SVE: Distributed video processing at Facebook scale Huang et al., SOSP’17
SVE (Streaming Video Engine) is the video processing pipeline that has been in production at Facebook for the past two years. This paper gives an overview of its design and rationale. And it certainly got me thinking: suppose I needed to build a video processing pipeline, what would I do? Using one of the major cloud platforms, simple video uploading encoding, and transcoding is almost a tutorial level use case. Here’s A Cloud Guru describing how they built a transcoding pipeline in AWS using Elastic Transcoder, S3, and Lambda, in less than a day. Or you could use the video encoding and transcoding services in Google Cloud Platform. Or Microsoft Azure media services. Which is a good reminder, when you look at what’s involved in building SVE, that “you are not Facebook.” Somewhere on the journey from simple and relatively small scale video upload and processing, to Facebook scale (tens of millions of uploads/day – and presumably growing fast) it starts to make sense to roll-your-own. Where is that handover point? (And by the time you reach it remember, the cloud platforms will be even more capable than they are today). Let’s take a look at the situation inside of Facebook to get our bearings.
Video at Facebook
At Facebook, we envision a video-first world with video being used in many of our apps and services. On an average day, videos are viewed more than 8 billion times on Facebook. Each of these videos needs to be uploaded, processed, shared, and then downloaded.
There are more than 15 different applications at Facebook that integrate video, which collectively ingest tens of millions of uploads and generate billions of video processing tasks. You’ve probably heard of some of those apps ;), which include:
- Facebook video posts
- Messenger videos
- Instagram stories
- 360 videos (recorded on 360 cameras and processed to be consumed by VR headsets or 360 players)
Beyond encoding and transcoding, it turns out there’s a lot more processing going on with those videos:
Many apps and services include application-specific video operations, such as computer vision extraction and speech recognition.
In fact, the DAG for processing Facebook video uploads averages 153 video processing tasks per upload! Messenger videos which are sent to a specific friend or group for almost real-time interaction have a tighter processing pipeline averaging just over 18 task per upload. The Instagram pipeline has 22 tasks per upload, and 360 videos generate thousands of tasks. (These numbers include parallel processing of video segments).
Reading through the paper, it becomes clear that the one metric that matters at Facebook when it comes to video is time to share. How long does it take from when a person uploads (starts uploading) a video, to when it is available for sharing?
This leads to three major requirements for the video processing pipeline at Facebook:
- Low latency
- Flexibility to support a range of different applications (with custom processing pipelines)
- Handle system overload and faults
How Facebook used to process video
Prior to SVE, Facebook used to process video with ‘MES’ – a Monolithic Encoding Script. As you can imagine, that was hard to maintain and monitor in the presence of multiple different and evolving applications requirements for encoding and transcoding. But most importantly, it used a batch-oriented sequential processing pipeline. A file is uploaded and stored, this then triggers processing, and when processing is complete the results are written to storage again and become available for sharing. That doesn’t sound too different to what you might put together with S3, Lambda, and Elastic Transcoder.
The pre-sharing video pipeline comprises on-device recording, uploading, validation (is the file well formed, reparation where possible), re-encoding in a variety of bitrates, and storing in a BLOB storage system.
The major issue with MES is it has a poor time-to-share. Just uploading can take minutes (with 3-10MB videos, over 50% of uploads take more than 10 seconds, and with larger video sizes we are easily into the minutes and even 10s of minutes). The encoding time for larger videos is also non-trivial (again, measured in minutes). Even the time required to durably store a video makes a meaningful contributed to the overall latency. Batch is the enemy of latency.
Introducing SVE
The central idea in SVE is to process video data in a streaming fashion (strictly, mini-batches), in parallel, as videos move through the pipeline.
SVE provides low latency by harnessing parallelism in three ways that MES did not. First, SVE overlaps the uploading and processing of videos. Second, SVE parallelizes the processing of videos by chunking videos into (essentially) smaller videos and processing each chunk separately in a large cluster of machines. Third, SVE parallelizes the storing of uploaded videos (with replication for fault tolerance) with processing it.
The net result is 2.3x-9.3x reduction in time-to-share compared to MES. Knowing what we do about the impact of user-perceived performance on business metrics, my bet would be that this makes a very material difference to Facebook’s business.
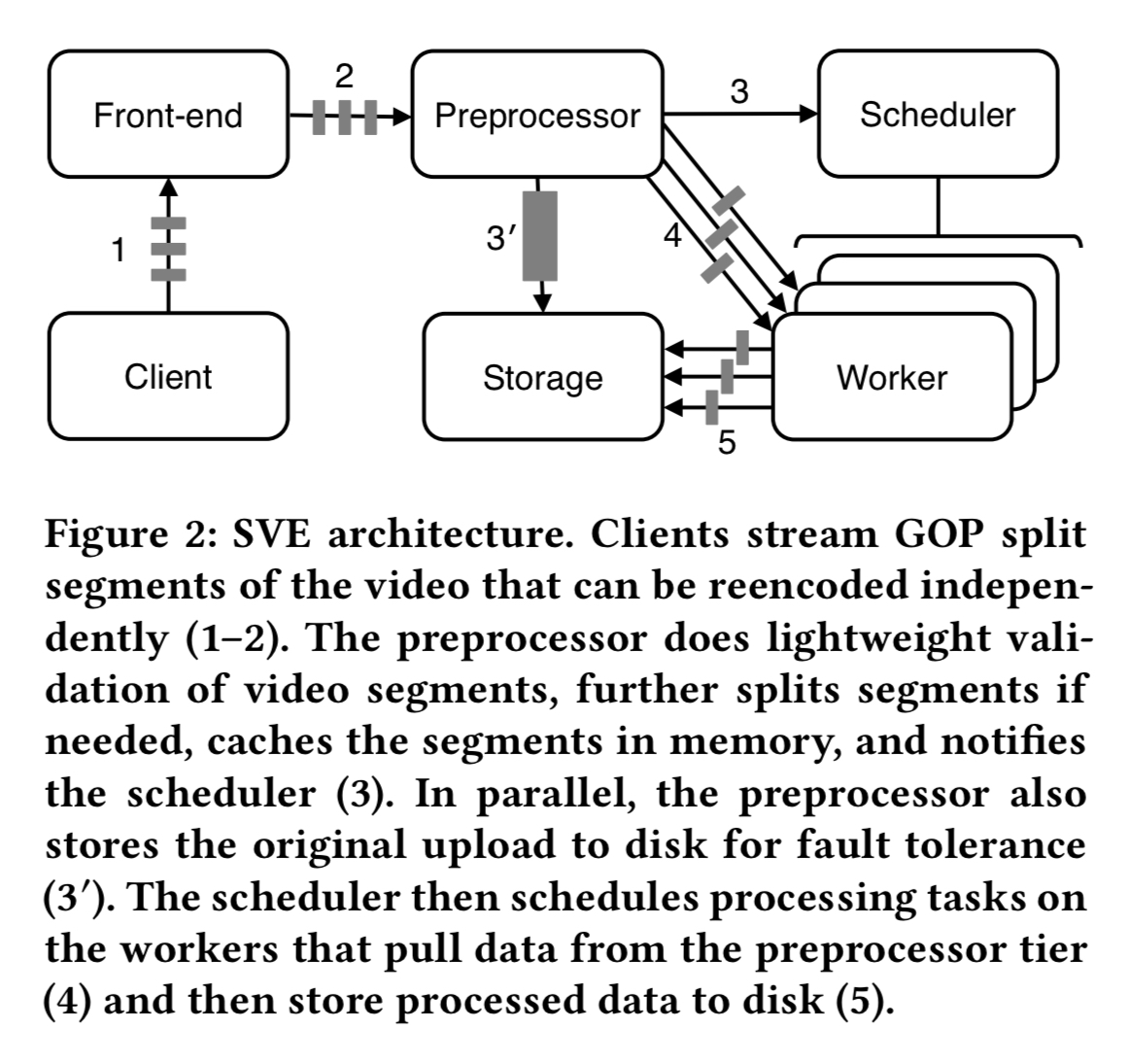
SVE breaks videos into chunks called GOPs (group of pictures). Where possible, this is done on the client device. Each GOP in a video is separately encoded, so that each can be decoded without referencing earlier GOPs. During playback, these segments can be played independently of each other.
The video chunks are then forwarded straight to a preprocessor (rather than to storage as in the old system). The preprocessor submits encoding jobs to a distributed worker farm via a scheduler, in parallel with writing the original video to storage. As part of submitting jobs to the scheduler, the preprocessor dynamically generates the DAG of processing tasks to be used for the video. Worker processes pull tasks from queues. There’s a simple priority mechanism – each cluster of workers has a high-priority queue and a low-priority queue. When cluster utilisation is low they pull from both queues, under heavier load they pull only from the high-priority queue.
You can probably imagine what such a system looks like – the details are in the paper, but it follows pretty much what you would expect. So in the remaining space, I want to highlight a few areas I found interesting: the motivation for building a whole new data processing system rather than reusing an existing one; the DAG execution system; and the approaches used to deal with heavy load and failures.
Why not just use X?
Before designing SVE we examined existing parallel processing frameworks including batch processing systems and stream processing system. Batch processing systems like MapReduce, Dryad, and Spark all assume the data to be processed already exists and is accessible… Streaming processing systems like Storm, Spark Streaming, and StreamScope overlap uploading and processing, but are designed for processing continuous queries instead of discrete events.
The former don’t optimise for time-to-sharing, the latter don’t support the overload control policies and custom DAG per-task model that Facebook wanted: “we found that almost none of our design choices, e.g., per-task priority scheduling, a dynamically created DAG per video, were provided by existing systems.”
A video processing programming model based on DAGs
As the paper hints at, video processing at Facebook includes reencoding, but is certainly not limited to that. There may be video analysis and classification, speech-to-text translation and all sorts of other processing steps involved.
Our primary goal for the abstraction that SVE presents is to make it as simple as possible to add video processing that harnesses parallelism. In addition, we want an abstraction that enables experimentation with new processing, allows programmers to provide hints to improve performance and reliability, and that makes fine-grained monitoring automatic. The stream-of-tracks abstraction achieves all of these goals.
The stream of tracks abstraction provides two dimensions of granularity: tracks within a video (e.g., the video track and the audio track), and GOP-based segments within a video. Some tasks can be specified to operate on just a single track (e.g. speech-to-text), or a single segment. Others may operate on the full video (e.g., computer vision based video classification). Programmers write tasks that execute sequentially over their inputs, and connect them into a DAG.
Here’s a simplified view of the Facebook app video processing DAG:
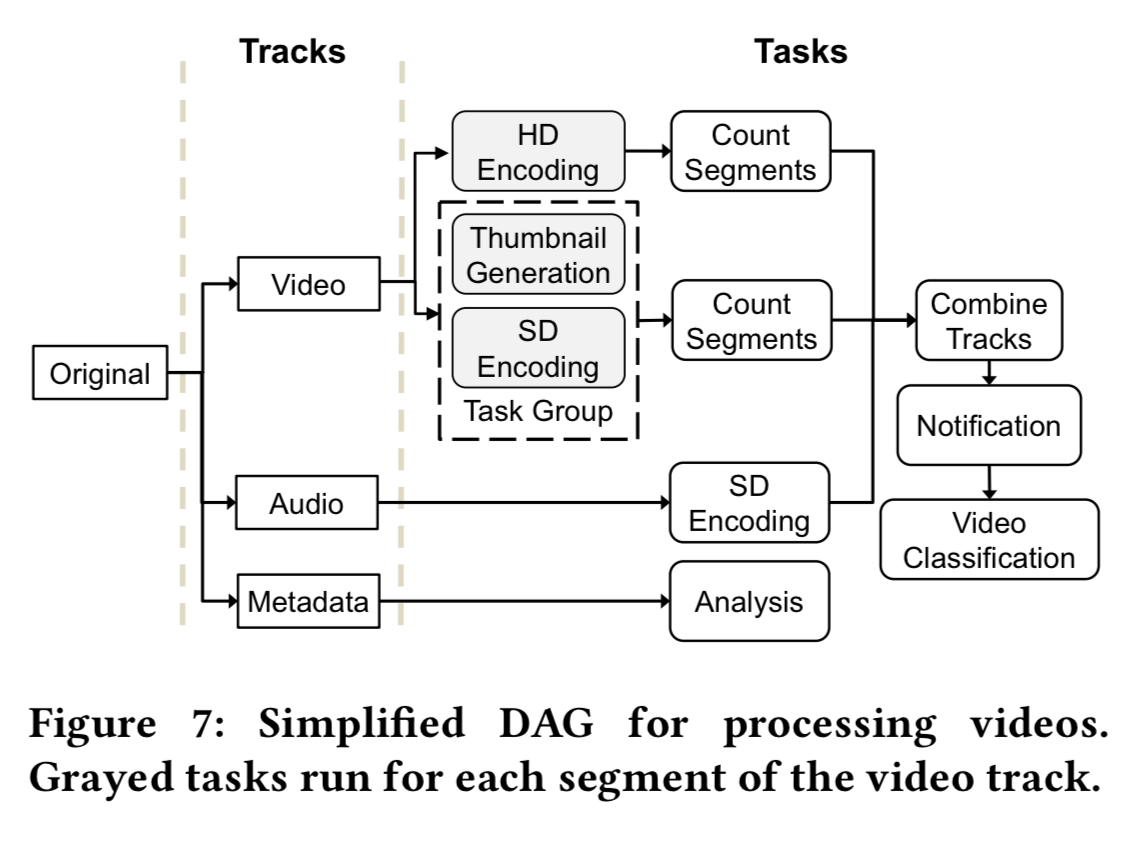
The initial video is split into video, audio, and metadata tracks. The video and audio tracks are then duplicated n times, once for each encoding bitrate, and the encoding tasks operate in parallel over these. The output segments across tracks are then joined for storage.
Pseudo-code for generating the DAG looks like this:

Dynamic generation of the DAG enables us to tailor a DAG to each video and provides a flexible way to tune performance and roll out new features. The DAG is tailored to each video based on specific video characteristics forwarded from the client or probed by the preprocessor. For instance, the DAG for a video uploaded at a low bitrate would not include tasks for re-encoding the video at a higher bitrate.
Azure Media Services has a “premium encoding” option that also gives you the ability to define your own encoding workflows. AWS Elastic Transcoder supports ‘transcoding pipelines.’ GCP gets a fail here because I couldn’t easily find out from the public documentation what capabilities they have here – everything seems to be hidden behind a ‘Contact Sales’ link. (Maybe the info is available of course, it could just be a search failure on my part).
Fault tolerance and overload control
There’s quite a bit of interesting material here, and I’m almost out of space, so for more details please see sections 6 and 7 in the full paper. I will just highlight here the retry policy on failure. A failed task will be tried up to 2 times locally on the same worker, then up to 6 more times on another worker – leading to up to 21 execution attempts before finally giving up.
We have found that such a large number of retries does increase end-to-end reliability. Examining all video-processing tasks from a recent 1-day period shows that the success rate excluding non-recoverable exceptions on the first worker increases from 99.788% to 99.795% after 2 retries; and on different workers increases to 99.901% after 1 retry and 99.995% ultimately after 6 retries.
Logs capture that re-execution was necessary, and can be mined to find tasks with non-negligible retry rates due to non-deterministic bugs.
Overload by the way comes from three sources: organic (e.g. social events such as the ice-bucket challenge); the load-testing system due to Kraken; and bug-induced overload.
The last word:
SVE is a parallel processing framework that specializes data ingestion, parallel processing, the programming interface, fault tolerance, and overload control for videos at massive scale.
If you envision a video-first world, and content sharing at scale is what you do, then all this specialism really can be worth it.
