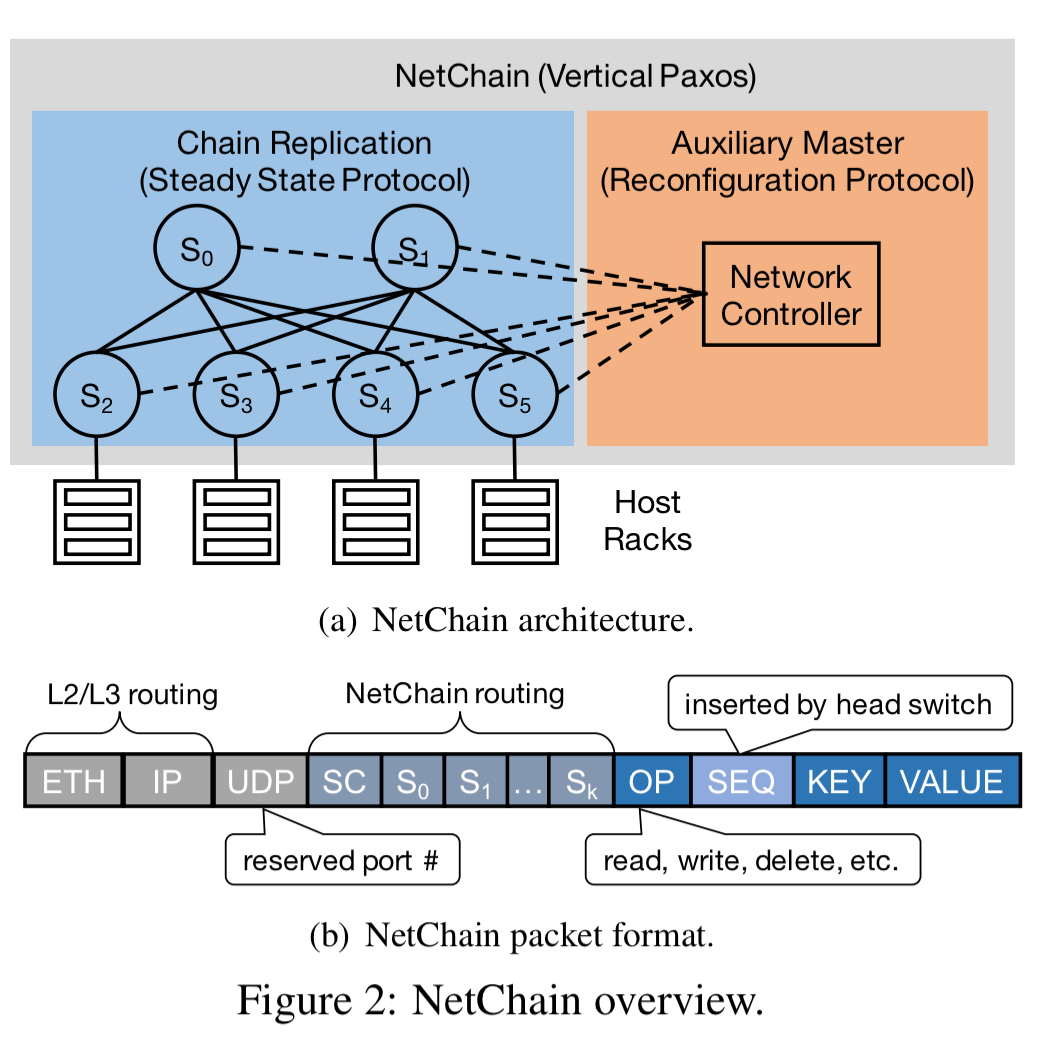
Queries are routed according to the chain structure, building on top of existing underlay routing protocols. Each switch is given an IP address, and an IP list of chain nodes is stored in the packet header. The destination node in the IP header indicates the next chain node. When a switch receives a packet and the destination IP matches its own address, it decodes the query and performs the read or write operation. Then it updates the destination node to the next chain node, or to to the client IP if it is the tail.
Write queries store chain IP lists as the chain order from head to tail; read queries use the reverse order (switch IPs other than the tail are used for failure handling…). The chain IP lists are encoded to UDP payloads by NetChain agents. As we use consistent hashing, a NetChain agent only needs to store a small amount of data to maintain the mapping from keys to switch chains.
Because UDP packets can arrive out of order, NeChain introduces its own sequence numbers to serialize write queries.
The end solution offers per-key read and write queries, rather than per-object. NetChain does not support multi-key transactions.
Handling failures and configuration changes in the control plane
The NetChain controller runs as a component in the network controller. Switch failures are handled in two stages. Fast failover quickly reconfigures the network to resume serving queries with the remaining nodes in each affected chain. This degraded mode can now tolerate one less failure than the original of course. Failure recovery then adds other switches as new replication nodes for the affected chains, restoring their full fault tolerance.
Fast failover is pretty simple. You just need to modify the ‘next’ pointer of the node before the failed one to skip that node:
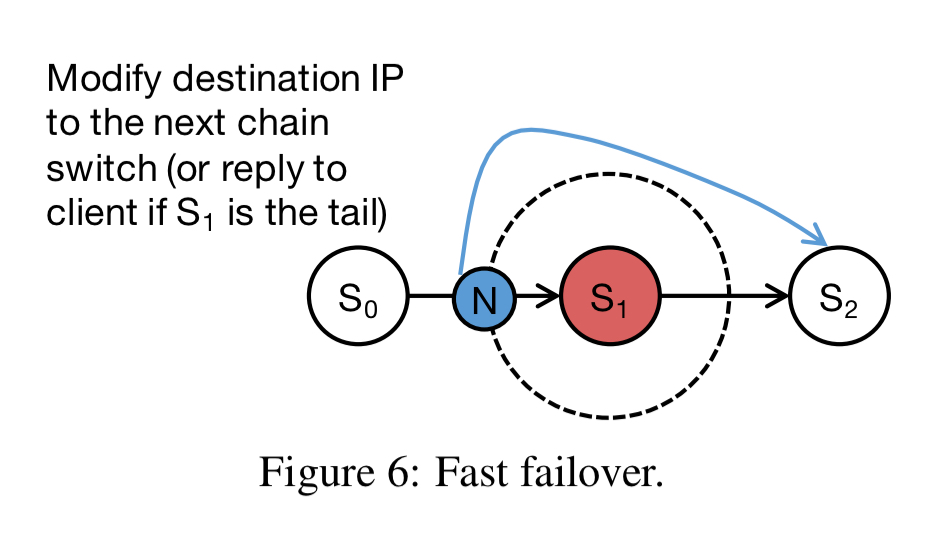
This is implemented with a rule in the neighbour switches of the failed switch, which checks the destination IP. If it is the IP of a failed switch, then the destination IP is replaced with the next chain hop after the failed switch, or the client IP if we’re at the tail.
For failure recovery, imagine a failed switch mapped to k virtual nodes. These are randomly assigned to k live switches, helping to spread the load of failure recovery. Since each virtual node belongs to f+1 chains, it nows needs to be patched into each of them, which is again done by adjusting chain pointers. In the following figure, fast failover has added the blue line from N to S2, and then failure recovery patches in the orange lines to and from S3.
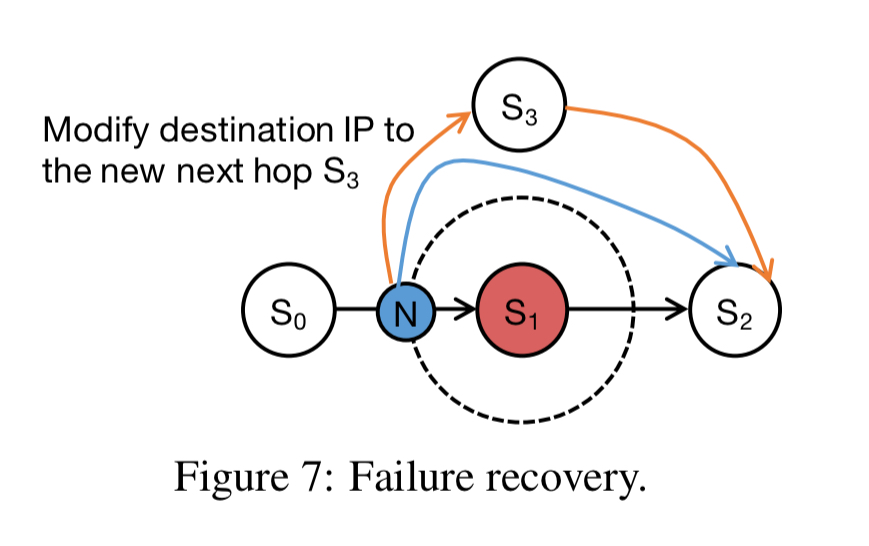
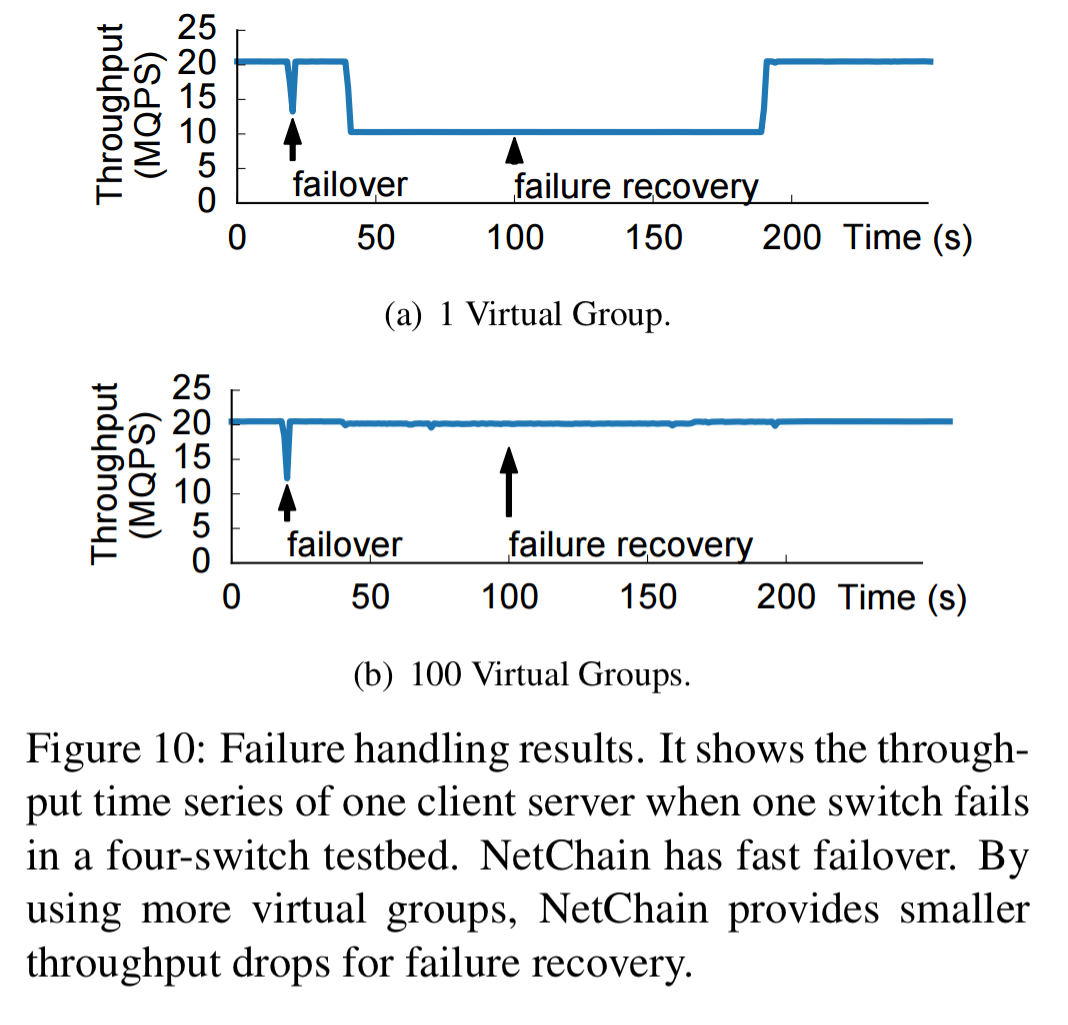
Before splicing in the new node, the state is first copied to it. This can be time-consuming, but availability is not affected. The switch to add the new node is done using a two-phase atomic protocol once the state is in place. To further minimise service disruptions, switches are mapped to multiple virtual groups (e.g. 100), with each group available for 99% of recovery time and only queries to one group at a time affected (paused) by the switchover protocol.
Incremental adoption and hybrid deployments
NetChain is compatible with existing routing protocols and network services and therefore can be incrementally deployed. It only needs to be deployed on a few switches initially to be effective, and then its throughput and storage capacity can be expanded by adding more switches.
NetChain offers lower level services (no multi-key transactions) and reduced per-key storage compared to full-blown coordination services. For some use cases this won’t be a problem (e.g., managing large numbers of distributed locks). In other cases, you could use NetChain as an accelerator to server-based solutions such as Chubby or ZooKeeper, with NetChain used to store hot keys with small value sizes, while traditional servers store big and less popular data .
Evaluation
The testbed consists of four 6.5 Tbps Barefoot Tofino switches and four 16-core server machines with 128GB memory. NetChain is compared against Apache Zookeeper.
The comparison is slightly unfair; NetChain does not provide all features of ZooKeeper, and ZooKeeper is a production-quality system that compromises its performance for many software-engineering objectives. But at a high level, the comparison uses ZooKeeper as a reference for server-based solutions to demonstrate the performance advantages of NetChain.
In all the charts that follow, pay attention to the breaks in the y-axis and/or the use of log scales.
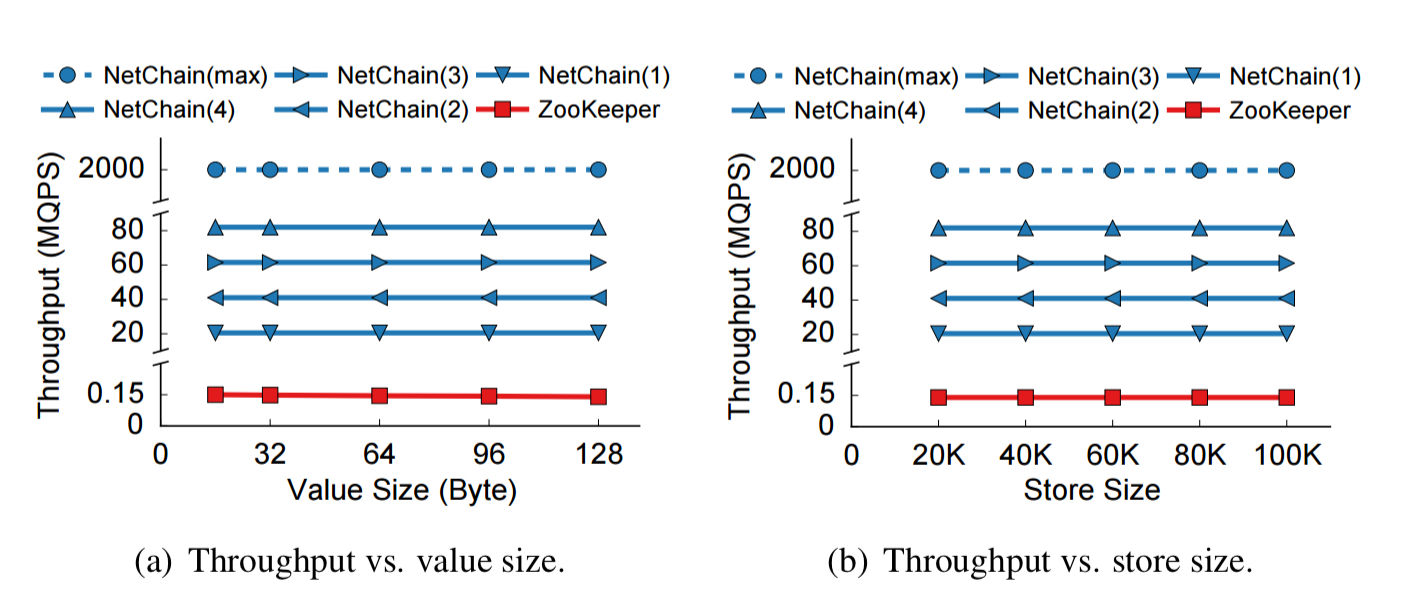
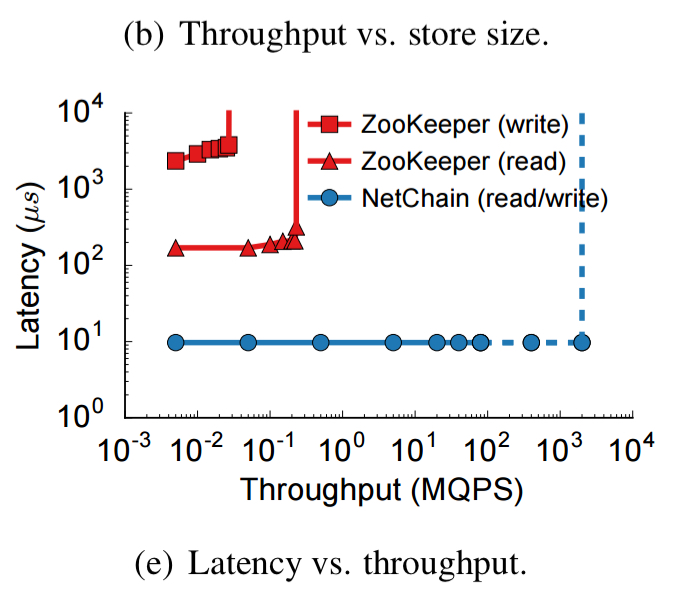
NetChain provides orders of magnitude higher throughput than ZooKeeper, and neither system is affected by value size (in the 0-128 byte range at least) or store size:
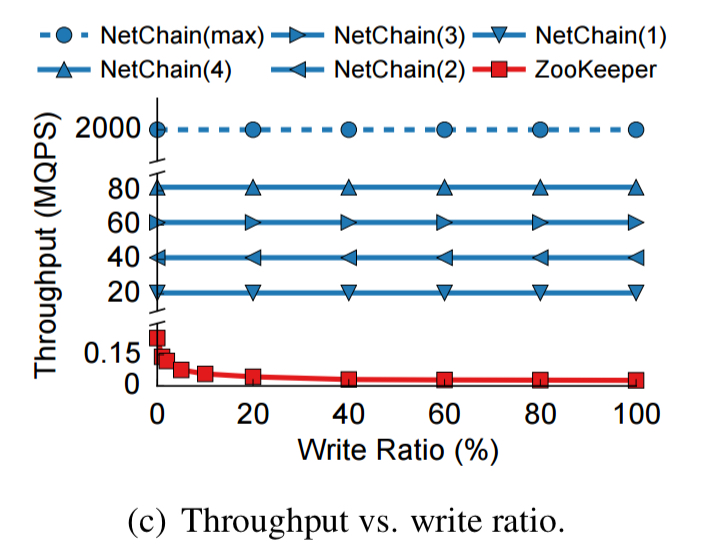
As the write ratio goes up, NetChain keeps on delivering maximum throughput, whereas ZooKeeper’s performance starts to drop off. (At 100% write ratio, ZooKeeper is doing 27 KQPS, while NetChain is still delivering 82 MQPS – each test server can send and receive queries at up to 20.5 MQPS, and there are four of them).
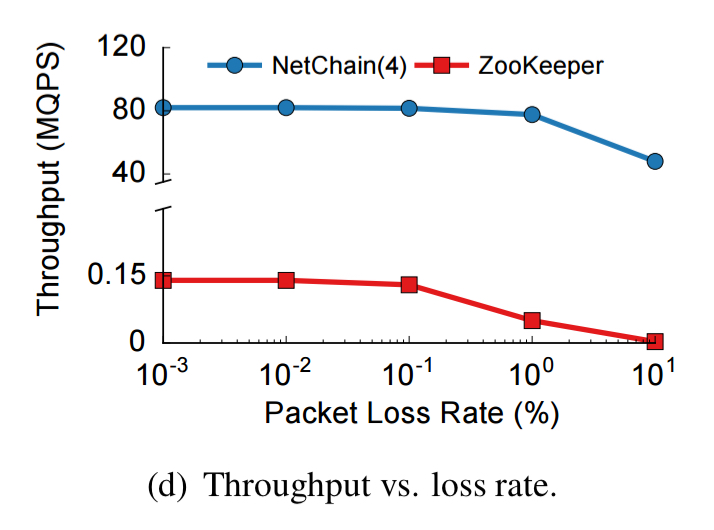
NetChain is also more tolerant of packet loss:
NetChain has the same latency for both reads and writes, at 9.7 µs query latency, and this stays constant even when all four servers are generating queries at their maximum rate. The system will saturate at around 2 BQPS. ZooKeeper meanwhile has 170 µs read latency and 2350 µs write latency at low throughput, the system saturates at 27 KQPS for writes and 230 KQPS for reads.
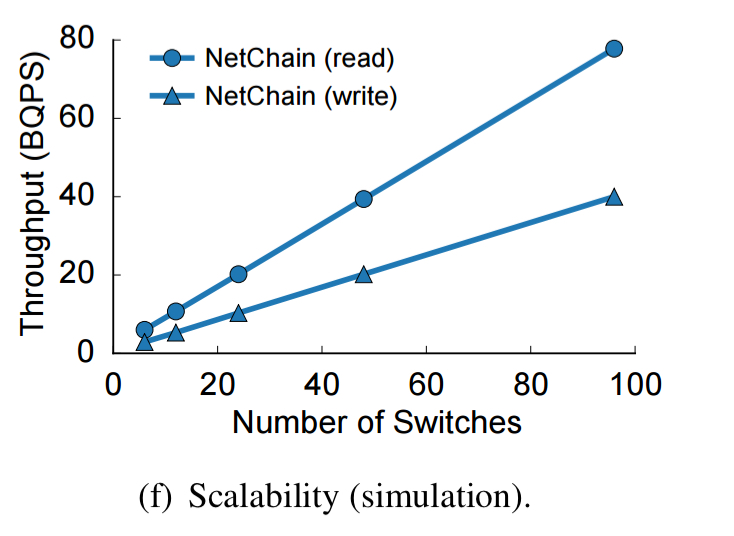
As you add more switches to NetChain, throughput grows linearly.
The following figure shows that using virtual groups successfully mitigates most of the performance impact during failure recovery:
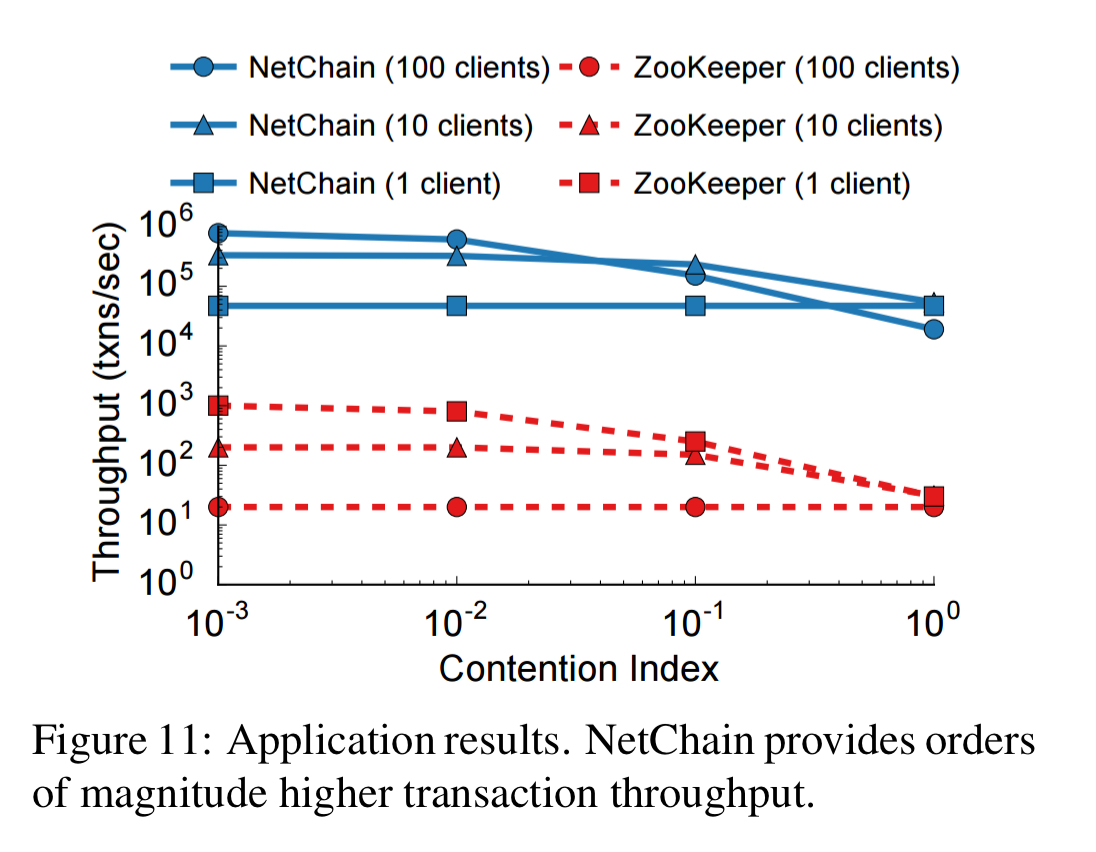
And finally, here’s a TPC-C new order transaction workload which allowing testing transactions under different contention levels. By using NetChain as a lock server, the system can achieve orders of magnitude higher transaction throughput than ZooKeeper.
We believe NetChain exemplifies a new generation of ultra-low latency systems enabled by programmable networks.

I’m thinking that any actor with access to the network could play havoc with NetChain by replaying packets. It seems there would be a multitude of ways to break UDP based protocols that hold state.
I guess I’m asking _how could one secure untrusted transit hosts/networks such that it could be used for network co-ordination_?