Andromeda: performance, isolation, and velocity at scale in cloud network virtualization Dalton et al., NSDI’18
Yesterday we took a look at the Microsoft Azure networking stack, today it’s the turn of the Google Cloud Platform. (It’s a very handy coincidence to have two such experience and system design report papers appearing side by side so that we can compare). Andromeda has similar design goals to AccelNet: performance close to hardware, serviceability, and the flexibility and velocity of a software-based architecture. The Google team solve those challenges in a very different way though, being prepared to make use of host cores (which you’ll recall the Azure team wanted to avoid).
We opted for a high-performance software-based architecture instead of a hardware-only solution like SR-IOV because software enables flexible, high-velocity feature deployment… Andromeda consumes a few percent of the CPU and memory on-host. One physical CPU core is reserved for the Andromeda dataplane… In the future, we plan to increase the dataplane CPU reservation to two physical cores on newer hosts with faster physical NICs and more CPU cores in order to improve VM network throughput.
High-level design
Both the control plane and data plane use a hierarchical structure. The control plane maintains information about every VM in the network, together with all higher-level product and infrastructure state such as firewalls, load-balancers, and routing policy. It is designed around a global hierarchy in conjunction with the overall cloud cluster management layer.
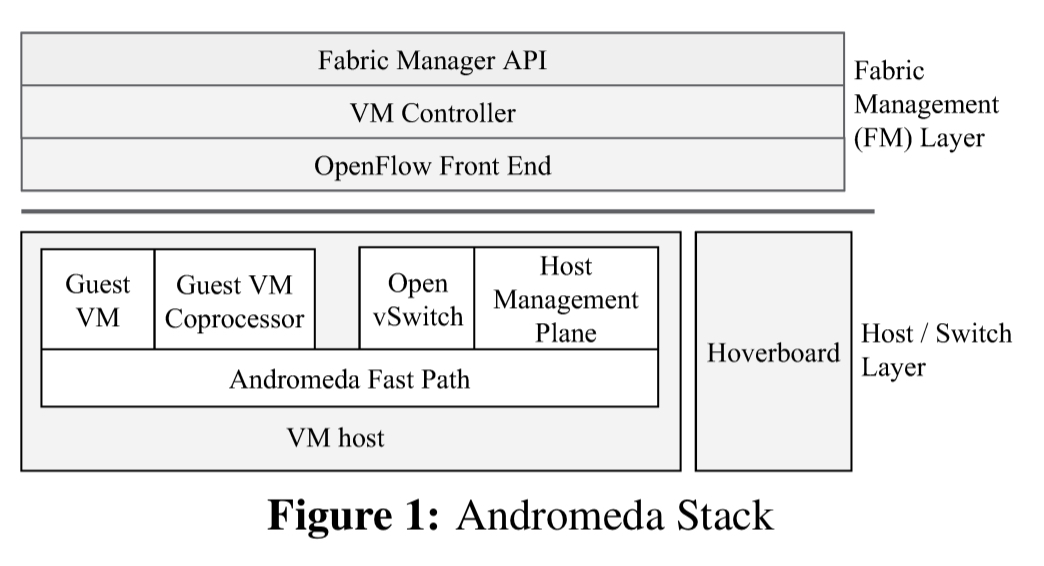
The data plane offers a set of flexible user-space packet processing paths:
- High-performance, latency critical flows are processed end-to-end on a fast path with a per-packed budget of 300ns.
- On-host software coprocessors running in per-VM floating threads perform per-packet work that is CPU-intensive or without strict latency targets. Coprocessors allow feature growth without compromising the fast path.
- Packets that don’t match a flow rule on the VM host are sent to hoverboards: dedicated gateways that perform virtual network routing. Only active flows are installed on VM hosts based on current communication patterns, this allows the long tail of mostly idle flows to be processed by hoverboards.
Avoiding the need to install full-forwarding information on every host improves per-server memory utilization and control-plane scalability by over an order of magnitude.
The control plane
The control plane is made up of three layers. The uppermost layer, cluster-management, provisions resources on behalf of users. It’s functionality is not networking-specific. When the cluster management layer needs to configure virtual networks, it uses the fabric management layer services to do so. VM Controllers (VMCs) within the fabric layer program switches using a convergence model to bring switches in line with the desired state. At the bottom of the stack we find the switch layer dealing with on-host switches and hoverboards. Each VM host has a virtual switch based on Open vSwitch which handles all traffic all for VMs on the host. Hoverboards are standalone switches.
Multiple VMCs partitions are deployed in every cluster, with each partition responsible for a fraction of the cluster hosts based consistent hashing. Each VMC partition consists of a Chubby-elected master (an interesting use case for an in-switch coordination service such as NetChain? ) and two standbys. The overall control plane is split into a regionally aware control plane (RACP) and a globally aware control plane (GACP). This helps provide fault isolation barriers to prevent problems cascading across regions.
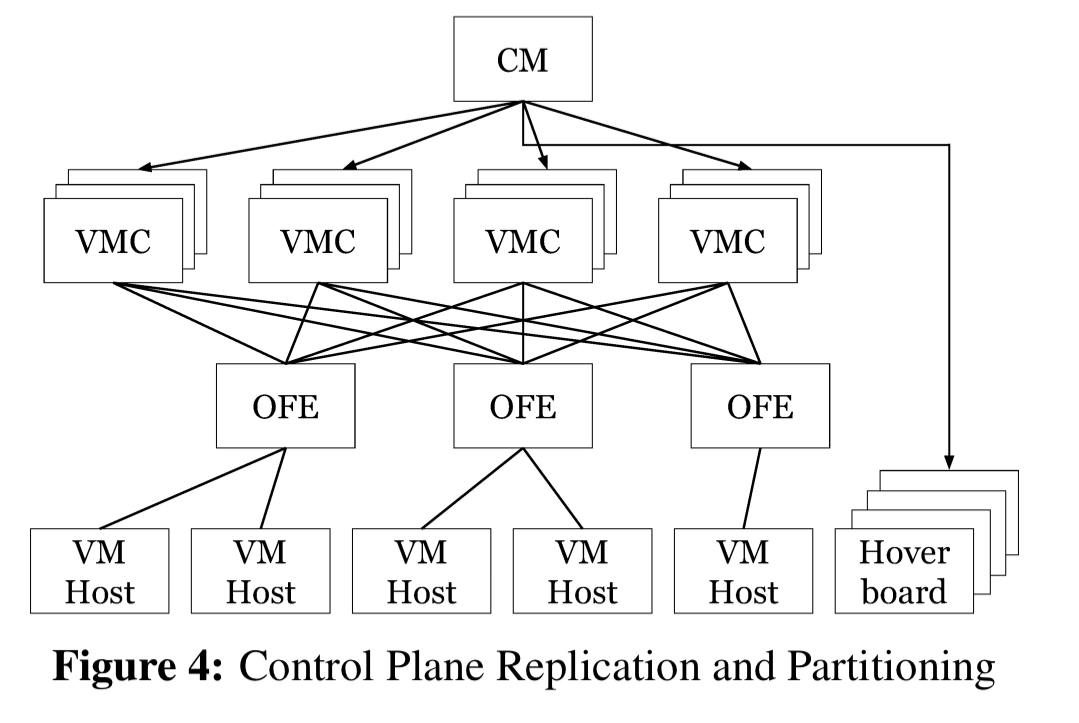
Every layer of the control plane is designed to fail static. For example, hosts continue to forward packets using the last-known-good programming state, even if VMCs are unavailable. Hosts checkpoint their state to allow them to preserve the fail static behavior across host process restarts, and we routinely test fail-static behavior by simulating outages in a test environment.
Andromeda supports migration across clusters with no packet loss. This use case was one of the key factors in avoiding the use of hardware-only SR-IOV-based solutions.
The control layer needs to scale to millions of individual VMs with fast reconfiguration. There are three basic approaches to programming SDNs:
- In the pre-programmed model, the control plane programs a full mesh of programming rules from each VM to every other VM. This of course scales quadratically with network size and require mass propagation of state on network changes. It’s not going to work well at Google scale.
- In the on-demand model, the first packet of a flow is sent to the controller, which then programs the required forwarding rule. It means that the first packet has high latency, is very sensitive to control plane outages, and opens the door to accidental or malicious DoS attacks on the control plane. Rate limiting across tenants in this scenario is complex.
- In the gateway model, all packets of a specific type (e.g., destined for the Internet) are sent to a gateway device. This provides predictable performance and control plane scalability, but can lead to a large number of gateways.
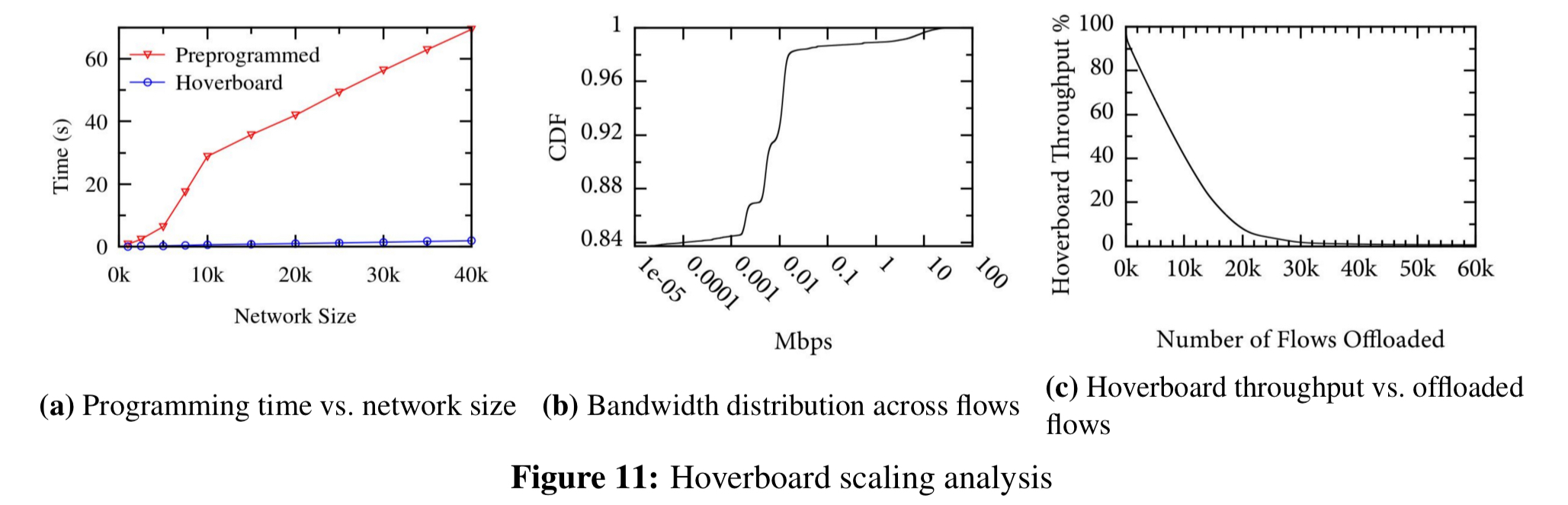
Andromeda’s hoverboard model is designed to combine the benefits of the on-demand and gateway approaches. Initially all packets for which the VM host stack does not have a route are sent to Hoverboard gateways. The controller detects flows that exceed a specified usage threshold and programs offload flows for them: direct host-to-host flows bypassing the hoverboards. Since the distribution of flow bandwidth tends to be highly skewed, a small number of offload flows divert the vast majority of traffic in the cluster away from the hoverboards.
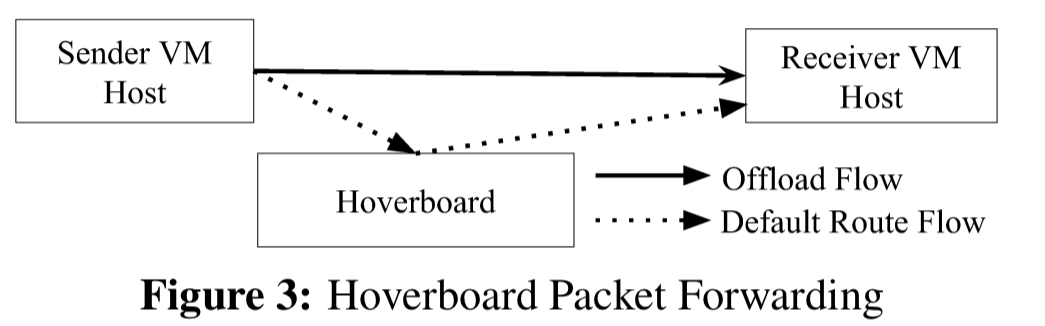
The data plane
The VM host dataplane is a userspace process that performs all on-host VM packet processing, combining both virtual NIC and virtual switch functionality… Our overall dataplane design philosophy is flexible, high-performance software coupled with hardware offloads. A high performance software dataplane can provide performance indistinguishable from the underlying hardware.
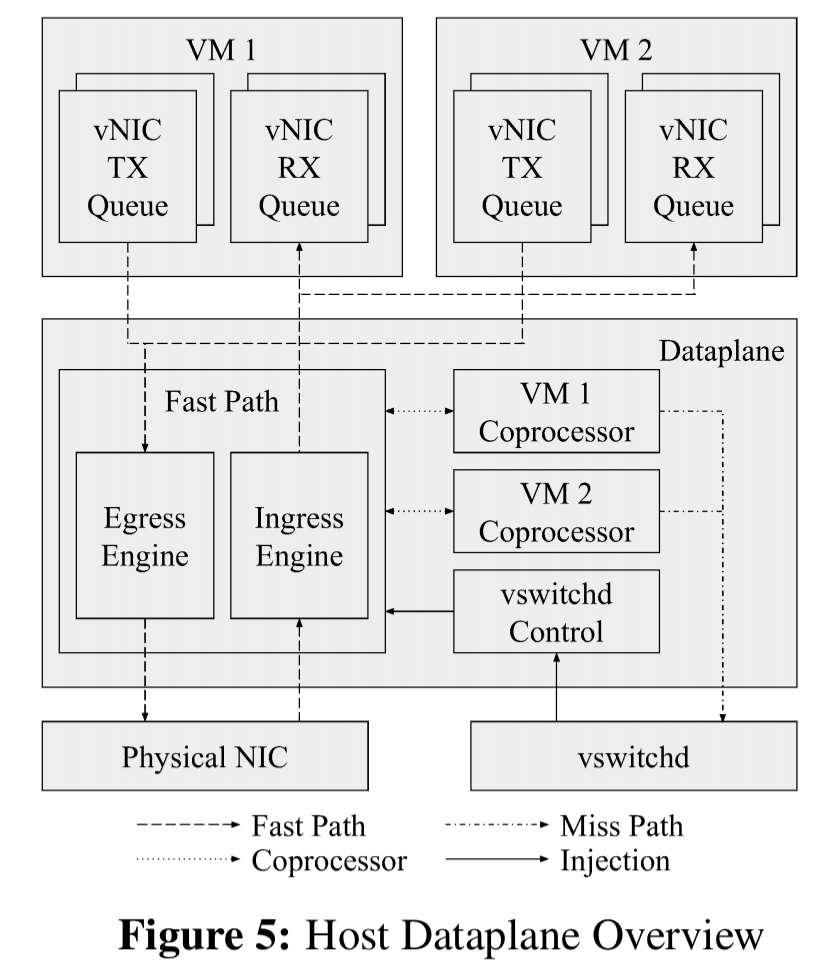
Sufficient fast-path CPU is provisioned to meet throughput targets. Encryption, checksums, and memory copies (using Intel QuickData DMA Engines) are offloaded to hardware. Only performance critical low-latency work runs on the fast-path, everything else belongs on the co-processor path. The fast path avoids locks and synchronisation, carefully optimises memory locality, uses hugepages, avoids thread handoffs and system calls, and uses end-to-end batching. Developing co-processor features is easier because they don’t have to strictly follow all of these practices: for example, they may acquire locks, allocate memory, and perform system calls.
To ensure middlebox functionality does not degrade fast path performance the control plane pre-computes any per-flow middlebox packet stage work as part of installing a flow. For example, Google use an always-on connection tracking firewall. To minimise per-flow work the firewall rules are examined on a flow miss. If the IP addresses and protocol in the flow are always allowed in both directions, then no firewall work is needed in the fast path. Otherwise a flow firewall policy is pre-computed (indicating allowed port ranges for the flow IPs), and the fast path just matches packets against these port ranges, which is much faster than evaluating the full firewall policy.
Fast path flow table lookup is used to determine the coprocessor stages that are enabled for a packet. If coprocessor stages are enabled, the packet is sent to the appropriate coprocessor thread via an SPSC (single-producer, single-consumer) packet ring.
Performance
Andromeda has evolved over a five-year period, enabling us to see the impact of various design changes that were made during this period.
- Pre-Andromeda the dataplane was implemented entirely in the VMM using UDP sockets for packet I/O.
- Andromeda 1.0 included an optimised VMM packet pipeline and a modified kernel Open vSwitch.
- Andromeda 1.5 added ingress virtual NIC offloads and coalesced redundant lookups in the VMM with the kernel OVS flow table lookup.
- Andromeda 2.0 consolidate prior VMM and host kernel packet processing into a new OS-bypass busy-polling userspace dataplane.
- Andromeda 2.1 directly accesses virtual NIC rings in the dataplane, bypassing the VMM.
- Andromeda 2.2 uses Intel QuickData DMA Engines to offload larger packet copies.
The following charts show the impact of these changes on throughput and latency:
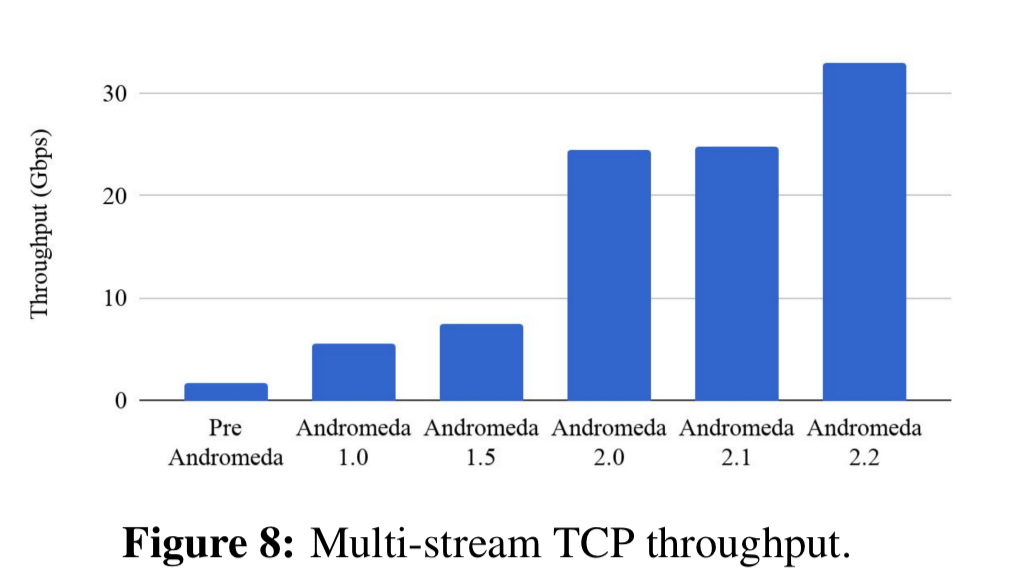
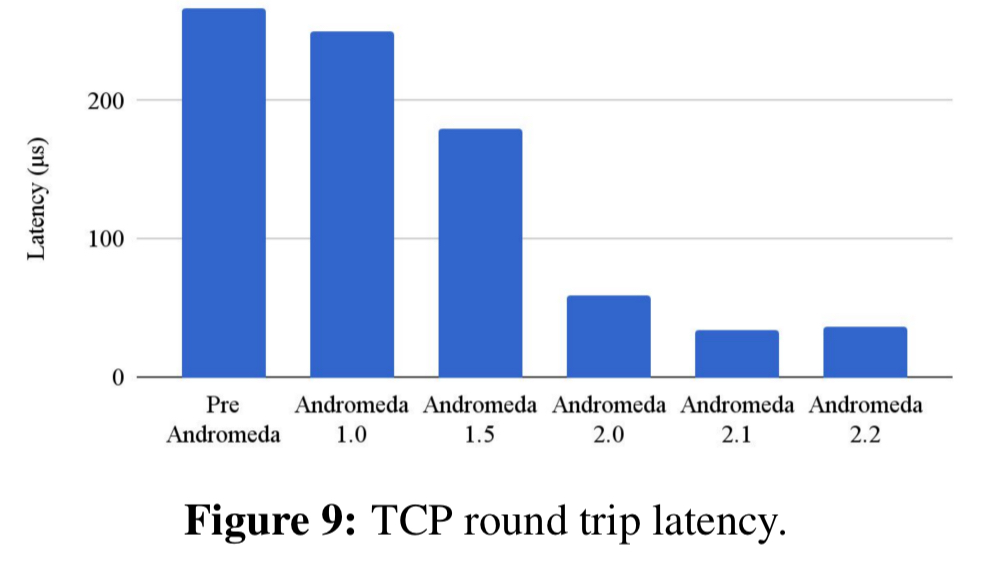
You can also see the reducing demands on the CPU with increasing offloads:
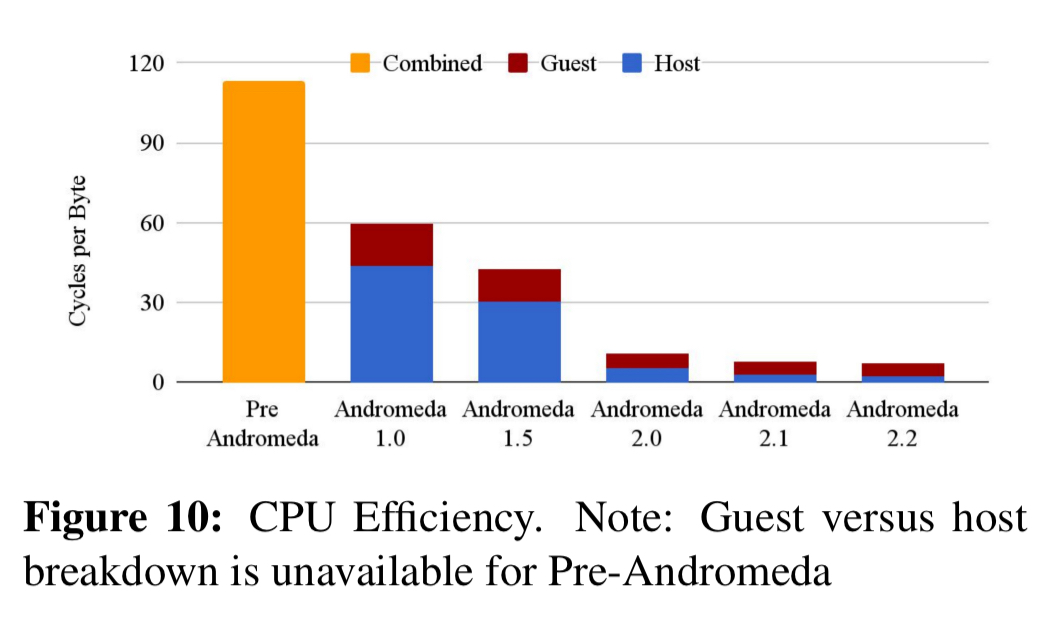
In the control plane, using the original pre-programming approach, it was not possible to get beyond about 40K VMs. At this level, VMCs are programming 487M flows in 74 seconds, using 10GB RAM per partition. With the introduction of hoverboards only 1.5M flows need to programmed, which can be done in 1.9 seconds with 513MB RAM per partition.
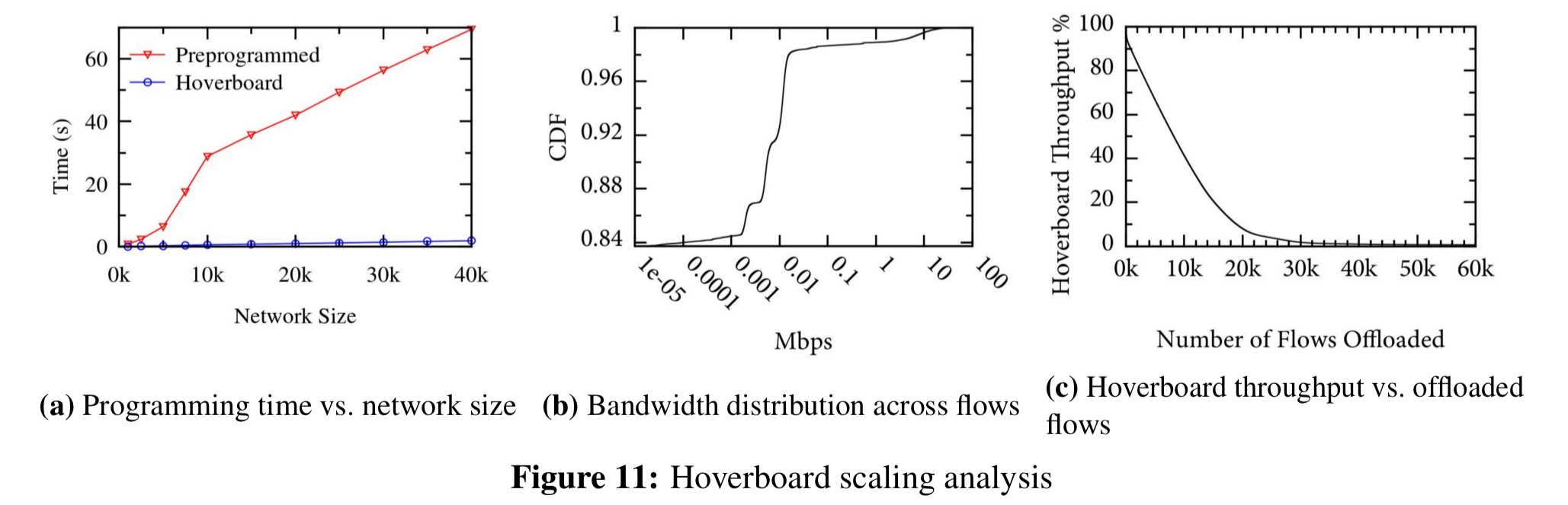
(Enlarge)
In the future, we will offload more substantial portions of the Fast Path to hardware. We will continue to improve scalability, as lightweight virtual network endpoints such as containers will result in much larger and more dynamic virtual networks.

{kind=link}
Reblogged this on Julian Frank's Blog and commented:
Want to know how GCP (Google Cloud Platform) Does their Virtual Networking to achieve 30Gbps … Read this article on Adrian Colyer’s blog
Nicely done. One item that is unclear (to me, at least) from both this and original Article, is this: different Tenants will each want to use their own addresses. Two Tenants might easily choose the same IP address subnet (e.g. 10.10.x.y). so – There is a need to either tunnel the Tenant’s IP addresses in Google’s, or to translate Tenant-to-Google (and then you need to have the suitable translation table on each host)
Have I missed it and they DO explain how this is done?