The design, implementation, and deployment of a system to transparently compress hundreds of petabytes of image files for a file storage service Horn et al., NSDI’17
When I first started reading, I thought this paper was going to be about a new compression format Dropbox had introduced for JPEG images. And it is about that, but it’s also about so much more, as we also learn a little bit of what it’s like to think and operate at Dropbox scale and what it takes to roll out an algorithmic improvement in production. It’s a rare treat to to get such a full ‘soup to nuts’ treatment.
Lepton (available as open source) is a compression tool that replaces the Huffman code at the lowest layer of baseline JPEG compression with a parallelized arithmetic code.
Lepton losslessly compresses an average JPEG image by about 23%. This is expected to save Dropbox more than 8% of its overall backend file storage. Lepton introduces new techniques that allow it to match the compression savings of prior work (PackJPG) while decoding more than nine times faster and in a streaming manner.
Lepton has been running in production on Dropbox since April 2016, as of February 2017 it had been run on over 150 billion user files (203 PiB of input), reducing total size by more than 46 PiB!
Images on Dropbox
Dropbox manages roughly one exabyte of data, with JPEG images accounting for about 35% of that.
We suspected that most of these images were compressed inefficiently, either because they were limited to “baseline” methods that were royalty-free in the 1990s, or because they were encoded by fixed-function compression chips. In response, we built a compression tools, called Lepton that replaces the lowest layer of baseline JPEG images – the lossless Huffman coding – with a custom statistical model that we tuned to perform well across a broad corpus of JPEG images stored in Dropbox.
Lepton must be lossless – i.e., it needs to be able to recover the exact bytes of the original file, even for intentionally malformed files. Since the Dropbox back-end stores files in independent 4 MiB chunks across many servers, Lepton must also be able to decompress any substring of a JPEG file in isolation.
An image stored in Lepton format needs to be decoded to restore the original file format when a user accesses it. Users are sensitive to file download latency, both time-to-first-byte and time-to-last-byte, so decompression must be fast. Decoding speed must be fast enough to saturate a typical user’s Internet connection (> 100 Mbps), which requires multithreaded decoding.
Dropbox applies compression immediately upon upload of new JPEG files. In the background, existing files are also being compressed at a rate of roughly a petabyte per day – consuming about 300 kW continuously!
Cost effectiveness
A kWh of the encoding process is enough to compress 72,300 images at an average size of 1.5MB each – saving 24GiB of storage.
Imaging a depowered 5TB hard drive costing $120 with no redundancy or checks, the savings from the extra space would be worthwhile as long as a kWh costed less than $0.58. Even in Denmark, where electricity costs about $0.40 per kWh, Lepton would be a worthwhile investment for a somewhat balanced read/write load of 3:1. Most countries offer prices between $l0.07 and $0.12 per kWh. With cross-zone replication, erasure coding, and regular self-checks, 24 GiB of storage costs significantly more in practice.
Looked at another way, an Intel Xeon E5 can process 181,500,000 images per year saving 58.8 TiB of storage. This costs $9,031 per year on the Amazon S3 infrequent access tier. The capital expense of the Xeon is much less than this and so is comfortably recouped within the first year of operation.
The core Lepton algorithm
A JPEG file has two sections: headers, and image data itself (the ‘scan’).
The “scan” encodes an array of quantized coefficients, grouped into sets of 64 coefficients known as “blocks.” Each coefficient represents the amplitude of a particular 8×8 basis function; to decode the JPEG itself, these basis functions are summed, weighted by each coefficient, and the resulting image is displayed. This is known as an inverse Discrete Cosine Transform.
Regular JPEG files use a Huffman code to write the coefficients. When Huffman coding, more probable values consume fewer bits in the output, saving space overall. The Huffman probability tables themselves are given in the header.
Lepton makes two major changes to this scheme. First, it replaces the Huffman code with an arithmetic code [a modified version of a VP8 range coder], a more efficient technique that was patent-encumbered at the time the JPEG specification was published (but no longer). Second, Lepton uses a sophisticated probability model that we developed by testing on a large corpus of images in the wild.
Lepton was inspired by the PackJPG compression tool, and achieves similar compression to PackJPG but without PackJPG’s requirements for global operations. This allows Lepton to distributed decoding across independent chunks, and use multiple threads within each chunk. For fast decoding, Lepton format files are partitioned into segments (one per decoding thread) and each thread’s segment starts with a “Huffman handover word” that allows the thread’s Huffman encoder (we have to restore the original Huffman encoding for the user) to resume in mid-symbol at a byte boundary.
The Lepton file format also includes a Huffman handover word and the original Huffman probability model at the start of each chunk, allowing chunks to be retrieved and decoded independently.
Lepton’s full probability model is detailed in an appendix to the paper.
In tests, Lepton is the fastest of any format-aware compression algorithm, and also compresses about as well as the best-in-class algorithms. (Lepton 1-way in the figure below is a single threaded version modified for maximum compression savings).
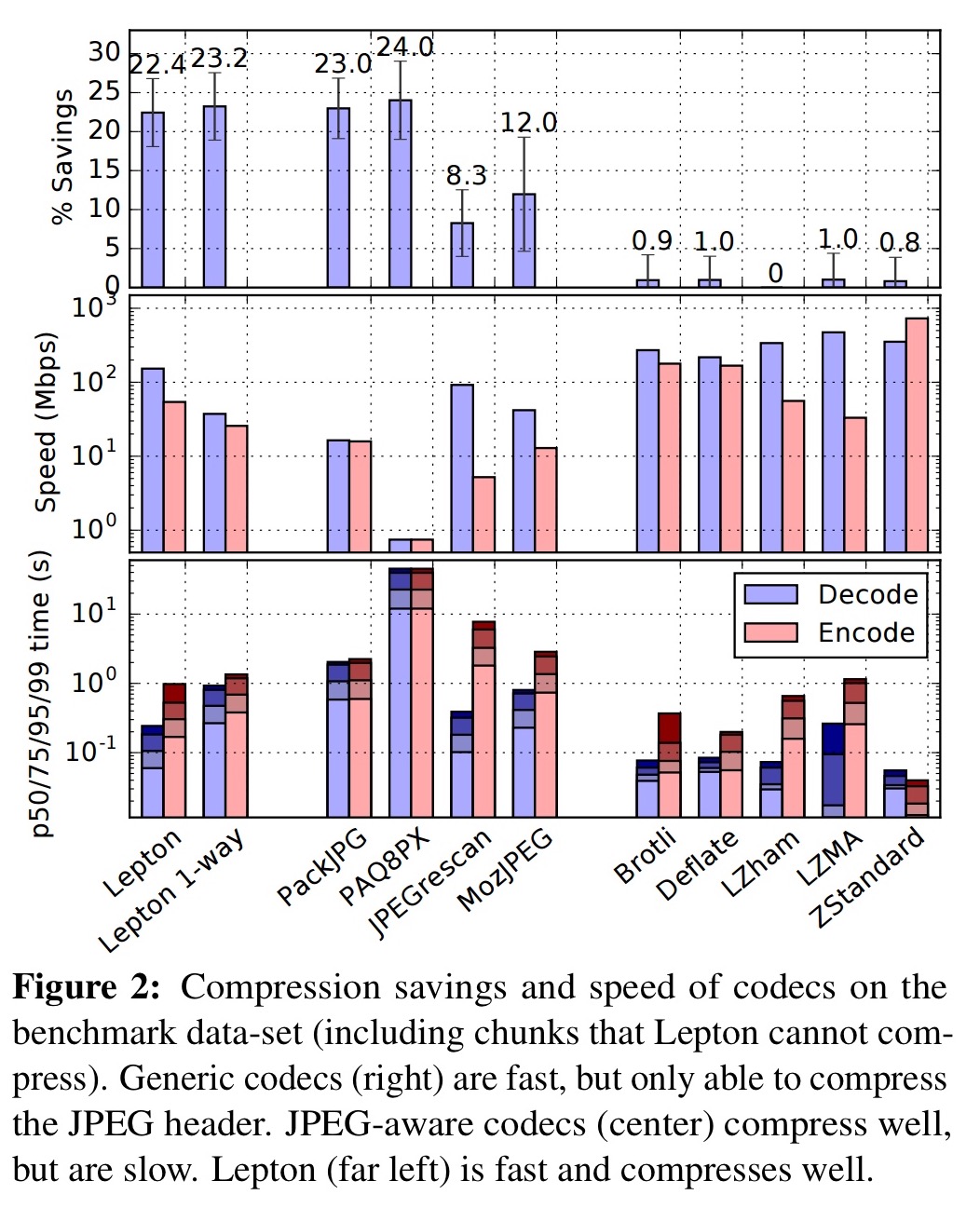
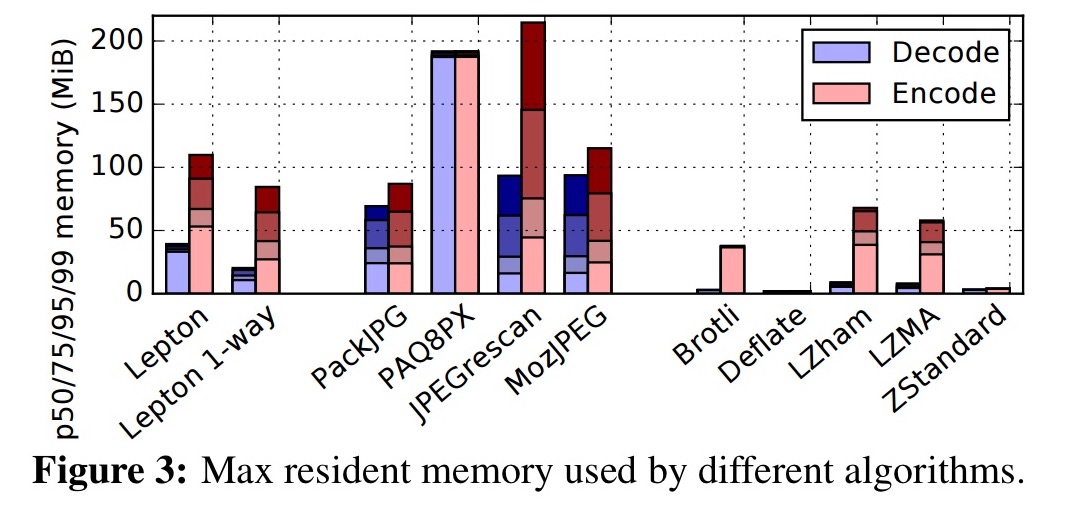
Lepton decoding is an order of magnitude faster than PackJPG, and encoding time is also substantially better than any other algorithm achieving appreciable compression. It does this while also constraining memory usage:
Deploying Lepton at scale
To deploy Lepton at large scale, without compromising durability, we faced two key design requirements: determinism and security. Our threat model includes intentionally corrupt files that seek to compress or decompress improperly or cause Lepton to executed unintended or arbitrary code or otherwise consume excess resources.
Determinism is made difficult by the ‘undefined behaviours’ which C++ compilers exploit to produce efficient code under heavy optimisation. Lepton is statically linked, and all heap allocations are zeroed before use – even so, this setup did not detect a potential buffer overrun. An additional fail-safe mechanism did detect this though: before deploying any version of Lepton, it is run on over a billion randomly selected images to compress and then decompress the files. “This system detected the non-deterministic buffer overrun after just a few million images were processed and has caught some further issues since.”
Security is enforced using Linux’s secure computing mode (SECCOMP). When this is activated, the kernel disallows all system calls except read, write, exit, and sigreturn. Such a program cannot allocate memory, so Lepton allocates a zeroed 200 MiB region of memory upfront before initiating SECCOMP.
In production at Dropbox, Lepton encodes images at between 2 and 12 GiB per second, with uniform savings across file sizes.
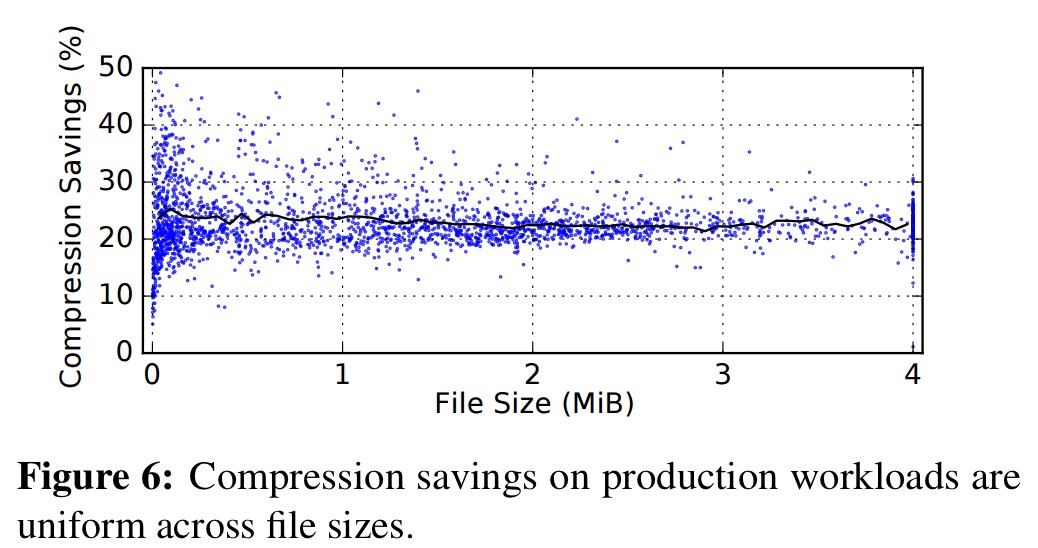
Small images are able to compress well because they are configured with fewer threads than larger images and hence have a higher proportion of the image upon which to train each probability bin.
A Dropbox blockserver has 16 cores, and handles requests to store or retrieve data chunks. A Lepton decode (or encode) uses 8 cores, so 2 simultaneous Lepton operations can saturate a machine. At peak, an individual blockserver can get up to 15 encode requests. Overloaded blockservers (3 or more compression operations occurring at a time) can offload work first to other blockservers that have capacity, and secondly to a dedicated Lepton processing cluster.
Lepton uses spare compute capacity to gradually compress older JPEG files (‘backfilling’).
Operating Lepton at scale
With a year of Lepton operational experience, there have been a number of anomalies encountered and lessons learned…
Here are the error codes observed during the first two-months of the backfill process: “the top 99.9864% of situations were anticipated.”

Note the small numbers of ‘impossible’ (but observed) error codes such as from an abort signal (SECCOMP disallows SIGABRT). A small number of roundtrip failures were expected thouh – due to corruptions in the JPEG file (e.g., runs of zeroes written by hardware failing to sync a file) that cannot always be represented in the Lepton file format.
- Some machines with transparent huge pages, THP, enabled (but none without) showed significantly higher average and p99 latency. Disabling THP solved the issue.
- With thousands of servers decoding chunks, some will be unhealthy and cause decoding to time out. Decodes exceeding a timeout are uploaded to an S3 queue bucket and decompressed on an isolated healthy cluster without a timeout. Chunks that decode successfully 3 times in a row are deleted from the bucket, if a decode fails a human is alerted.
- A security researcher fuzzed the open source release of Lepton and found bugs in the
uncmpjpgJPEG parsing library used by Lepton. Adding bounds-checking solved the issue, and SECCOMP prevents escalation of privileges. - An accidental deployment of an old (but “qualified” for deployment) version of Lepton, using a now out-of-date file format also triggered an alarm. Billions of files had to be checked, and ultimately 18 of them were re-encoded.
This was an example of a number of procedures gone wrong. It confirms the adage: we have met the enemy and he is us. The incident has caused us to reconsider whether a “qualified” version of Lepton ought to remain eternally qualified for deployment, the behavior and user interface of the deployment tools, and our documentation and onboarding procedures for new team members.
There are plenty more details and examples in the full paper.
What next?
Lepton is limited to JPEG-format files, which account for roughly 35% of the Dropbox filesystem. Roughly another 40% is occupied by H.264 video files, many of which are encoded by fixed-function or power-limited mobile hardware that does not use the most space-efficient lossless compression methods. We intend to explore the use of Lepton-like recompression for mobile video files.

3 thoughts on “The design, implementation and deployment of a system to transparently compress hundreds of petabytes of image files for a file storage service”
Comments are closed.