The RAMCloud Storage System – Ousterhout et al. 2015
This paper is a comprehensive overview of RAMCloud, published in the ACM Transactions on Computer Systems in August 2015. It’s a long read (55 pages), but there’s a ton of great material here. The RAMCloud project started in 2009, so this is therefore an overview of five years of work (it describes RAMCloud as of September 2014). The full list of RAMCloud papers is maintained on the project site. RAMCloud as described in this paper does not support full linearizability – but this is provided for with the RIFL extension, Remote Infrastructure For Linearizability that we looked at last year.
RAMCloud is “a general purpose distributed storage system that keeps all data in DRAM at all times.” It is designed for very low-latency at scale (5µs reads, 13.5µs durable writes). It does not assume persistent memory, instead it makes data durable using secondary storage. RAMCloud assumes fast networking, but does not make use of RDMA. The related work sections provides a good overview of the differences between RAMCloud and FaRM, which as we also saw last week in No Compromises, Distributed Transactions with Consistency, Availability, and Performance does. The conclusion of the RAMCloud authors is that RDMA does not provide a significant latency benefit, instead its primary benefit comes from offloading the server’s CPU. If an operation requires only a single RDMA operation, then FaRM can read a hashtable about 10% faster than RAMCloud, but if an operation requires two or more RDMA operations then an RPC-based approach is quicker.
RAMCloud combines low-latency, large scale, and durability. Using state of the art networking with kernel bypass, RAMCloud expects small reads to complete in less that 10µs on a cluster of 10,000 nodes. This is 50 – 1,000 times faster that storage systems commonly in use. It offers a key value store with up to 64KB keys, and up to 1MB objects. RAMCloud is designed for large clusters (e.g. 10,000 servers), providing overall storage capacity in the PB range. RAMCloud keeps all data (and only one copy of each data item) in memory, it maintains backup copies on secondary storage to ensure durability and high availability. Keeping redundant in-memory copies of data around the cluster would be a tax on the most expensive resource (memory), so the RAMCloud design is to optimise for fast recovery from stable storage if a node is lost.

Motivation
Once upon a time we used to be able to run applications on a single server. But the web has led to the creation of new applications that must support hundreds of millions of users; these applications cannot possibly use the single-machine approach.
Unfortunately, the environment forWeb applications has not scaled uniformly com- pared to the single-machine environment. The total computational horsepower available to a Web application has improved by a factor of 1,000× or more in comparison to single-server applications, and total storage capacity has also improved by a factor of 1,000× or more, but the latency for an application to access its own data has degraded by three to five orders of magnitude. In addition, throughput has not scaled: if an application makes small random read requests, the total throughput of a few thousand storage servers … is not much more than that of a single server ! As a result, Web applications can serve large user communities, and they can store large amounts of data, but they cannot use very much data when processing a given browser request.
(The limit as experienced at Facebook around 2009 – when the RAMCloud project began – was about 100-150 sequential requests for data while servicing a given browser request. Concurrent requests and materialized views were added to get around this limitation to a degree, but added a lot of application complexity).
We hypothesize that low latencies will simplify the development of data-intensive applications like Facebook and enable a new class of applications that manipulate large datasets even more intensively. The new applications cannot exist today, as no existing storage system could meet their needs, so we can only speculate about their nature.We believe they will have two overall characteristics: (a) they will access large amounts of data in an irregular fashion (applications such as graph processing [Nguyen et al. 2013; Gonzalez et al. 2012] or large-scale machine learning could be candidates), and (b) they will operate at interactive timescales (tens to hundreds of milliseconds).
Consider a future in which we are all being driven around in self-driving cars…
In a single metropolitan area, there may be a million or more cars on the road at once; each car’s behavior will be affected by thousands of cars in its vicinity, and the region of consciousness for one car could include 50,000 or more other cars over the duration of a commute. A transportation system like this is likely to be controlled by a large-scale datacenter application, and the application is likely to need a storage system with extraordinarily low latency to disseminate large amounts of information in an irregular fashion among agents for the various cars.
How RAMCloud Achieves Low Latency
When the project started, the greatest obstacle to achieving the latency goals (< 10µs reads in a large datacenter) was the installed base of networking infrastructure.
Our performance goals were already achievable with Infiniband networking, and new 10Gb/sec Ethernet switching chips offered the promise of both low latency and inexpensive bandwidth. We started the RAMCloud project with the assumption that low-latency networking infrastructure would become widely deployed within 5 to 10 years. Such infrastructure is available at reasonable cost today for 10Gb/sec Ethernet as well as Infiniband (56Gb/sec), although it is not yet widely deployed. In the future, significant additional improvements are possible. With new architectures for network switches and for NIC-CPU integration, we estimate that round-trip times within large datacenters could be reduced to less than 3µs over the next decade.

Even with high-performance networking infrastructure, most of the latency budget for an RPC is consumed by the network or communication with the NIC. There is about 1µs; for a RAMCloud server to process an RPC once it receives a request from the NIC. This means doing essential work only!
- RAMCloud bypasses the kernel and talks directly with the NIC
- Polling (busy waiting) is used to wait for events (blocking and then using a condition valiable to wake a thread would take about 2µs – double the budget right there!)
- RAMCloud uses a single dispatch thread handling all network communication, and a collection of worker threads. (This was necessary – vs. having just one thread – for fault tolerance, but adds two thread handoffs to each request costing a total of about 410ns).
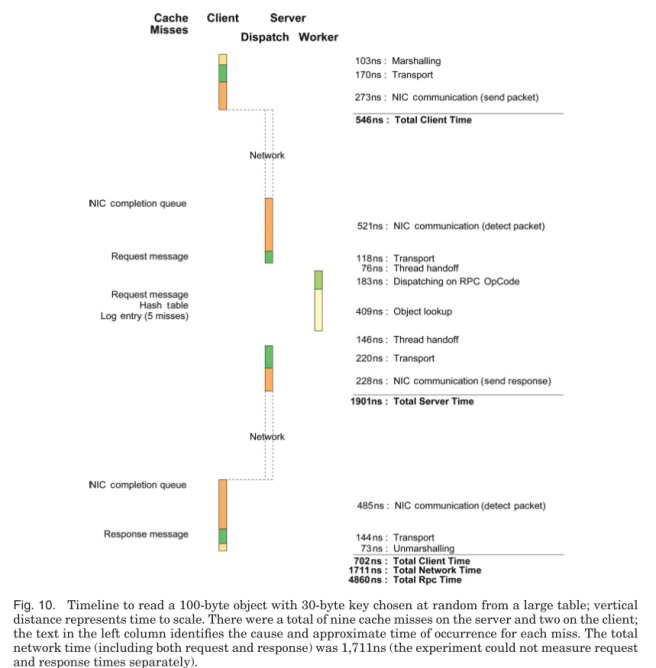
Here’s a sample timeline for a read of a 100-byte object with a 30-byte key.
Storage Management
RAMCloud provides durability and availability using a primary-backup approach to replication. It keeps a single (primary) copy of each object in DRAM, with multiple backup copies on secondary storage. We considered keeping additional copies of data in DRAM, but this would be very expensive, as DRAM accounts for at least half of total system cost even without replication. In addition, replication in DRAM would not solve the durability problem, as all of the DRAM copies could be lost in a datacenter power outage. Replication in DRAM could improve throughput for frequently accessed objects, but it would require additional mechanisms to keep the replicas consistent, especially if writes can be processed at any replica.
Data is stored using a log-structured approach inspired by log-structured filesystems. Each master manages an append-only log in which it stores all of its objects. A single log structure is used both for primary copies in memory and backup copies on secondary storage. The log-structured approach allows for:
- High throughput, since updates can be batched together for efficient writing to secondary storage
- Crash recovery, through replaying logs
- Efficient memory utilization whereby the log serves as storage allocator for most of the master’s DRAM
- Consistency by providing a simple way to serialize operations
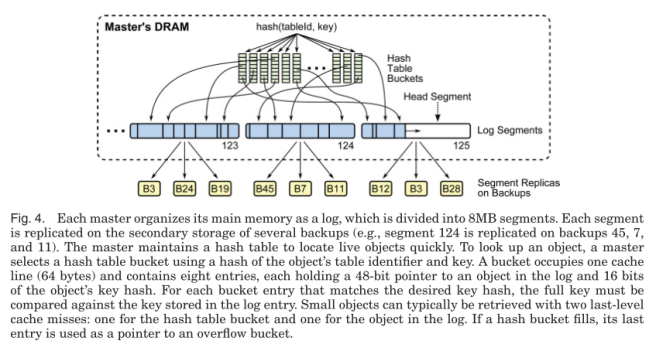
When the master receives a write request it first writes to its own log, and then replicates the log entry synchronously in parallel to the backups. Each backup adds the entry to its own in memory buffer, and initiates an (asynchronous) I/O operation to write the new data to secondary storage. The backup replies to the master without waiting for the I/O to complete, and the master responds to the client once it has received replies from all backups.
This approach has two attractive properties. First, writes complete without waiting for I/O to secondary storage. Second, backups use secondary storage bandwidth efficiently: under heavy write load, they will aggregate many small objects into a single large block for I/O. However, the buffers create potential durability problems. RAMCloud promises clients that objects are durable at the time a write returns. To honor this promise, the data buffered in backups’ main memories must survive power failures; otherwise, a datacenter power failure could destroy all copies of a newly written object. RAMCloud currently assumes that servers can continue operating for a short period after an impending power failure is detected so that buffered data can be flushed to secondary storage.
Recovery of free-space that accumulates in log segments (because newer versions of objects have subsequently been written) is done using a two-level log cleaner. The first level of cleaning operates only on the in-memory log segments of masters, and consumes no network or disk I/O. It compacts a single segment at a time. The second level of cleaning selects several disk log segments to clean at a time. The disk log is cleaned less frequently than the memory log.
Two-level cleaning leverages the strengths of memory and disk to compensate for their weaknesses.For memory, space is precious but bandwidth for cleaning is plentiful, so RAMCloud uses extra bandwidth to enable higher utilization. For disk, space is cheap but bandwidth is precious, so RAMCloud uses extra space to save bandwidth. One disadvantage of two-level cleaning is that the larger on-disk log takes more time to read during crash recovery, but this overhead can be offset by using additional backups during crash recovery (see
RAMCloud can support high memory utilization without sacrificing performance. At 80% utilization write throughput degraded less than 20% for all workloads except small objects with no locality. For large objects, even 90% utilization can be supported with low cleaning overhead.
Recovery
Here’s an important lesson to heed:
Fault tolerance has proven to be the most complex and difficult part of the RAMCloud implementation. It influenced almost every aspect of the system design, and we have spent considerably more effort on it than on achieving low latency.
RAMCloud is designed to offer normal service in the presence of individual server failures, and multiple failures that are randomly distributed and small in number. If a large-scale outage occurs (network partition, power failure), then the system may become partially or completely unavailable until the problem has been corrected and servers restarted. If a network partition occurs, only servers in the partition containing the current coordinator will continue to provide service.
Since error handling is a source of significant complexity, RAMCloud works hard to minimize this using two main techniques: minimising the visibility of failures through masking, and minimising the number of places where they need to be handled through failure promotion. An example of masking is that all internal RAMCloud failures are handled internally by the client library using retries etc..
We used the second technique, failure promotion, to handle failures within the storage servers. If a server detects an internal error such as memory corruption or a data structure inconsistency, it does not usually attempt to handle that problem in a problem-specific fashion. Instead, in most cases it “promotes” the error to a server crash by logging a message and exiting. Thus, instead of writing many different error handlers for each of the individual problems, we only had to write handlers for server crashes, which were unavoidable… In addition to reducing the complexity of failure handling code, failure promotion also has the advantage that the remaining fault handlers are invoked more frequently, so bugs are more likely to be detected and fixed.
In general failures that are expected to happen frequently (such as network communication problems) are handled by masking, and less frequent failures by promotion (since it tends to increase the costs of handling them).
Using failure promotion, RAMCloud has to deal with only three primary cases for fault tolerance: master crashes, backup crashes, and coordinator crashes.
When a master crashes, all information in its DRAM is lost and must be reconstructed from backup replicas. When a backup crashes, its replicas on secondary storage can usually be recovered after the backup restarts, and in some situations (such as a datacenter-wide power failure) RAMCloud will depend on this information. However, for most backup crashes, RAMCloud will simply re-replicate the lost information without waiting for the backup to restart; in this case, the backup’s secondary storage becomes irrelevant. When the coordinator crashes, a standby coordinator will take over and recover the crashed coordinator’s state from external storage.
In RAMCloud, since only the master copy of data is kept in memory, master crash recovery time affects availability. The target is to recover from master crashes in 1-2 seconds. A little back-of-the-envelope shows that this requires parallel recovery:
It is not possible to recover the data from a crashed master in 1 to 2 seconds using the resources of a single node. For example, a large RAMCloud server todaymight have 256GB of DRAM holding 2 billion objects. Reading all of the data from flash drives in 1 second requires about 1,000 flash drives operating in parallel; transferring all of the data over the network in 1 second requires about 250 10Gb/sec network interfaces, and entering all objects into a hash table in 1 second requires 1,000 or more cores.
Fast recovery is achieved by dividing the work of recovery across many nodes operating concurrently. Fast recovery also requires fast failure detection in the first place – RAMCloud must decide if a server has failed within a few hundred milliseconds. At regular intervals, each storage server chooses another server at random to ping, if the RPC times out (a few tens of milliseconds) the the server notifies the coordinator of a potential problem. The coordinator tries its own ping, and if that times out the server is declared dead.
There is much much more detail on recovery mechanisms in the full paper.
Lessons Learned
One of the interesting aspects of working on a large and complex system over several years with many developers is that certain problems occur repeatedly. The process of dealing with those problems exposes techniques that have broad applicability. This section discusses a few of the most interesting problems and techniques that have arisen in the RAMCloud project so far. Some of these ideas are not new or unique to RAMCloud, but our experience with RAMCloud has made us even more convinced of their importance.
- The log-structured approach has provided numerous benefits, not just performance improvements: it facilitates crash-recovery; provides a simple framework for replication; provides a convenient place to store metadata needed during recovery; makes consistency easier to achieve; makes concurrent access simpler and more efficient due to its immutable nature; provides a convenient way to neutralize zombie servers; and uses DRAM efficiently.
- “We have found randomization to be one of the most useful tools available for developing large-scale systems. It’s primary benefit is that it allows centralized (and hence nonscalable) mechanisms to be replaced with scalable distributed ones.”
- Layering is an essential technique for dealing with complexity, but it conflicts with latency. The authors take the following approach: start by asking ‘what is the minimum amount of work that is inevitable in carrying out this task?’; then seach for a clean module decomposition that comes close to the minimum work and introduces the fewest layer crossings. “Another way of achieving both low latency and modularity is to design for a fast path. In this approach, initial setup involves all of the layers and may be slow, but once setup has been completed, a special fast path skips most of the layers for normal operation.”
- Retry is a powerful tool in building a large-scale fault-tolerant system.
- “After struggling with early Distributed, Concurrent, Fault-Tolerant (DCFT) modules in RAMCloud, we found that a rules-based approach works well for them… overall we have learned that DCFT problems do not lend themselves to traditional, monolithic, start-to-finish algorithms. The easiest way to solve these problems is to break them up into small pieces that can make incremental progress; once we change our mind-set to this incremental mode, it became much easier to solve the problems.”
Fortunately, the team wrote a whole separate paper on their rules-based DCFT approach, and we’ll look at that tomorrow!

For people looking for something shorter than the 55-page TOCS paper there is a good overview of RAMCloud in the CACM at http://dl.acm.org/citation.cfm?id=1965751.