Azure accelerated networking: SmartNICs in the public cloud Firestone et al., NSDI’18
We’re still on the ‘beyond CPUs’ theme today, with a great paper from Microsoft detailing their use of FPGAs to accelerate networking in Azure. Microsoft have been doing this since 2015, and hence this paper also serves as a wonderful experience report documenting the thought processes that led to an FPGA-based design, and lessons learned transitioning an all-software team to include hardware components.
There’s another reminder here too of the scale at which cloud vendors operate, which makes doing a project like this viable. The bulk purchase of FPGAs keeps their cost low, and the scale of the project makes the development investment worthwhile.
One question we are often asked is if FPGAs are ready to serve as SmartNICs more broadly outside Microsoft… We’ve observed that necessary tooling, basic IP blocks, and general support have dramatically improved over the last few years. But this would still be a daunting task for a new team… The scale of Azure is large enough to justify the massive development efforts — we achieved a level of performance and efficiency simply not possible with CPUs, and programmability far beyond an ASIC, at a cost that was reasonable because of our volume. But we don’t expect this to be a natural choice for anyone beyond a large-scale cloud vendor until the ecosystem evolves further.
The investment in AccelNet certainly seems to be paying off when it comes to networking performance in Azure. Here’s a comparison of VM-VM throughput, average latency, and tail (P99) latency across Azure, AWS, and GCP:

(Enlarge)
The networking challenge with virtual infrastructure
In traditional virtual machine networking all network I/O to and from a physical device is performed in the host software partition of the hypervisor, with every packet sent and received processed by a virtual switch in the host networking stack. This of course burns a lot of CPU and increases latency.
SR-IOV compliant hardware enables PCI Express (PCIe) device hardware to be shared among multiple VMs. Bypassing the hypervisor makes things go much faster, but it also bypasses all the host SDN policies. That’s a problem because infrastructure-as-a-service platforms have to provide rich network semantics (private virtual networks, software load balancers, virtual routing tables, bandwidth monitoring and so on). In Azure, these features are implemented in the Virtual Filtering Platform (VFP), a cloud-scale programming vSwitch providing scalable SDN policy for Azure.
The challenge is to get performance levels close to SR-IOV, while still delivering the SDN flexibility provided by VFP.
Design goals and constraints
An initial analysis revealed that any solution would need to satisfy the following:
- It shouldn’t consume host CPU cores – the Azure business depends on renting these out to customers, and overheads should be kept to a minimum.
- Retain a high degree of programmability. Offloading every rule to hardware is neither feasible nor desirable. The flexibility of VFP should be maintained without any knowledge that policy is being offloaded.
- Achieve latency, throughput, and utilisation on a par with SR-IOV hardware. (AccelNet achieves this by for all but the very first packet of each flow).
- Support adding and changing actions over time. “We were, and continue to be, very wary of designs that locked us into a fixed set of flow actions.”
- Support frequent deployment of new functionality in the existing hardware fleet, and not just on new servers.
- Provide high single connection performance. A single CPU core generally can’t achieve peak bandwidth performance at 40Gb and higher (and 100Gb is coming!). To get beyond this requires the use of multiple threads, spreading traffic across multiple connections. This would require substantial changes to customer applications. “An explicit goal of AccelNet is to allow applications to achieve near-peak bandwidths without parallelizing the network processing in their application.“
- Have a path that will scale to 100GbE and beyond.
- Support full serviceability with live migration and no loss of flow state. One of the key lessons learned is the entire system, from hardware to software, must be designed to be serviceable and monitorable from day one.
Serviceability cannot be bolted on later.
Evaluating hardware choices
ASICs, multi-core SoCs, or FPGAs?
ASICS
Custom ASIC designs provide the highest performance potential, but they’re harder to program and even harder to adapt over time. With a time lag of 1-2 years between requirement specifications and the arrival of silicon, the hardware was already behind requirements before it arrived. Couple that with a 5 year server lifespan and no easy way to retrofit most servers at scale, and you’re actually looking at a design that has to last for 7 years into the future. That’s like predicting what you need today back in 2011!
So ASICS are out.
Multicore SoC-based NICs
Multicore SoC-based NICs use a sea of embedded CPU cores to process packets, trading some performance to provide substantially better programmability than ASIC designs.
At higher network speeds of 40GbE and above though, the number of required cores increases significantly and scattering and gathering packets becomes increasingly inefficient. “… 40GbE parts with software-based datapaths are already surprisingly large, power hungry, and expensive, and their scalability for 100GbE, 200GbE, and 400GbE looks bleak.”
So multicore SoC-based NICs are out.
FPGAs
FPGAs balance the performance of ASICs with the programmability of SoC NICs.
The key characteristics of FPGAs that made it attractive for AccelNet were the programmability to adapt to new features, the performance and efficiency of customized hardware, and the ability to create deep processing pipelines, which improve single-flow performance.
Note that Microsoft had already been running a multi-thousand node cluster of networked FPGAs doing search ranking for Bing, which improved their confidence in the viability of an FPGA-based design. However,…
… our networking group, who had until then operated entirely as a software group, was initially skeptical— even though FPGAs are widely used in networking in routers, applications, and appliances they were not commonly used as NICs or in datacenter servers, and the team didn’t have significant experience programming or using FGPAs in production settings.
Dedicated FPGA developers were added to the team, but not many— fewer than 5 at any given time.
AccelNet in brief
AccelNet places the FPGA as a bump-in-the-wire between the NIC and the Top of Rack (TOR) switch, making it a filter on the network. The FPGA is also connected by 2 PCIe connections to the CPUs, so that it can be used for accelerator workloads like AI and web search. Below you can see pictures of (a) the first, and (b) the second generation of AccelNet boards.

(Enlarge)
The control plane is largely unchanged from the original VFP design and runs almost entirely in the hypervisor. The Generic Flow Table based datapath design is implemented in hardware. There are two deeply pipelined packet processing units, each with four major pipeline stages:
- A store and forward packet buffer
- A parser
- A flow lookup and match
- A flow action
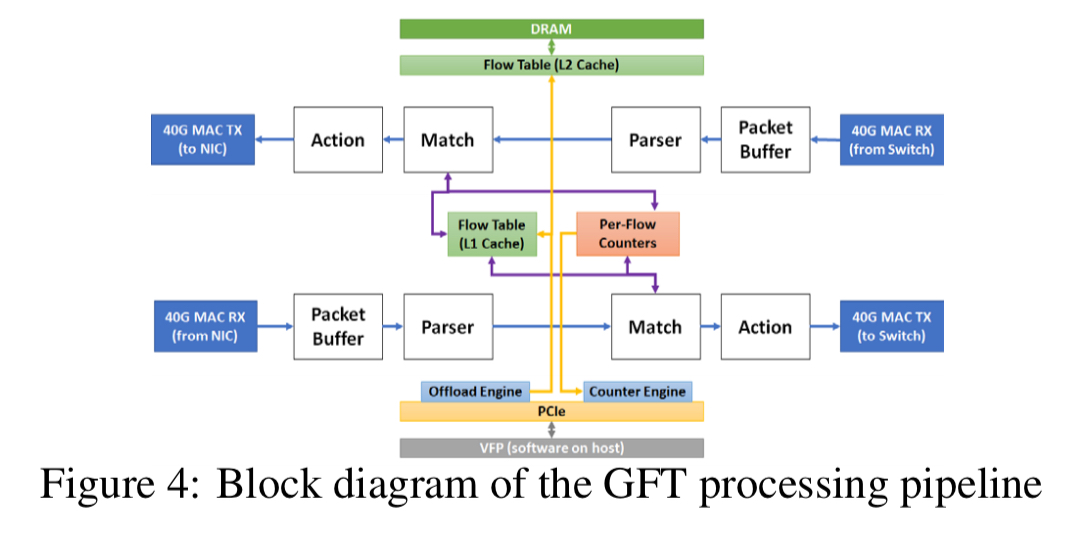
Serviceability
A key design goal is that TCP flows and vNICs should survive FGPA reconfiguration, FPGA driver updates, NIC PF driver updates , and Generic Flow Table updates. This is achieved via an intermediary (failsafe) Poll Mode Driver (PMD) which can bind to either the accelerated data path or the host software stack. When the hardware needs to be updated the failsafe driver switches to the VMBUS channels and the application sees no interruption bar reduced performance for a period of time.
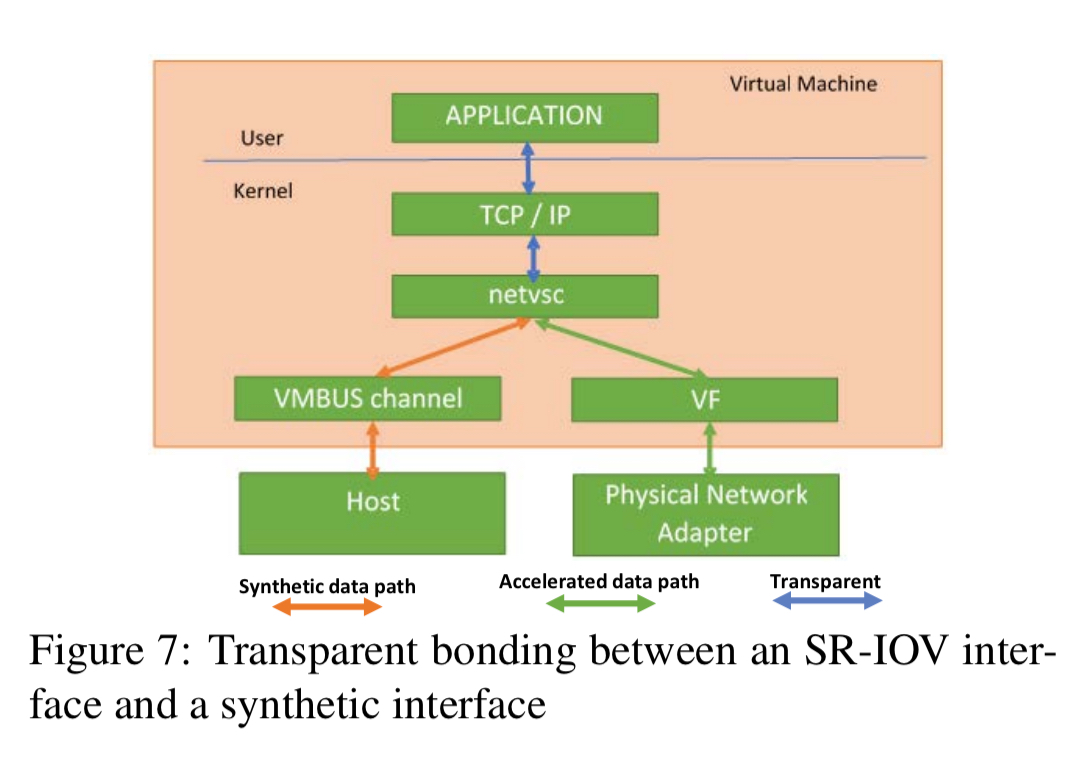
Lessons learned
I raced through the description of AccelNet’s design, so that we could spend some time and space on lessons learned from the project, which are of interest beyond just this particular project.
- Design for serviceability upfront. This was the hardest part to get right and required the whole system including hardware and software to be designed to be serviceable and monitorable from day one.
- Use a unified development team. “If you want hardware/software co-design, hardware devs should be in the same team as software devs.“
- Use software development techniques for FPGAs – treat and ship hardware logic as if it were software.
- Better performance leads to better reliability. By separating the network datapath such that it no longer shares cores or resources with the host, not only does it perform better, but many sources of interference are eliminated leading to greater reliability.
- Hardware/software design is best when iterative. ASICs force a waterfall like approach, but with FPGAs hardware developers could be far more agile in their approach.
- Failure rates remained low, with FPGAs proving reliable in datacenters worldwide (DRAM failed the most by the way).
- Upper layers should be agnostic of offloads. The offload acceleration was transparent to controllers and upper layers, making AccelNet much less disruptive to deploy.
- As a nice bonus, “because AccelNet bypasses the host and CPUs entirely, our AccelNet customers saw significantly less impact to network performance, and many redeployed older tenants to AccelNet-capable hardware just to avoid these impacts.“
Future work will describe entirely new functionality we’ve found we can support now that we have programmable NICs on every host.

{kind=link}
{kind=link}
Hi Adrian, great blog, reading daily!
Coincidentally I posted a detailed review of SmartNICs that might help understand the technology trends: https://www.sigarch.org/the-new-life-of-smartnics
That’s a really helpful piece, thank you!
“”” Future work will describe entirely new functionality we’ve found we can support now that we have programmable NICs on every host. “””
My guess: Hardware support for some type of cluster synchronization primitives.