Experience with Rules-Based Programming for Distributed, Concurrent, Fault-Tolerant Code – Stutsman et al. 2015
As we saw in yesterday’s paper, the authors of RAMCloud settled on a very effective design pattern for writing distributed, concurrent, fault-tolerant (DCFT) modules within their system. They call this pattern ‘rules-based programming’ – a collection of (condition,action) pairs that can execute very efficiently even in the highly demanding latency sensitive environment of RAMCloud. If you have to write logic that makes lots of concurrent requests, requires fault-tolerance / failure handling, and must cope with non-determinism – as well as being concise and as easy to understand as the domain allows – then you definitely want to study the rules-based DCFT pattern.
Over the last decade more and more systems programmers have begun working on new and challenging software subsystems that manage distributed resources in a concurrent and fault-tolerant fashion. We call these subsystems DCFT modules (Distributed, Concurrent, Fault-Tolerant)… DCFT code is different from most systems code because it must describe behavior that is highly nondeterministic. As a result, DCFT modules are painfully difficult to implement.
After struggling with this pain, the team settled upon a rules-based pattern that they repeatedly used for such modules. The rules-based approach to writing DCFT modules delivered great results in RAMCloud:
- The team were able to address a wide-range of problems using it
- Modules were small – typically 30-100 lines of code
- Rules are efficient – rules overheads account for only about 200-300ns out of the 13.5µs total write time in RAMCloud
To demonstrate applicability outside of the RAMCloud system, the team also re-wrote the Hadoop Map-Reduce job scheduler (which uses a traditional event-based state machine approach) using rules. The original code has three state machines containing 34 states with 163 different transitions, about 2,250 lines of code in total. The rules-based re-implementation required 19 rules in 3 tasks with a total of 117 lines of code and comments.
And although the authors of RAMCloud haven’t used any formal specification technique to my knowledge, the rules-based approach is also very amenable to specification in TLA+/PlusCal allowing desired properties to be verified using the TLA+ tool chain. This could be a wonderful combination.
Motivation
We did not consciously choose a rules-based approach for RAMCloud’s DCFT modules: the code gradually assumed this form as we added functionality over a series of refactorings… we initially tried to write each module as a monolithic piece of code that solved a problem from start to finish using a traditional imperative approach. However, this approach broke down almost immediately because of nondeterminism caused by concurrency and faults. To handle the nondeterminism, the code disintegrated into fragments that needed to execute relatively independently. None of our DCFT modules has reached anywhere near complete functionality with an imperative implementation.
Failures undo work that was previously considered to be completed, requiring earlier steps to be redone. They can also happen at many points, and different kinds of failure require different sorts of rework…
As a result, it isn’t possible to code an algorithm from start to finish. It makes more sense to think about the algorithm in terms of steps that make incremental progress, such as selecting a backup server or transmitting the segment header to the server for a particular replica. The execution order of the steps is non-deterministic, based on concurrency and failures.
High-level Approach
We use the term rules-based to describe a style of programming where there is not a crisp algorithm that progresses monotonically from beginning to end. Instead, the top-level controlling code of the module is divided into small chunks, called actions, which can potentially execute in any order. Each action has an associated condition that determines when the action can execute; the condition is expressed as a predicate on the module’s state variables. Together, an action and its associated condition constitute a rule.
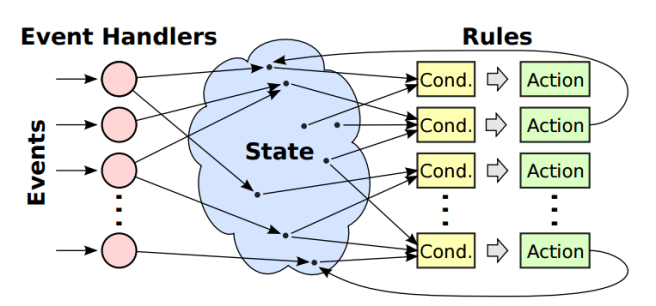
A module comprises a set of rules that each make incremental progress towards some module-level goal, also expressed as a predicate over the module state. Actions may modify the state of the module or initiate asynchronous external operations such as RPCs. While the module goal is not met, the module repeatedly executes rules enabled by their pre-conditions. In pseudo-code:
while (! goalSatisfied()) {
for (rule : rules) {
if (preconditionSatisfied(rule)) {
execute(rule.action);
}
}
}
If an action turns out to involve blocking or must handle nondeterminism due to faults, then it must be split into multiple actions in different rules. For example, an action cannot both initiate an RPC and wait for it to complete, since that would require the action to block and would expose it to nondeterministic failures of the RPC.
Non-determinism is also manifest in terms of events – occurrences outside of the direct control of the module such as the completion of an RPC. Event handlers update module state variables, which in turn may cause rules to become activated or deactivated.
The rules-based approach is similar in many ways to event-based programming. However, in event-based programming an event typically triggers actions directly. In the rules-based approach an event handler merely updates state variables; actions are then triggered based on the new state. In our experience, this two-step approach results in a cleaner factoring of code than the traditional event-based approach.
The following example shows a partial list of rules and events for replication a log segment in RAMCloud:
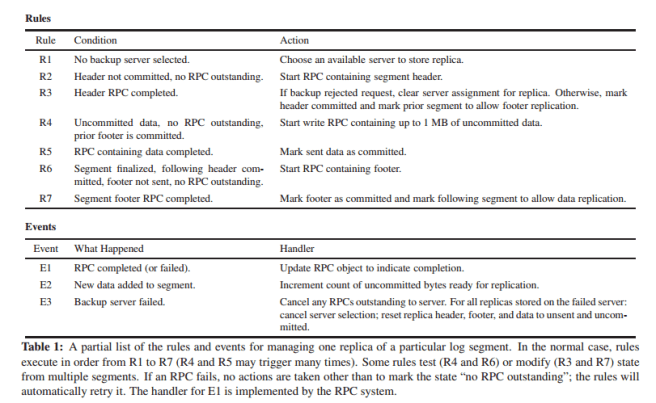
We found it natural to programwith rules because they reflect the inherently nondeterministic structure of the problems being solved. Rules separate the deterministic parts of a module (actions) from the nondeterministic parts (events). Each action implements one of the basic steps of the module. In this problem domain it is difficult to describe all of the control flows from one step to
another, so the rules-based approach does not even try. Instead, it describes the control flow in terms of the conditions that determine when each action executes, independently of how that state was reached. This results in a clean code factoring.
Note that the authors do not recommend the use of a rules-based approach everywhere. “Asynchronous nondeterministic programming is fundamentally more difficult than traditional imperative programming, so it should only be used where it is absolutely necessary.” That said, where you do have a DCFT module, “the introduction of rules usually simplifies the code, and seemingly intractable problems suddenly become tractable.”
The greatest challenge in using rules is to get out of the traditional mental model where an algorithm is defined monolithically. Instead, the algorithm must be defined as a collection of independent small pieces, each of which makes incremental progress towards a goal. These pieces become the actions of rules, and conditions and event handlers are added to invoke the actions appropriately. Our experience is that once a developer adopts this mental model, the actual rule set follows fairly quickly, and it is straightforward to incorporate the rules into the overall system.
Reasoning about the aggregate behaviour of a collection of rules can be complex, “however, we think this problem is inevitable given the non-determinism that the rules must capture.” You can always write a TLA+ spec., which fits very naturally with the rules model, and verify properties that you care about using the TLA+ tools.
Implementation
Tasks provide modularity for rule sets: a task comprises module state, a set of rules, and a goal. The body of a tasks ‘applyRules’ method looks like the pseudo-code we saw earlier.
A DCFT module contains one or more tasks. It operates by repeatedly calling the applyRules methods on its tasks until all tasks have achieved their goals. Events may cause a task to fall out of its goal state (for example, a server may crash, or new data may arrive that requires replication). If this happens, the DCFT module resumes processing rules until all tasks have once again reached their goal states. RAMCloud uses a polling approach, continually testing rules for tasks not in their goal state.
Many DCFT modules contain only a single task. In RAMCloud, each DCFT operates on a single thread and evaluates all of its rules sequentially. Events are asynchronous with respect to the DCFT module so they must synchronize in order to update state. This is done via a traditional locking approach.
Some modules may have many tasks – for example, the replica manager in RAMCloud uses one task for each segment stored on the server (tens of thousands).
Evaluating all of the rules for all of these tasks is prohibitively expensive, so we introduced a pool abstraction to make rule evaluation efficient. A pool is a simple scheduler for a collection of related tasks. Pools reduce the overhead of rule application by dividing tasks into two groups: active tasks, whose rules must be evaluated, and inactive tasks, whose rules can be skipped. A task stays active until it achieves its goal, at which point it becomes inactive. Typically, only a small subset of tasks are active at a time, so testing rules is efficient. Over its life, a single task may be activated and deactivated many times.
RPCs are implemented using futures so that they have a state variable that can be tested to see when the RPC has completed. The conditions for rules in a module test RPCs for completion.
Alternatives
Message-driven
An alternative to asynchronous RPCs would have been to use a messaging approach, with separate request and response messages. However, we found that RPCs produce a cleaner code factoring by allowing more functionality to be implemented transparently in the RPC mechanism; this simplifies the code in DCFT modules.
(I.e., if you really want a request-reply pattern, you don’t want to stitch the messages together yourself every time).
Event-driven State Machines
An event-driven state machine is a system with one or more state variables, whose behavior is determined by events. When an event occurs, the state machine takes actions based on the current state and the event. The actions can alter the state, which affects the way that future events are handled. The state machine definition is broad enough that it includes the rules-based approach as a special case. However, in most state machines the actions are determined directly from the events. Rules use a two-step approach where event handlers only modify state and never take actions. Rules then trigger based on the resulting state, which reflects the sum of the outside events.
The difference between these two approaches is subtle, but the rules-based approach results in a cleaner code factoring.
Actors
Actors, originally conceived in the 1970s, have become popular in recent years for building distributed or concurrent applications. In the actors approach, a program is divided into independent modules with no shared state, called actors, which communicate using asynchronous messages. Actors often handle messages using an approach like that described in Section 8 for event-driven state machines (each actor is a state machine, and messages represent events). However, actors could also use a rules-based approach, and this would be advantageous for actors that implement DCFT modules. We also believe that an asynchronous RPC system would provide a better communication mechanism for DCFT actors than asynchronous messages.

Virding’s First Rule of Programming
Any sufficiently complicated concurrent program in another language contains an ad hoc informally-specified bug-ridden slow implementation of half of Erlang.
http://rvirding.blogspot.com/2008/01/virdings-first-rule-of-programming.html
With the exception that RAMCloud is probably not slow.