Realtime Data Processing at Facebook Chen et al. SIGMOD 2016
‘Realtime Data Processing at Facebook’ provides us with a great high-level overview of the systems Facebook have built to support real-time workloads. At the heart of the paper is a set of five key design decisions for building such systems, together with an explanation of the choices that Facebook made. Before we dive into those, there are two other high-level points I’d like to bring out: the rise of (near) real-time systems, and the importance of ease-of-use.
Streaming versus batch processing is not an either/or decision. Originally, all data warehouse processing at Facebook was batch processing. We began developing [some of our streaming systems] about five years ago… using a mix of streaming and batch processing can speed up long pipelines by hours. Furthermore, streaming-only systems can be authoritative. We do not need to treat realtime system results as an approximation and batch results as “the truth.”
and…
In the last few years, real time processing has proliferated at Facebook.
That’s a trend we’re seeing broadly across the industry.
Regarding ease-of-use, it’s often struck me when reviewing data systems papers that the evaluation sections are full of performance and correctness criteria, but only rarely is there any discussion of how well a system helps its target users achieve their goals: how easy is it to build, maintain, and debug applications?; how easy is it to operate and troubleshoot? Yet in an industry setting, systems that focus on ease of use (even at the expense of some of the other criteria) have tended to do very well. What would happen if a research program put ease of use (how easy is it to achieve the outcome the user desires) as its top evaluation criteria?
It’s great to see Facebook explicitly recognising the importance of this and factoring it into their design decisions:
… We then reflect on lessons we learned over the last four years as we built and rebuilt these systems. One lesson is to place emphasis on ease of use: not just on the ease of writing applications, but also on the ease of testing, debugging, deploying, and finally monitoring hundreds of applications in production.
A final introductory observation – it strikes me that as data processing platforms move towards streaming and soft-real time constraints, and application architectures move towards collections of composed services (and especially if you also consider event-driven styles) that the two are moving much closer together than ever before. Both aggregate collections of functions connected in a directed graph with data flowing between them, both may join with data from stores and other systems. For data processing the functions are connected in a DAG, for application components with a requirement to generate a response it may not be acyclic. But other than that, if you squint a bit…. could we one day see an interesting converged architecture?
A menagerie of data systems
The paper kicks off with a high-level overview of the different realtime data processing systems at Facebook: there are a lot of them, and that’s by design as we will shortly see.
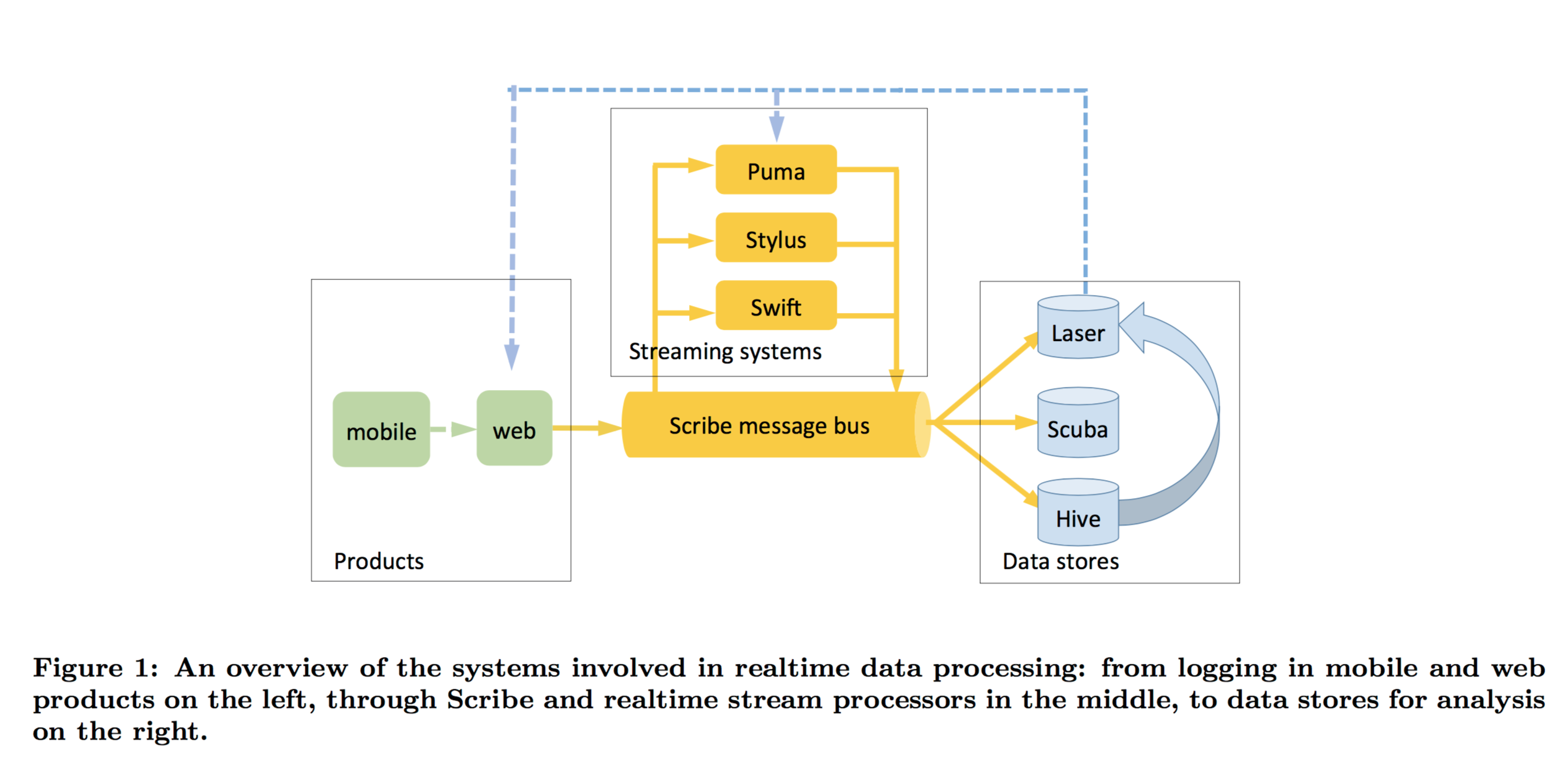
- Scribe is a persistent distributed messaging system that organises data in categories (which sound very much like topics). Categories can be split into multiple buckets, and a bucket is the unit of workload assignment. Data is stored in HDFS and can be replayed for ‘up to a few days.’
- Puma enables stream processing applications to be written in a SQL-like language with Java UDFs. The point of Puma apps is that they are quick to write – “it can take less than an hour to write, test, and deploy a new app.”
- Swift enables stream processing applications to be written in scripting languages (typically Python). It offers a very simple API and also provides checkpointing. Swift is most useful for low-level stateless processing.
- Stylus is for heavy-lifting stream applications and supports applications written in C++.
- Laser is a high throughput, low latency key-value store built on top of RocksDB. It can read from Scribe categories, and serve data to Laser, Puma, and Stylus apps.
- Scuba is an analytics data store, “most commonly used for troubleshooting problems as they happen.” Scuba can ingest millions of rows per second from Scribe, Puma, Sylus, and Swift. It provides ad-hoc querying with response times under 1 second.
- Hive is used as Facebook’s exabyte scale data warehouse:
Facebook generates multiple new petabytes of data per day, about half of which is raw event data ingested from Scribe. (The other half of the data is derived from the raw data, e.g. by daily query pipelines).
Five design decisions for real-time streaming systems
How did Facebook end up with this set of systems? The heart of the paper is a collection of five design decisions to be considered when putting together a real-time stream processing system. The Facebook systems taken together provide a good coverage of this design space.
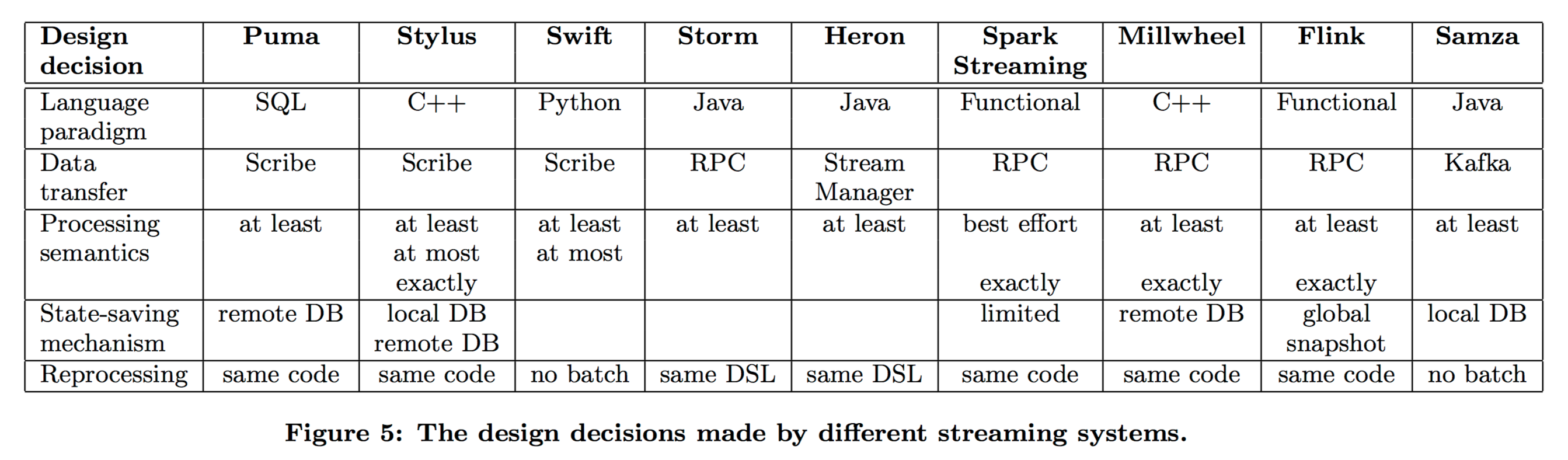
The design decisions are:
- What language will people use to write applications for the system? A declarative style (e.g. SQL); a functional style; or a procedural style?
- How will data be transferred between nodes? By direct message transfer (e.g. RPC), via a message broker, or by a persistent store acting as intermediary?
- What semantics are provided for stream processors? This is broken down into guarantees on input events (at least once, at most once, exactly once) and outputs (at least once, at most once, exactly once).
- What mechanism(s) are provided for saving state at stateful processors? Choices include replication, local database persistence, remote database persistence, upstream backups, and globally consistent snapshots.
- How is re-processing of old data supported? (Useful for testing applications against old data, generating historical metric information when a new metric is developed, or simply reprocessing data where the results have been affected by a bug). The choices include stream only replay, the maintenance of separate batch and streaming systems, or developing stream processing systems that can also run in a batch environment.
Here’s how Facebook’s systems (and a few selected external systems) stack up against these criteria:
(click on image for larger view)
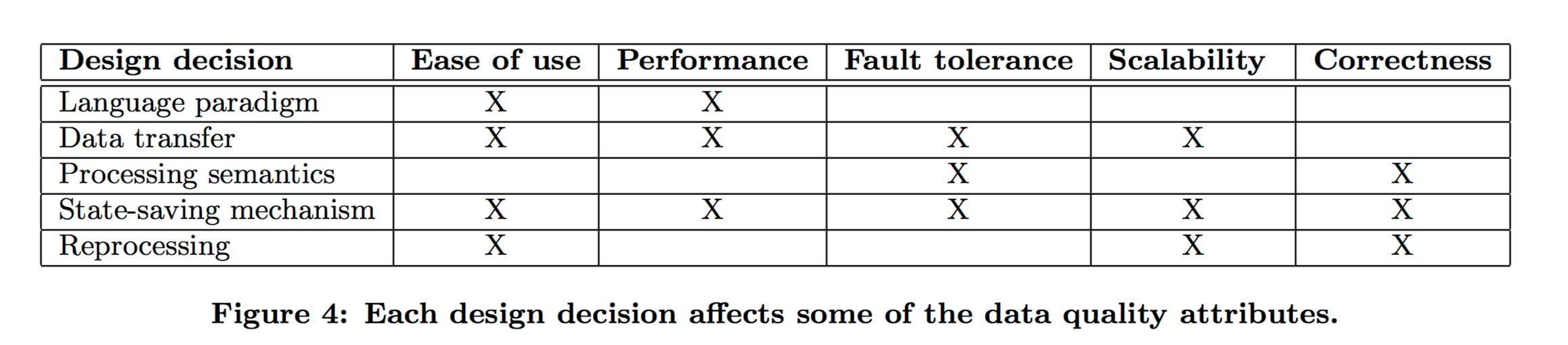
The authors highlight five important qualities we want from a streaming system: ease of use, performance, fault-tolerance, scalability, and correctness. The design decisions also have an impact on these qualities, as indicated by the following table:
(click on image for larger view)
Here’s how each of these design decisions have been handled within Facebook’s overall real-time streaming platform.
Language paradigm
In our environment at Facebook, there is no single language that fits all use cases. Needing different languages (and the different levels of ease of use and performance they provide) is the main reason why we have three different stream processing systems.
As an example, a Puma app can be written and tested in under an hour, and Swift applications are easy to prototype and are useful for low-throughput stream processing apps. Currently Facebook don’t have anything supporting the functional paradigm, “although we are exploring Spark Streaming.”
Data transfer mechanism
Scribe is used for all data transfer. This imposes a minimum latency of about one second per stream. Scribe also requires a persistent backing store which it writes to asynchronously. Realising that this is acceptable for Facebook’s use cases gives other benefits in terms of fault-tolerance, ease-of-use, scalability, and performance (see §4.2.2 for more details).
Given the advantages above, Scribe has worked well as the data transfer mechanism at Facebook. Kafka or another persistent store would have similar advantages. We use Scribe because we develop it at Facebook.
Processing semantics
In Facebook’s environment, different applications often have different state and output semantics requirements.
Embracing these differences enables efficiency gains for applications that don’t need the stronger guarantees. Common desired combinations of output and state semantics are shown below:
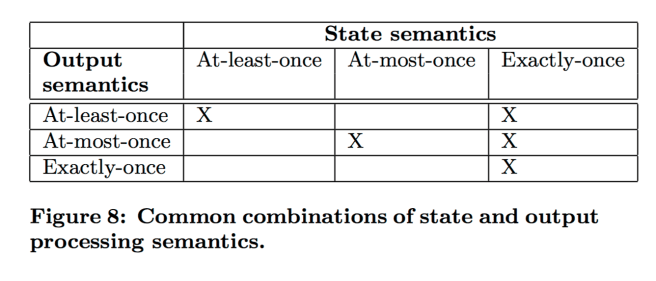
Stylus provides all of these. For at-most-once output semantics, it is possible to avoid buffering events before generating output and saving a checkpoint, if the processor can do side-effect-free processing.
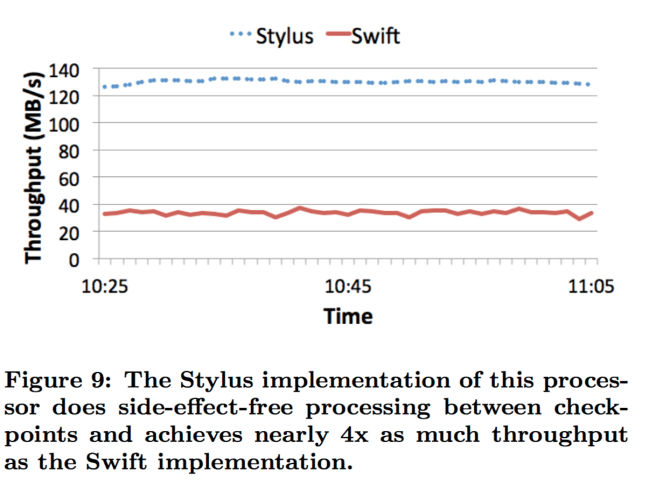
We now examine the benefits of overlapping side-effect-free processing with receiving input for at-most-once output semantics. Figure 9 (below) shows the throughput for two different implementations of the Scuba data ingestion processor. Both implementations have at-most-once output semantics. The Swift implementation buffers all input events between checkpoints, which occur approximately every 2 seconds. Then it processes those events and sends its output to the Scuba servers. While it is waiting for the checkpoint, the processor’s CPU is underutilized. The Stylus implementation does as much side-effect-free work as it can between checkpoints, including deserialization of its input events. Since deserialization is the performance bottleneck, the Stylus processor achieves much higher CPU utilization. The Stylus processor, therefore, achieves nearly four times the throughput of the Swift processor: in Figure 9 we see 135 MB/s versus 35 MB/s, respectively.
State saving
Stylus support saving state to a local or remote database. Saving state to a local RocksDB database is easy to set up, and attractive for many Facebook users. RocksDB is embedded in the same process as the stream processor, and the in-memory state is saved to the local db at fixed intervals.
The local database is then copied asynchronously to HDFS at a larger interval using RocksDB’s backup engine. When a process crashes and restarts on the same machine, the local database is used to restore the state and resume processing from the checkpoint. If the machine dies, the copy on HDFS is used instead.
The remote database option can hold state that doesn’t fit in memory, and offers faster failover. When the store is also used for saving state, then state will be read from the remote database (if it is not already in memory), updated, and then written back…
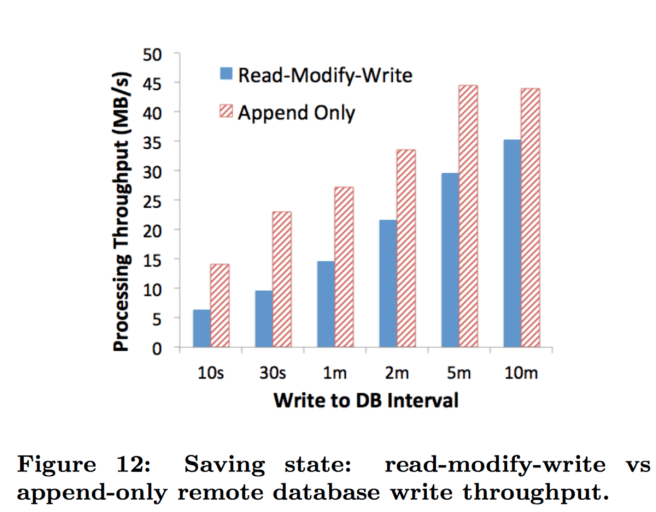
This read-modify-write pattern can be optimized if the states are limited to monoid processors. A monoid is an algebraic structure that has an identity element and is associative. When a monoid processor’s application needs to access state that is not in memory, mutations are applied to an empty state (the identity element). Periodically, the existing database state is loaded in memory, merged with the in-memory partial state, and then written out to the database asynchronously. This read-merge-write pattern can be done less often than the read-modify-write. When the remote database supports a custom merge operator, then the merge operation can happen in the database. The read-modify-write pattern is optimized to an append-only pattern, resulting in performance gains. RocksDB and ZippyDB support custom merge operators. We illustrate the performance gains in Figure 12…
Backfill processing
Scribe only provides short-term (a few days) retention, and longer term storage of input and output streams is handled by Hive. Older data is processed using standard MapReduce – Puma applications run in Hive as Hive UDFs, but for Stylus a different approach is used:
When a user creates a Stylus application, two binaries are generated at the same time: one for stream and one for batch. The batch binary for a stateless processor runs in Hive as a custom mapper. The batch binary for a general stateful processor runs as a custom reducer and the reduce key is the aggregation key plus event timestamp. The batch binary for monoid processors can be optimized to do partial aggregation in the map phase.
Lessons learned
- Having multiple different systems helps Facebook move fast. “Writing a simple application lets our users deploy something quickly and prove its value first, then invest the time in building a more complex and robust application.”
- Having the ability to replay streams is a big help when debugging.
- “Writing a new streaming application requires more than writing the application code. The ease or hassle of deploying and maintaining the application is equally important. Laser and Puma apps are deployed as a service. Stylus apps are owned by the individual teams who write them, but we provide a standard framework for monitoring them.” Making Puma apps self-service was key to scaling to the hundreds of data pipelines using Puma today.
- Use alerts to detect when an app is processing its input more slowly than the input is being generated. In the future Facebook plan to scale apps automatically under these conditions.
- Streaming versus batch processing does not need to be an either/or decision.
- Ease of use is as important as the other qualities. In addition to development, making debugging, deployment, and operational monitoring easy has greatly increased the adoption rate of Facebook’s systems.
- There is a spectrum of correctness, and not all use cases need ACID semantics:
By providing choices along this spectrum, we let the application builders decide what they need. If they need transactions and exactly-once semantics, they can pay for them with extra latency and hardware. But when they do not – and many use cases are measuring relative proportions or changes in direction, not absolute values – we enable faster and simpler applications.

Scribe works fairly well, but it has minimal guarantees and a very simple flow control protocol, so it gets into things like undetectable resends of the same data, and backups due to minor issues in a downstream store. It does get high performance though, and it stays within its memory and cpu footprint on app servers.
Its routing is simply based on category, which is a low-cardinality string used to distinguish endpoints. Each instance has a config file which is a static set of routing rules based on category, and scribed dispatches everything from its input buffer to these next-hop destinations. There’s no real global routing, although I think there are control frameworks that wrap around it and manage that.
I’m surprised they didn’t mention Vertica as one of their endpoints; their recruiter mentions it to me all the time :).