
DQBarge: Improving data-quality tradeoffs in large-scale Internet services Chow et al. OSDI 2106
I’m sure many of you recall the 2009 classic “The Datacenter as a Computer,” which encouraged us to think of the datacenter as a warehouse-scale computer. From being glad simply to have such a computer, the bar keeps on moving. We don’t just run workloads on that computer, increasingly we’re programming advanced functionality into the warehouse-scale computer OS itself. Morhpeus and Firmament that we looked at last week are good examples of that trend. Today’s paper describes DQBarge, another example of programming at the datacenter OS level. It shifts the decision to make data-quality trade-offs when servicing requests from a primarily reactive local component decision to a proactive globally informed one. As we’ll see, the benefits are significant in terms of response times, scalability, and quality of results. There’s plenty of evidence to suggest that companies which invest in advancing their warehouse scale computer OS can gain a significant competitive advantage in terms of their cloud computing unit economics.
Let’s take a look at DQBarge.
A data-quality tradeoff is an explicit decision made by a sofware component to return lower-fidelity data in order to improve response time or minimize resource usage.
That sounds a bit abstract… what we’re talking about here is things like request timeouts resorting to returning default values, aggregate queries that omit results from stragglers, and so on. The first part of the paper is fascinating in its own right as a study of the prevalence and types of data quality trade-offs being made within Facebook. The second part of the paper introduces DQBarge, which builds offline models representing the expected payoffs from different trade-offs, and then helps components make online contextual decisions about which trade-offs to actually make at different points in time. The final part of the paper shows the benefits that derive from a system like DQBarge. Here’s a really simple example that makes intuitive sense: making requests that timeout and thus don’t have their responses included in results is a waste of resource – if we could proactively decide not to make the request in the first place, we could put that resource to more profitable use elsewhere.
Data quality trade-offs at Facebook
The team studied 463 different client applications/services of a particular back-end service at Facebook called Laser. Over 90% of all clients perform some kind of data quality tradeoff, and the ones that don’t usually consider the failure to retrieve data in a timely manner to be a fatal error.
Thus, in the Facebook environment, making data-quality tradeoffs is normal behavior, and failures are the exception.
The most common trade-offs are simply to omit the requested value from the calculation of an aggregate and to use a default value in lieu of the requested data. Nearly all clients are reactive – that is they respond to request failures or timeouts.
Only 6% of the top 50 clients and 2% of all clients are proactive. The lack of proactivity represents a significant lost opportunity for optimization because requests that timeout or fail consume resources but produce no benefit. This effect can be especially prominent when requests are failing due to excessive load; a proactive strategy would decrease the overall stress on the system.
How might better data-quality trade-offs help?
- During load spikes, making better data quality tradeoffs can maintain end-to-end latency goals while minimizing the loss in fidelity perceived by users.
- When load levels permit, components with slack in their completion time can improve the fidelity of the response without impacting end-to-end latency.
- Understanding the potential effects of low-level data-quality tradeoffs can inform dynamic capacity planning and maximize utility as a function of the resources required to produce output.
A high-level tour of DQBarge
DQBarge has an offline and an online component.
During the offline stage, it samples a small percentage of production requests, and it runs a copy of each sampled request on a duplicate execution pipeline. It perturbs these requests by making specific data quality tradeoffs and measuring the request latency and result quality. DQBarge generates performance and quality models by systematically sweeping through the space of varying request load and data provenance dimensions specified by the developer and using multidimensional linear regression over the data to predict performance and quality as a factor of load and provenance.
Performance models predict how throughput and latency are affected by specific data-quality tradeoffs as a factor of overall system load and the provenance of input data. Quality models capture how the fidelity of the final response is affected by specific tradeoffs as a function of provenance.
In the online stage these models are used to decide when to make data-quality tradeoffs for production traffic. It does this by gathering the inputs needed by the models (load levels, critical path predictions, and provenance of data) and propagating them along the critical path of request execution by piggy-backing on RPC requests. The DBBarge software service makes data quality tradeoffs _proactively, and stores these decisions for later analysis.
Unfortunately, developer co-operation is required to add the necessary instrumentation…
Our library provides a useful interface for manipulating RPC objects, but developers must still make domain-specific decisions, e.g., what metrics and performance values to add, and what rules to use to model the propagation of provenance…
In the case studies though, a single developer previously unfamiliar with the systems being used was able to make all needed modifications in less than 450 lines of code.
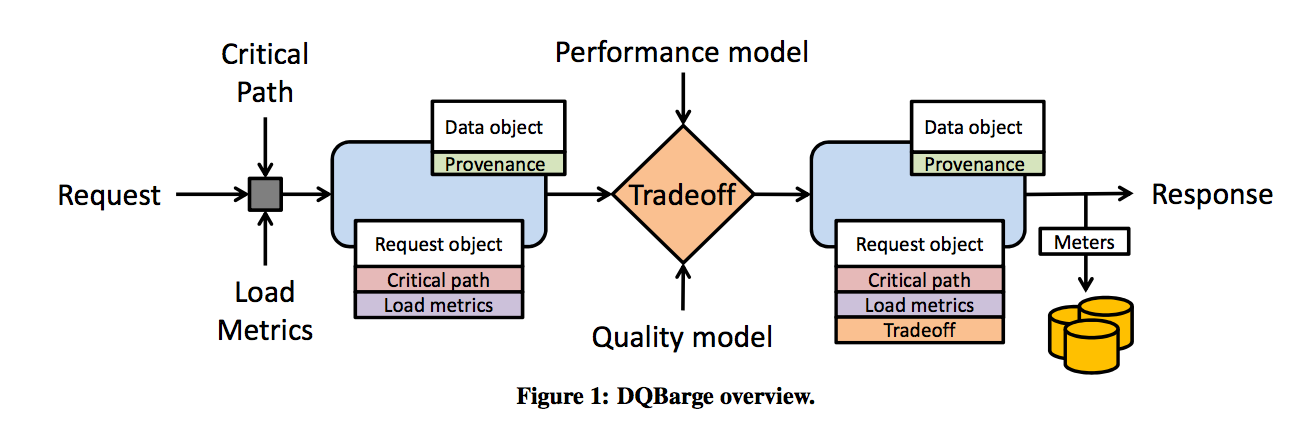
Critical path and slack predictions come from The Mystery Machine.
System operators specify a high-level goal such as maximizing quality given a latency cap on request processing. Components call functions such as makeAggregationTradeoff at each potential tradeoff point during request processing…
DQBarge supports three types of high-level goals:
- Maximizing quality subject to a latency constraint
- Maximizing quality using slack execution time available during request processing
- Maximizing utility as a function of quality and performance.
The first two should be fairly self-explanatory (see The Mystery Machine for a good discussion of the concept of slack). The last one is worth a little more explanation, although it requires a fairly sophisticated end-user to take advantage of it:
DQBarge allows operators to specify the utility (e.g. the dollar value) of reducing latency and improving quality. It then selects the tradeoffs that improve utility until no more such tradeoffs are available. DQBarge also allows operators to specify the impact of adding or removing resources (e.g. compute nodes) as a utility function parameter. DQBarge compares the value of the maximum utility function with more and less resources and generates a callback if adding or removing resources would improve the current utility.
Evaluation
The authors studied the impact of DQBarge in a portion of the Facebook request processing pipeline known as Ranker for the purposes of publication, and in the Sirius open-source personal digital assistant.
Data-quality tradeoffs substantially reduce latency of Ranker at low loads (e.g. at a 30% tradeoff rate, median latency reduces by 28% and 99th percentile by 30%). Under load, Ranker can process approximately 2500 requests per minute without tradeoffs, and 4300 requests per minute with them.

At a tradeoff rate of 10%, using provenance reduces the percentage of requests that experience any quality drop at all from 11% to 6%. At a tradeoff rate of 50% using provenance decreases the percentage of requests that see any quality drop at all from 43% to 33%
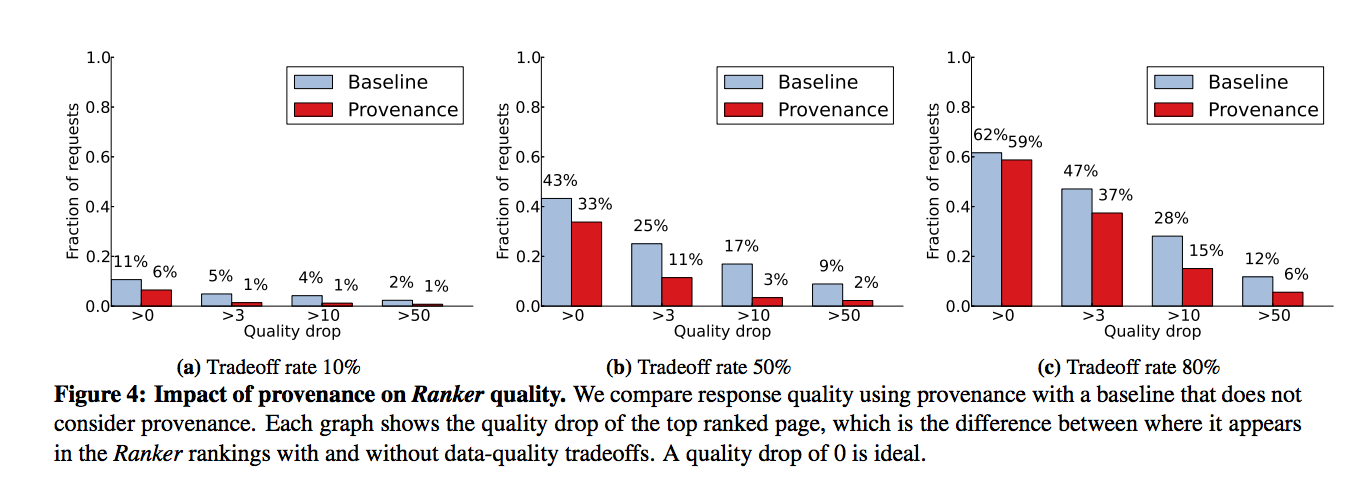
Using the Sirius case study, the team found that:
DQBarge proactivity simultaneously improves both performance and quality when making tradeoffs.
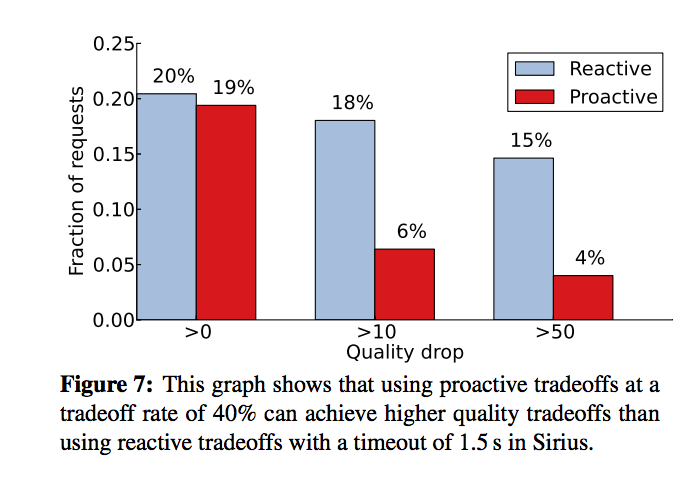
It also provides a much better ability to cope with load spikes:
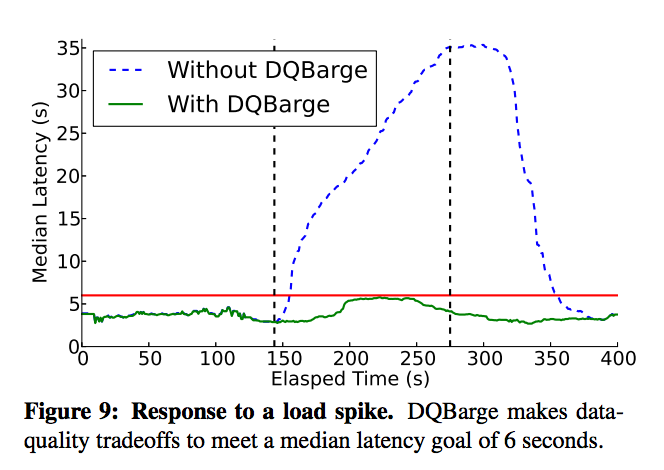
See the full paper for a much more detailed analysis.
In this paper we showed that data-quality tradeoffs are prevalent in Internet service pipelines through a survey of existing software at Facebook. We found that such tradeoffs are often suboptimas because they are reactive and because they fail to consider global information… Our evaluation shows that [DQBarge] improves responses to load spikes, utilization of spare resources, and dynamic capacity planning.
