KV-Direct: High-performance in-memory key-value store with programmable NIC Li et al., SOSP’17
We’ve seen some pretty impressive in-memory datastores in past editions of The Morning Paper, including FaRM, RAMCloud, and DrTM. But nothing that compares with KV-Direct:
With 10 programmable NIC cards in a commodity server, we achieve 1.22 billion KV operations per second, which is almost an order-of-magnitude improvement over existing systems, setting a new milestone for a general-purpose in-memory key-value store.
Check out the bottom line in this comparison table from the evaluation:
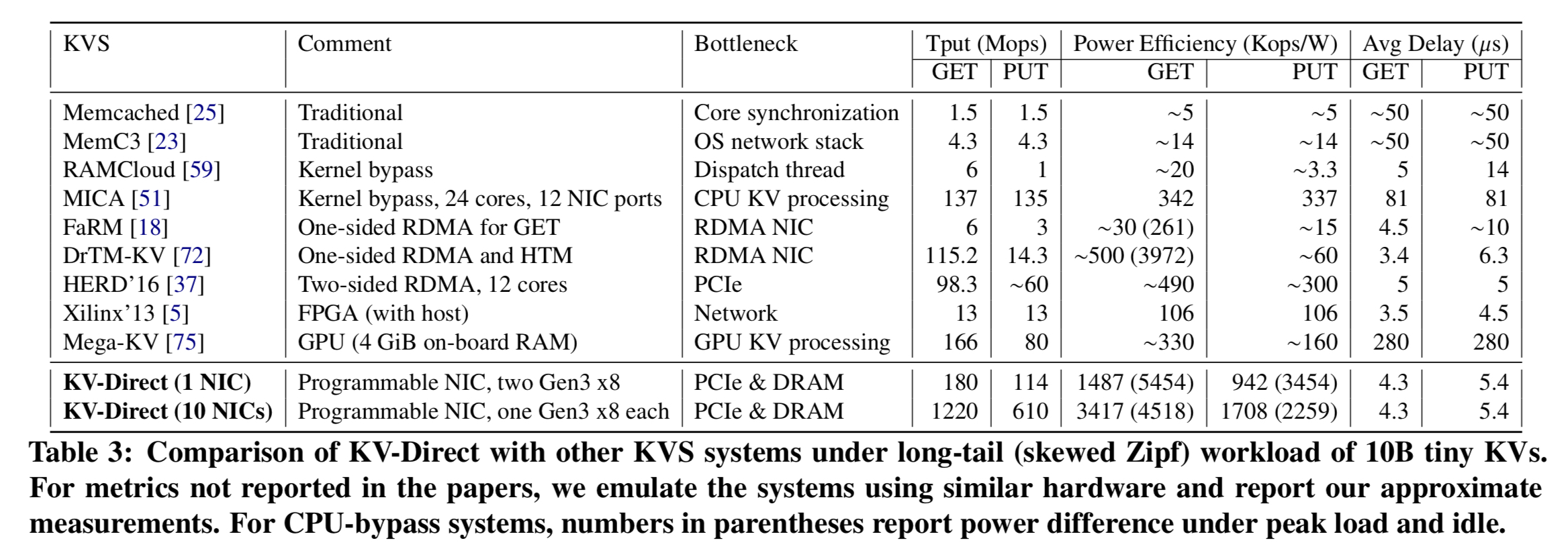
(Enlarge)
In addition to sheer speed, you might also notice that KV-Direct is 3x more power efficient than other systems, and the first general purpose KVS system to achieve 1 million KV operations per watt on commodity servers. Since the server CPU can also be used to run other workloads at the same time, you can make a case for KV-Direct being as much as 10x more power efficient than CPU-based systems.
What we’re seeing here is a glimpse of how large-scale systems software of the future may well be constructed. As the power ceiling puts a limit on multi-core scaling, people are now turning to domain-specific architectures for better performance.
A first generation of key-value stores were built in a straightforward manner on top of traditional operating systems and TCP/IP stacks.
More recently, as both the single core frequency scaling and multi-core architecture scaling are slowing down, a new research trend in distributed systems is to leverage Remote Direct Memory Access (RDMA) technology on NIC to reduce network processing cost.
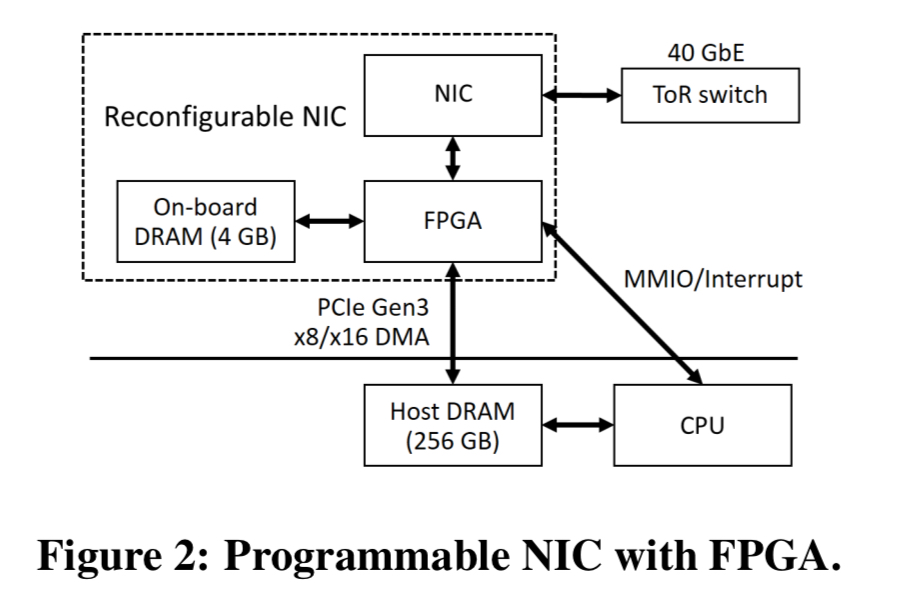
KV-Direct however, goes one step beyond. To support network virtualisation, more and more servers in data centers are now equipped with programmable NICS containing field-programmable gate arrays (FPGA). An embedded NIC chip connects to the network, and a PCIe connector attaches to the server. KV-Direct uses the FPGA in the NIC to implement key-value primitives directly.
Like one-sided RDMA (Fig 1b below), KV-Direct bypasses the remote CPU. But it also extends the RDMA primitives from simple memory operations (READ and WRITE) to key-value operations (GET, PUT, DELETE and ATOMIC ops) — Fig 1c below.
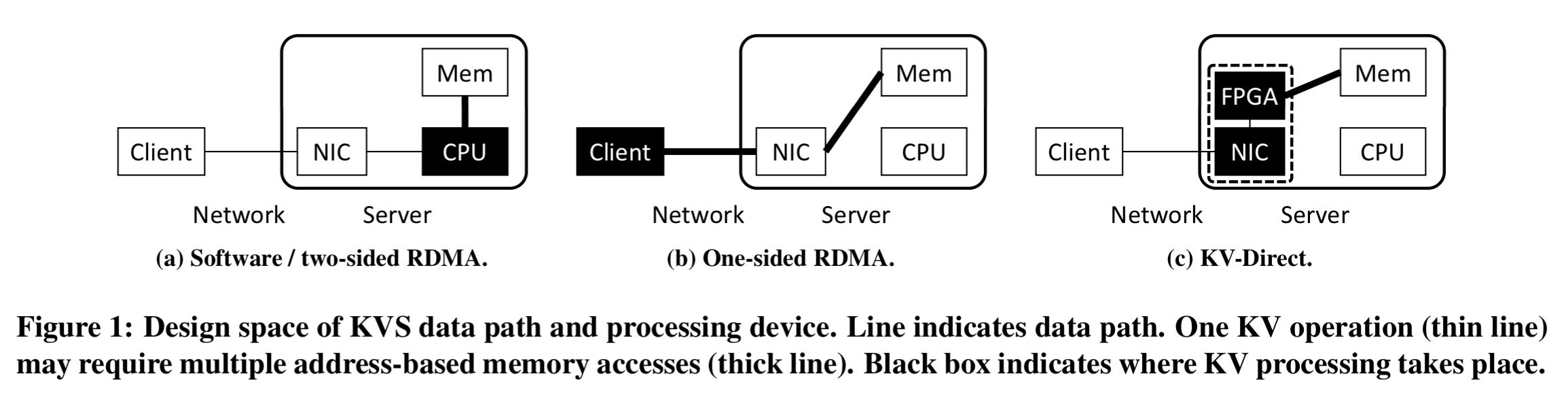
Compared with one-sided RDMA based systems, KV-Direct deals with the consistency and synchronization issues on the server-side, thus removing computation overhead in the client, and reducing network traffic. In addition, to support vector-based operations and reduce network traffic, KV-Direct also provides new vector primitives UPDATE, REDUCE, and FILTER, allowing users to define active messages and delegate certain computations to programmable NIC for efficiency.
Design goals and challenges
Use cases for in-memory key-value stores have evolved beyond caching to things such as storing data indices, machine learning model parameters, nodes and edges in graph computing, and sequencers in distributed synchronisation. The role of the store shifts from object caching to a generic data structure store (c.f. Redis). This leads to the following design goals:
- High batch throughput for small key-value pairs (e.g., model parameters, graph node neighbours).
- Predictable low-latency (e.g., for data-parallel computation,where tail latency matters)
- High efficiency under write-intensive workloads (e.g., graph computations, and parameter servers)
- Fast atomic operations (e.g., for centralized schedulers, sequencers , counters and so on).
- Vector-type operations (for machine learning and graph computing workloads that often require operating on every element in a vector).
The throughput constraint ends up being PCIe bandwidth:
In order to saturate the network with GET operations, the KVS on NIC must make full use of PCIe bandwidth and achieve close to one average memory access per GET.
Getting to this level involves work on three fronts:
- Minimising DMA (direct memory access) requests per KV operation. The two major components that drive random memory access are hash tables and memory allocation.
- Hiding PCIe latency while maintaining consistency, which entails pipelining requests. Care must be taken to respect causal dependencies here though.
- Balancing load between NIC DRAM and host memory. The NIC itself has a small amount of DRAM available, but it turns out not to be much faster than going over PCIe. So the trick turns out to be to use both in order to utilise the joint bandwidth.
KV-Direct
KV-Direct enables remote direct key-value access. Clients send operation requests to the KVS server, and the programmable NIC processes requests and sends back results, bypassing the CPU.
The following table shows the supported operations.

The most interesting of course are the vector operations.
KV-Direct supports two types of vector operations: sending a scalar to the NIC on the server, where the NIC applies the update to each element in the vector; and sending a vector to the server, where the NIC updates the original vector element-by-element. Furthermore, KV-Direct supports user-defined update functions as a generalisation to atomic operations. The update functions needs to be pre-registered and compiled to hardware logic before executing.
When the user supplies an update function, the KV-Direct toolchain duplicates it several times to leverage FPGA parallelism and match computation with PCIe throughput, and then compiles it into reconfigurable hardware logic using a high-level synthesis (HLS) tool. These functions can be used for general stream processing on a vector value.
The programmable NIC on the KVS server is reconfigured as a KV processor, which receives packets from the network, decodes vector operations, and buffers KV operations in a reservation station. The out-of-order engine then issues independent KV operations from the reservation station into the decoder.
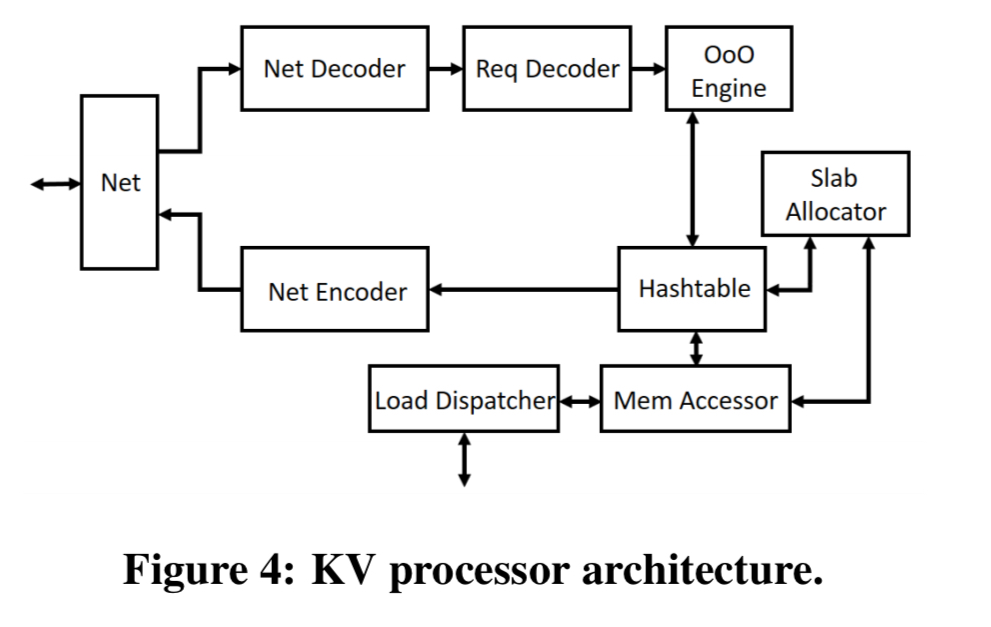
To minimise memory accesses, small KV pairs are stored inline in the hash table, while others are stored in dynamically allocated memory from a slab memory allocator. After a KV operation completes, the result is sent back to the out-of-order execution engine to find and execute matching KV operations in the reservation station.
The reservation station is used to avoid dependencies between two KV operations leading to data hazards and a stalled pipeline.
We borrow the concept of dynamic scheduling from computer architecture and implement a reservation station to track all in-flight KV operations and their execution context. To saturate PCIe, DRAM and the processing pipeline, up to 256 in-flight KV operations are needed. However, comparing 256 16-byte keys in parallel would take 40% of the logic resource of our FPGA. Instead, we store the KV operations in a small hash table in on-chip BRAM, indexed by the hash of the key.
When a KV operation completes, the latest value is forwarded to the reservation station, where pending operations in the same hash slot are checked. Those with a matching key are executed immediately and removed from the station.
Further design and implementation details can be found in sections 3 and 4 of the paper.
Evaluation
The evaluation section contains a suite of microbenchmarks, followed by a system benchmark based on the YCSB workload. To simulate a skewed Zipf workload, skewness 0.99 was chosen. This is referred to as the long-tail workload in the figures. The testbed comprises eight servers with two 8-core CPUS per server,and one Arista switch. There is a total of 128 GiB of host memory per server. A programmable NIC is connected to the PCIe root complex of CPU 0, and its 40 Gbps Ethernet port is connected to the switch. The NIC has two PCIe Gen3 x8 links in a bifurcated Gen3 x16 physical connector.
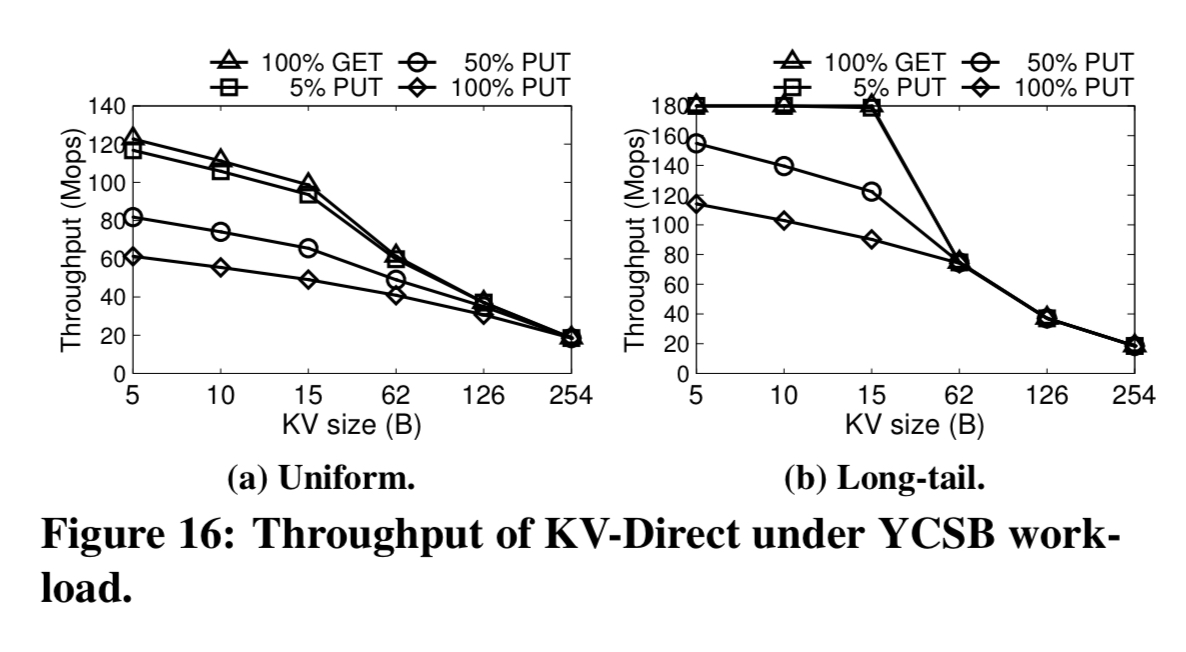
Here’s the overall throughput achieved by the system. The throughput of a KV-Direct NIC is on-par with a state-of-the-art KVS server with tens of CPU cores.
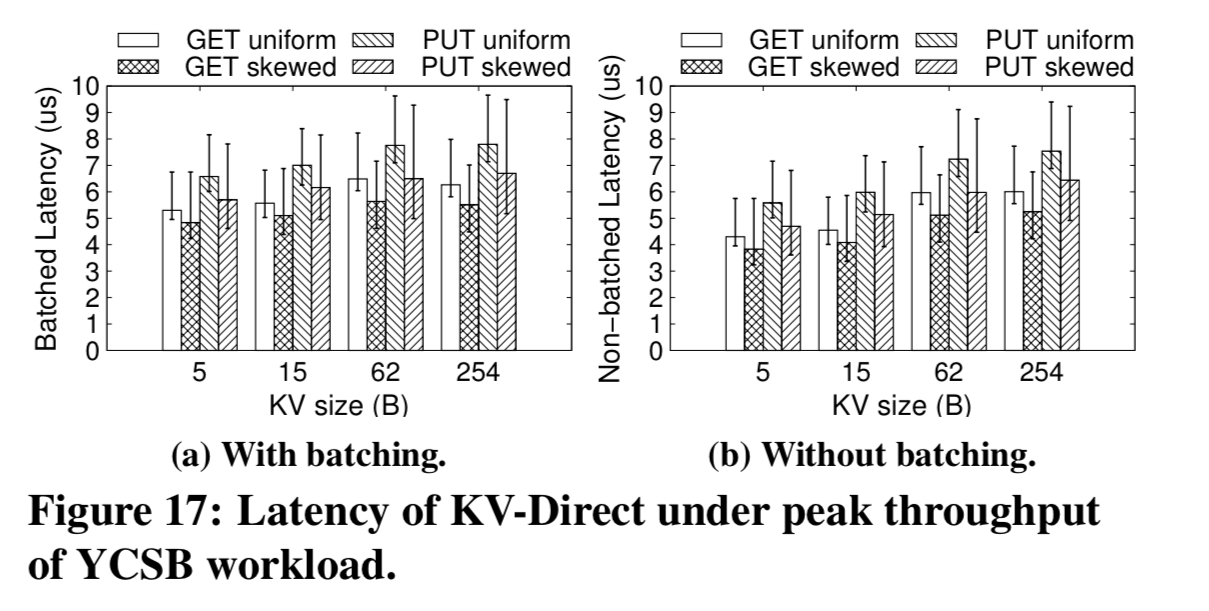
Without network batching, the tail latency ranges from 3-9 
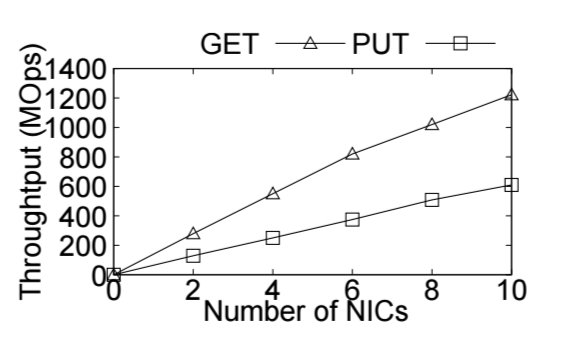
It is possible to attach multiple NICs per server. With 10 KV-Direct NICs on a server, one billion KV ops/s is readily achievable on a commodity server. Each NIC owns a disjoin partition of the keys. Multiple NICs suffer the same load imbalance problem as a multi-core KVS implementation, but for a relatively small number of partitions (e.g. 10) the load imbalance is not too great – 1.5x of the average in the highest loaded NIC even for the long-tail highly skewed workload. KV-Direct throughput scales almost linearly with the number of NICS on a server.
The last word:
After years of broken promises, FPGA-based reconfigurable hardware finally becomes widely available in main stream data centers. Many significant workloads will be scrutinized to see whether they can benefit from reconfigurable hardware, and we expect much more fruitful work in this general direction.

{kind=link}
The CORFU shared log paper https://blog.acolyer.org/2017/05/02/corfu-a-distributed-shared-log/ was performance limited by a central sequencer used to avoided append collisions. That post mentions 500k ops/s. It would seem that KVS could provide a very fast atomic counter shared sequencer to increase CORFU performance. Section 5.2.2 of the direct KVS paper talks about throughput of sequencers and 8 byte updates. Figure 16 suggests over 100M ops/s may be achieved. Combine that with CORFU would seem to allow for an extremely fast write distributed log.
Yes, actually both software- and hardware-based KVS systems produce high sequencer throughput. With commodity RDMA-based NICs, the paper “Design Guidelines for High Performance RDMA Systems” on ATC’16 produced 100+ million operations per second throughput for atomic counters. Our KV-Direct work use programmable NICs to push it further and support general atomic operations (e.g. fetch-and-add, compare-and-swap) beyond counters.
The CORFU shared log paper https://blog.acolyer.org/2017/05/02/corfu-a-distributed-shared-log/ was performance limited by a central sequencer that as used to avoided append collisions. That post mentions 500k ops/s. It would seem that KVS could provide a very fast atomic counter to increase CORFU performance.
Have they made the codes for these available on GitHub or anything? I would like to have a look at their VHDL code in particular. Sincerely,
I’m an author of KV-Direct. The system is written in Intel (formerly Altera) OpenCL, and the FPGA board is Catapult FPGA (Intel Stratix V) from Microsoft. We are sorry that we cannot publish our code due to NDA. It takes 7K lines of OpenCL code on the FPGA and consumes almost all of the FPGA logic resource. On the host there are also 5K lines of C++ code for FPGA driver and control program (including the host side of slab allocator). If you have any questions about the system, please feel free to send me an email (bojieli at gmail.com).
Hi bojieli, it’s great to see you here! KV-Direct is a really interesting project, thank you.
Does KV-Direct support two or more concurrent operations for same key? And how it hold the correctness? Suppose the following scenario:
Client 1 update key X’s value(assume it is Y) by increase 3, and meanwhile Client 2 update key X’s value Y by increase 4, the two opeartions are received by different NIC, and how to guarantee the value of key X will eventually be Y+7?
Amazing work. It’s pity everything in such level is under NDA.
Looks like only RAMCloud is delivered as open source solution, but nobody ever head about production deployment.
I guess everybody needs to continue re-implement multiple OMS’es in same organization (just for different business unit) until someone will dare to open source proper solution one day in a far far future ;-)
It’s also a pity that I cannot share the code. But it might not be too hard to re-implement the work for some real use cases.
To my knowledge typical usage scenarios of KV-Direct actually does not need a full-fledged key-value store. For caching, the throughput of CPU based key-value stores is often fast enough, if we use open-source research systems, e.g. HERD or MICA. The true use case for such a high-performance key-value store (KV-Direct) is in-memory computing, e.g., parameter server and graph computing. In these applications, the keys and value sizes are often predetermined and therefore the FPGA can map a key to a fixed memory address using an application specific mapping table. So in these applications we do not need the hash table and slab allocator at all.
IMHO the key message KV-Direct delivers is that we can use SmartNICs to access host memory and perform computation bypassing CPU. Key-value store is only one of the applications we examine. We write the paper using KVS because it is a standard application and easy to compare with state-of-the-art. Given the programming complexity of SmartNICs, we should keep in mind that not every application needs a standard key-value store and the SmartNIC accelerator should be customized for the application.