Corfu: A distributed shared log Balakrishnan et al., ACM TOCS, 2013
(If you experience any difficulty in accessing the pdf in the above link please let me know, it should be open for you on the ACM DL. UPDATE, many readers are still seeing a paywall for the above paper link, here’s an alternative open version of the same paper while we work out why that is…).
Tomorrow we’ll be looking at an NSDI’17 paper entitled vCorfu, which as its name implies builds upon today’s choice, Corfu. Corfu itself provides an append-only log abstraction, which is shared between multiple processes and distributed across multiple storage devices.
Despite almost forty years of research into replicated storage schemes, the only approach so far to scale up capacity and throughput has been to shard data and trade consistency for performance. […] the CORFU system breaks this seeming tradeoff by organizing a cluster of drives as a single, shared log. CORFU offers a single-copy semantics at cluster-scale speeds, providing a scalable source of atomicity and durability for distributed systems.
Why a shared log?
If we can construct a (suitably performant) linearizable shared log, then this primitive can be used as a key building block to solve some hard distributed systems problems: an agreed upon global ordering becomes simply the order of events in the log, and through state machine replication, this can be parlayed into consistent views of system state. Shared logs have been used for failure atomicity and node recovery, for consistent remote mirroring, and for transactional systems…
… a shared log is a panacea for replicated transactional systems. For instance, Hyder is a recently proposed high-performance database designed around a shared log, where servers speculatively execute transactions by appending them to the shared log and then use the log order to decide commit/abort status.
Corfu and Paxos are neighbouring Greek islands, which gives a clue as to another use of shared logs: as a consensus engine:
Used in this manner, CORFU provides a fast, fault-tolerant service for imposing and durably storing a total order on events in a distributed system. From this perspective, CORFU can be used as a drop-in replacement for existing Paxos implementations, with far better performance than previous solutions.
(See The Morning Paper series on consensus for more details).
The authors build two applications on top of CORFU to demonstrate the possibilities: CORFU-Store is a key-value store with atomic multikey puts and gets and low-latency geo-distribution, where CORFU acts as a log of data updates, durably storing data versions without overwriting them in place; CORFU-SMR is a State Machine Replication library where replicas propose commands by appending them to the log and execute commands by playing the log.
Challenges in implementing an efficient shared log
A shared log certainly sounds desirable, but of course it needs to present a single strongly consistent view of the log state, offer high performance, durability and fault tolerance. If it was easy, everyone would be doing it!
The performance requirements eliminate a class of designs in which everything must be serialized through an elected leader. Replication helps with durability and fault tolerance, but Corfu still needs to cope with both processes and storage units that may fail at any point in time, allowing reconfiguration of the system with no loss or disruption. And once we have replication, we need to start worrying about consistency again…
Introducing CORFU
CORFU provides a very simple API to applications, consisting of append, read, trim, and fill operations. Append adds to the end of the log, read returns the log entry at a given log position. We’ll return to the use of trim and fill shortly.
Our design places most CORFU functionality at the clients, which reduces the complexity, cost, latency, and power consumption of the storage units. In fact, CORFU can operate over SSDs that are attached directly to the network, eliminating general purpose storage servers from the critical path.
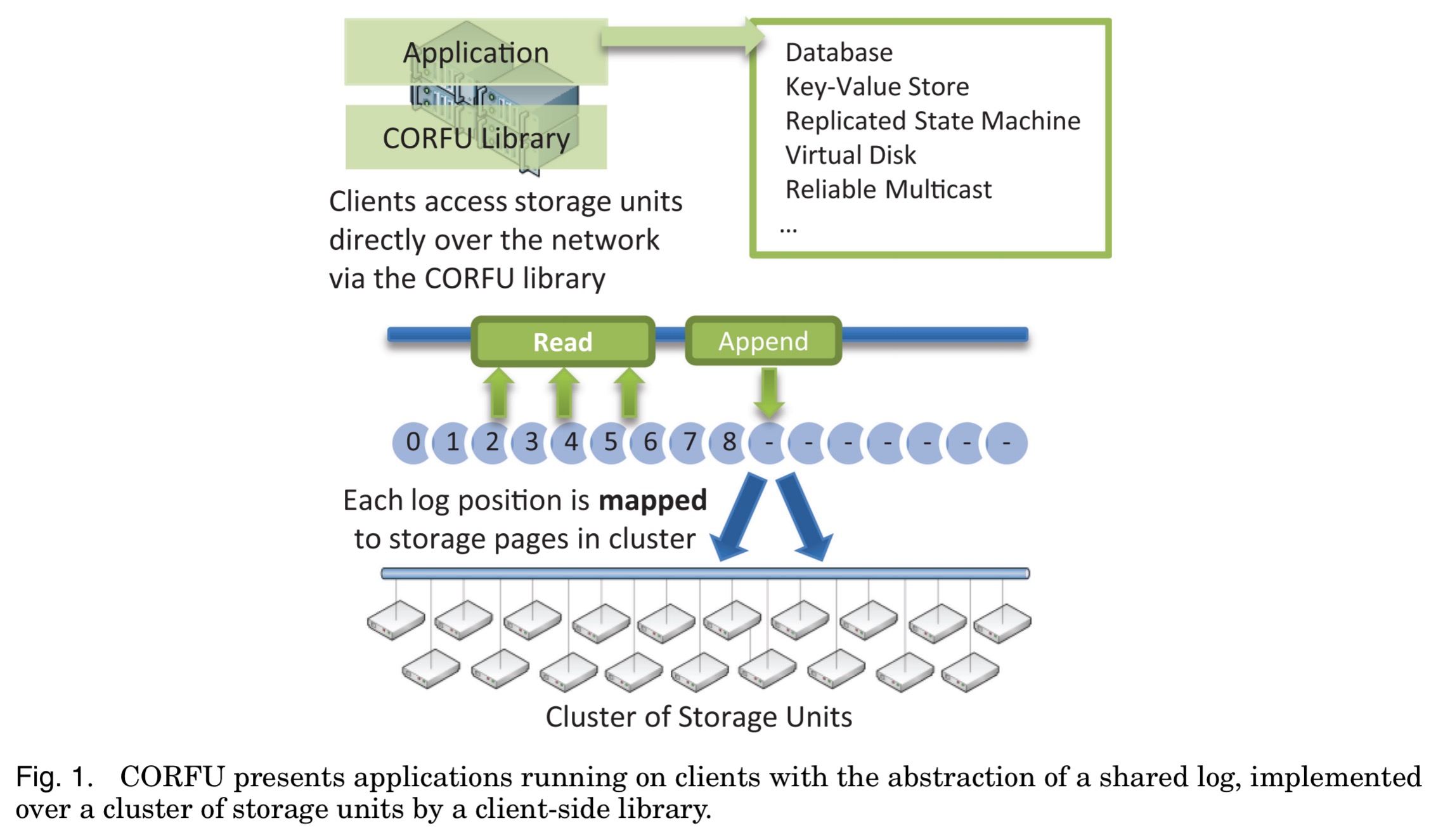
Every position in the shared log is mapped (projected) onto a set of storage pages on different storage units. The mapping is maintained at the clients, and Corfu therefore needs a mechanism consistently update it. To read from the log, a client looks up the required storage page in the map, and then issues a read directly to the storage unit containing it. Appends are also written directly to the storage page for the next available log position. A sequencer node (strictly an optimisation to avoid contention with other appending clients) assigns tokens for log positions.
In this way, the log in its entirety is managed without a leader, and CORFU circumvents the throughput cap of any single storage node. Instead, we can append data to the log at the aggregate bandwidth of the cluster, limited only by the speed at which the sequencer can assign them 64-bit tokens, that is, new positions in the log.
A user-space sequencer is capable of serving 500K tokens/s.
Storage unit interface and protocols
Storage units support read and write operations over fixed-size pages. Logical ‘storage pages’ in a logical address space are mapped to physical pages on device using a hash-map.
To support a specially-tailored replication protocol we have devised for the shared log, CORFU requires “write-once” semantics on the storage unit’s address space. Reads on pages that have not yet been written should return an error code (
err_unwritten). Writes on pages that have already been written should also return an error code (err_written).
When an address is written for the first time, it is added to the hash-map. Entries can be deleted, with a bit in the hash-map entry indicating whether or not an entry is deleted. Reads succeed when an entry exists in the hash-map that is not marked as deleted. Writes succeed when an address is not in the hash-map (deleted or otherwise). A watermarking scheme is used to remove older deleted addresses from the hash-map. Special support is given for writing ‘junk’ entries (used when a client invokes the ‘fill’ operation) – the entry made in the hash-map points to a special known ‘junk’ address rather than actually having to write to disk.
To support moving between configurations, storage units also support a seal operation. Every request to a storage unit is tagged with an epoch number, and once sealed, any subsequent messages sent with an epoch equal or lower to the sealed epoch are rejected.
In the evaluation, the authors implemented storage units with both server-attached SATA SSDs (a pair of SSDs attached to a server accepting network commands), and also networked-attached flash with a custom FPGA implementation (server functionality and network protocols entirely in hardware).
The projection map
The projection map maintained at clients divides the log into disjoint ranges, each of which is projected to a list of extents within the address spaces of individual storage units. For example:
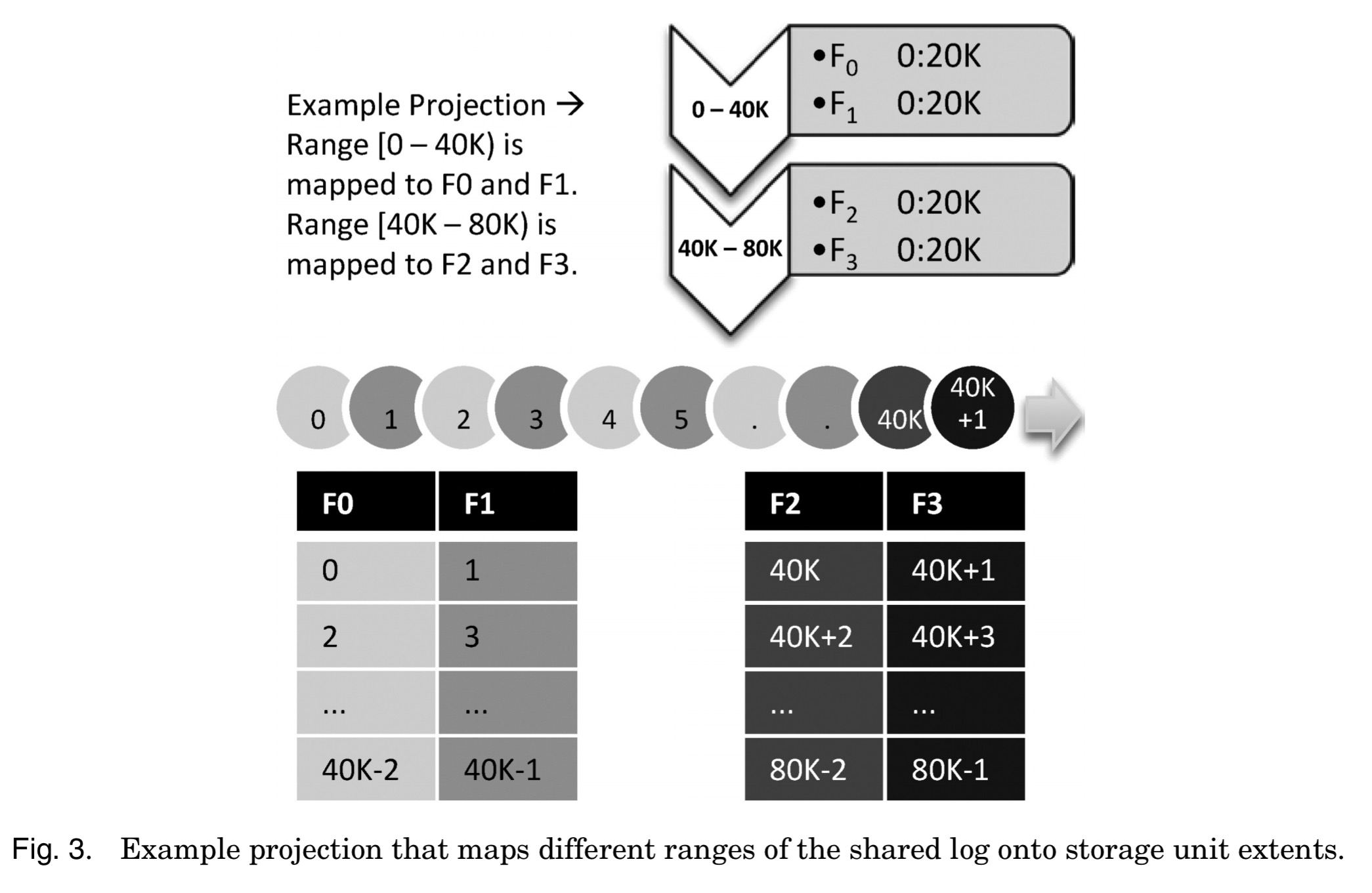
Within each log range, log positions are mapped to storage pages in the corresponding list of extents via any deterministic function (e.g., round robin). While the map above shows each log position mapped to a single storage page, for replication purposes each extent is actually associated with a replica set of storage units rather than just one unit.
When an event occurs such that we need to change the projection map (adding or removing capacity, coping with failures, or the tail of the log moving past the current active range), then the system moves to a new projection.
When we change the projection, we invoke a seal request on all relevant storage units, so that clients with obsolete copies of a projection will be prevented from continuing to access them. All messages from clients to storage units are tagged with the epoch number, so messages from sealed epochs can be aborted. In this sense, a projection serves as a view of the current configuration.
Projection changes may link in new ranges, keeping the old ones intact, or may affect the configuration of some past ranges but not others. Over time therefore the log evolves in disjoint ranges, each using its own projection over a set of storage extents.
Here’s an example of a map moving through a sequence of projections:
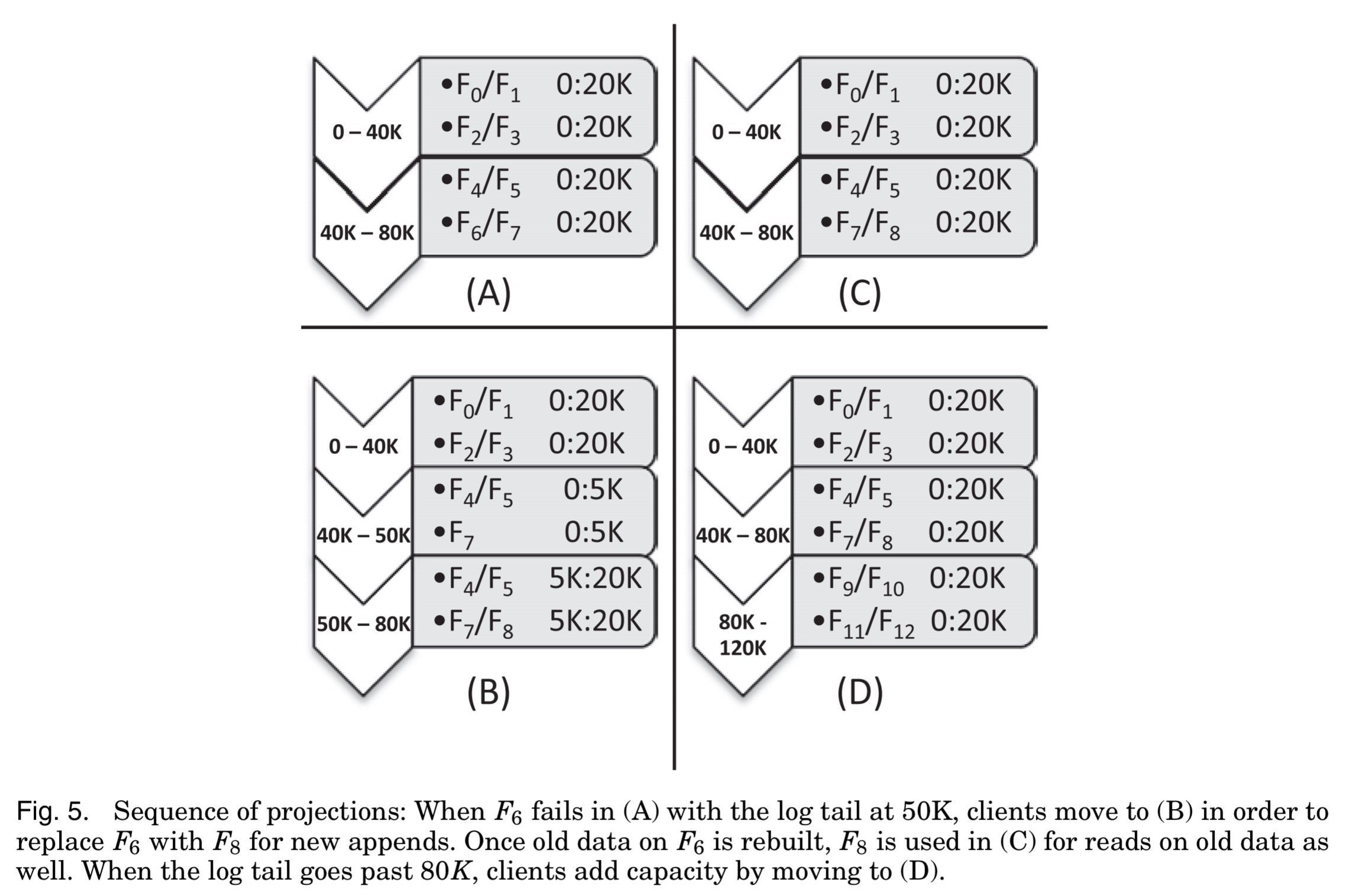
A ‘seal-and-snapshot’ step first ensures that any appended value in the current project survives reconfiguration, and then a Paxos-like consensus protocol using storage units in place of Paxos-acceptors is used to reach agreement on a new (client-proposed) configuration. Clients discovering that there current map is stale read the latest one from a shared location (“we currently employ a shared network drive… but other methods may replicate this information more robustly.“).
Appending to the log
So long as only one write to any given log position can succeed (guaranteed by the write-once storage unit semantics) we could just allow clients to contend on each log position and only one would win. For efficiency (avoiding contention), a dedicated sequencer assigns client tokens corresponding to empty log position.
Importantly, the sequencer does not represent a single point of failure; it is merely an optimization to reduce contention in the system and is not required for either safety or progress. For fast recovery from sequencer failure, we store the identity of the current sequencer in the projection and use reconfiguration to change sequencers.
If a client obtains a token and then fails to use it immediately due to a crash or slowdown then this leaves a hole in the log which can cripple applications consuming the log in strict order. The solution to this is to have other clients aggressively fill holes (with a reserved junk value). If the client holding the token does then try to write to the log entry, it will get an err_written response code and can fetch a new token. This filling scheme of course reintroduces a form of contention for log positions, so the sequencer does not eliminate contention entirely.
For fault tolerance, as previously mentioned, each position in the projection is backed by a replica set of storage pages. CORFU uses a simple chaining protocol to write data to the replica set members, driven by the client.
When a client wants to write to a replica set of storage pages (after having obtained a token for this position), it updates them in a deterministic order, waiting for each storage unit to respond before moving to the next one. The write is successfully completed when the last storage unit in the chain is updated. As a result, if two clients attempt to concurrently update the same replica set of storage pages, one of them will arrive second at the first unit of the chain and receive an
err_ written.
Readers that know a write has completed can read from any point on the chain, otherwise they must read from the last unit of the chain to verify that a write completed. Hole filling (due e.g., to client failure part way through the chain replication) is slightly more sophisticated when using replica sets:
… the client starts by checking the first unit of the chain to determine if a valid value exists in the prefix of the chain. If such a value exists, the client walks down the chain to find the first unwritten replica, and then “completes” the append by copying over the value to the remaining unwritten replicas in chain order. Alternatively, if the first unit of the chain is unwritten, the client writes the junk value to all the replicas in chain order. CORFU exposes this fast hole-filling functionality to applications via a fill interface.
Section 2.4 in the paper discusses another failure scenario in which due to a configuration change combined with a network partition, a client may remain unaware of a new configuration and potentially not see a completed write. Reads are still serializable in this case, which may suffice. If not, reads can be required to go to all replicas or a leasing scheme can be introduced.
Garbage collection
Applications use the trim operation in the CORFU interface to tell CORFU that individual log positions are no longer in use. Storage units may then garbage collect the address space.
What we didn’t cover…
This write-up is already over my target length. I chose to concentrate on the core CORFU mechanism, as a foundation for understanding the NSDI’17 vCorfu paper we’ll be looking at tomorrow. See the original ACM TOCS paper (which runs to 24 pages) linked at the top of this post for more details on the two applications built on top of CORFU as part of the evaluation, and for details of system latency (~0.5 – 2ms, depending on operation), throughput (~180K/380K reads/appends of 4K entries per second), and reconfiguration times (around 30ms) in a 16 server cluster with 32 drives.
Corfu is available as an open source project at https://github.com/CorfuDB/CorfuDB .

I hit a paywall on the PDF @ ACM, alternative download link here: http://www.cs.yale.edu/homes/mahesh/papers/corfumain-final.pdf
Hi Mats, thanks for letting me know, I’m going to update the main post with the alternative link and figure out what’s happening with the ACM DL thing in the background. Regards, Adrian.
The second (err_unwritten) should be (err_overwritten)
err_written according to section 2.1 I think, but definitely not err_unwritten! Thanks for the catch, I’ve updated the post. Regards, A.
In the Virtual Synchrony model, participants have an agreed ordering of all group messages, including participants joining and leaving the group. Isn’t that a kind of shared log?
The pseudocode in the paper doesn’t apply any validation to delete messages. That would appear to risk losing deletes. I have asked a question on stackoverflow as to why that is acceptable at https://stackoverflow.com/q/44236051/329496 I recreated a new SO tag ‘corfu’ in case anyone else has any questions about the paper. Thanks for the excellent summary!