XFT: Practical fault-tolerance beyond crashes Liu et al., OSDI 2016
Here’s something that’s been bugging me for a while now. The state of the art in security has moved from the assumption of a secured perimeter and a trusted environment inside the firewall to a notion of perimeter-less security. It’s pretty much impossible to keep track of all the bridged networks (e.g., from smartphones) and other ways of getting into a corporate network (connected printers, …), so the assumption becomes that all services ‘live on the internet’ and it’s necessary to secure them at the application level. At the same time, the system model on which pretty much all of our distributed systems are designed assumes a classic ‘crash fault tolerance’ (CFT) model. In other words, these systems at their core are not designed to tolerate active adversaries – they come from the world of perimeter-based thinking. Can you spot the problem?
There does exist a strong body of research looking into Byzantine Fault-Tolerant (BFT) systems, but these aren’t widely deployed because of the overheads involved. I was particularly pleased therefore to discover this paper from Liu et al., looking at a fault-tolerance model called cross fault tolerance (XFT) which sits somewhere between CFT and BFT, and seems very well matched to today’s deployment scenarios. The best part is that it offers performance equivalent to CFT systems, but with much stronger protections.
Modern production systems increase the number of nines of reliability by employing sophisticated distributed protocols that tolerate crash machine faults as well as network faults… At the heart of these systems typically lies a crash-fault tolerant (CFT) consensus-based state-machine replication (SMR) primitive. [Think Paxos, Raft,…]. These systems cannot deal with non-crash (or Byzantine) faults, which include not only malicious adversarial behavior, but also arise from errors in the hardware, stale or corrupted data from storage systems, memory errors caused by physical effects, bugs in software,… and human mistakes.
XFT is another fine example of questioning assumptions: are the preconditions for CFT met in modern deployments? (Increasingly, no), and exposing a false dichotomy (you can have CFT, or BFT).
The overhead of asynchronous BFT is due to the extraordinary power given to the adversary, which may control both the Byzantine faulty machines and the entire network in a coordinated way. In particular, the classical BFT adversary can partition any number of otherwise correct machines at will. In line with observations by practitioners, we claim that this adversary model is actually too strong for the phenomena observed in deployed systems.
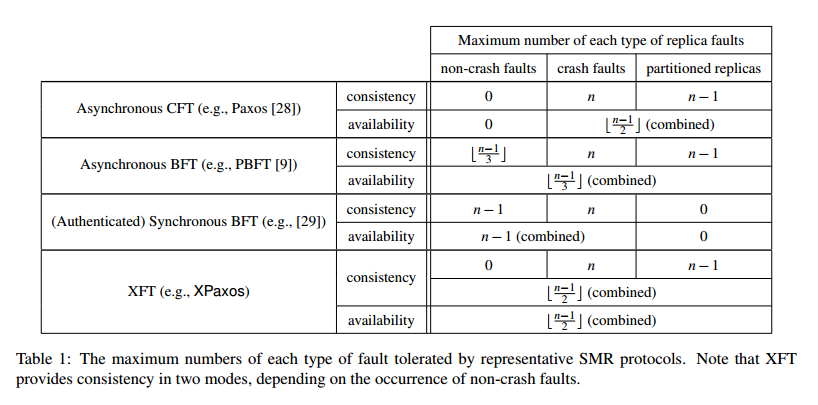
XFT is designed to provide correct service (i.e., safety and liveness) even when Byzantine faults do occur, as long as a majority of replicas are correct and can communicate with each other synchronously (a minority of the replicas are Byzantine-faulty, or partitioned due to a network fault). In return it uses only the same number of resources (replicas) as asynchronous CFT (typical BFT systems need more), and preserves all the reliability guarantees of asynchronous CFT systems.
Whereas XFT always provides strictly stronger consistency and availability guarantees than CTF and always strictly stronger guarantees than BFT, our reliability analysis shows that, in some cases, XFT also provides strictly stronger consistency guarantees than BFT.
(Click for larger view).
The authors envision XFT being particularly suitable for wide-area or geo-replicated systems, or any other deployment where an adversary cannot easily coordinate enough network partitions and Byzantine-faulty machine actions at the same time. Note however that many geo-replicated systems don’t use even CFT consensus algorithms across regions (certainly not for the normal request processing path) due to the latencies involved, preferring stronger consensus within regions, and weaker consensus across regions. Another potential use case is permissioned blockchains.
The more formal definition of XFT is as follows:
- Let anarchy be a severe system condition in which there is at least one non-crash-faulty replica and the number of non-crash-faulty replicas + the number of crash-faulty replicas + the number of correct, but partitioned replicas is greater than some threshold t (t ≤ (n-1)/2) for n replicas.
- Then, protocol P is an XFT protocol if P satisfies safety in all executions in which the system is never in anarchy.
XPaxos
XPaxos is a Paxos derivative built using the XFT assumptions.
XPaxos is a novel state-machine replication (SMR) protocol designed specifically in the XFT model. XPaxos specifically targets good performance in geo-replicated settings, which are characterized by the network being the bottleneck, with high link latency and relatively low, heterogenous link bandwidth.
XPaxos has three main components:
- A common-case protocol which handles the replication and total ordering of requests across replicas. This looks much like phase 2 of Paxos, but hardened by the use of digital signatures.
- A view-change protocol that operates in a decentralized, leaderless fashion.
- A fault-detection mechanism which can help detect, when outside anarchy, non-crash faults that would leave the system in an inconsistent state in anarchy.
In the interests of space, I’m going to concentrate here on the novel view-change protocol and the fault-detection mechanism.
[The XPaxos] decentralized approach to view change stands in sharp contrast to the classical reconfiguration/view-change in CFT and BFT protocols, in which only a single replica leads the view change and transfers the state from previous views. This difference is crucial to maintaining consistency across XPaxos views in the presence of non-crash faults (but in the absence of full anarchy).
XPaxos enforces consistency across view changes using the ordered requests in the commit logs of correct replicas. Consider a view change moving from synchronous group i (sgi) to synchronous group i+1 (sgi+1). Every active replica in sgi+1 retrieves information about requests committed in previous views.
Intuitively, with a correct majority of correct and synchronous replicas, at least one correct and synchronous replica from sgi+1 will contact (at least one) correct and synchronous replica from sgi and transfer the latest correct commit log to the new view i+1.
A view change is initiated whenever a synchronous group is deemed not to be making progress or has suspicious activity. In particular, a view change can be initiated (by sending a SUSPECT message) by an active replica if any of the following conditions hold:
- it receives a message from another active replica that does not conform to protocol.
- a retransmission timer expires.
-
a view change does not complete in a timely manner.
-
a SUSPECT message is received from another replica the current group
Each active replica in the new view collects the most recent state and its proof (VIEW-CHANGE messages). An active replica in the new view waits for at least 2Δ time (timeout), and must collect at least n-t VIEW CHANGE messages within that window for a view change to succeed.
The fault detection (FD) subprotocol guarantees that if a machine p suffers a non-crash fault outside anarchy in a way that would cause inconsistency under anarchy then p will be detected as faulty.
Our FD mechanism entails modifying the XPaxos view change as follows: in addition to exchanging their commit logs, replicas also exchange their prepare logs. Notice that in the case t = 1 only the primary maintains a prepare log. In the new view, the primary prepares and the follower commits all requests contained in transferred commit and prepared logs.
To violate consistency therefore, a fault would be needed in both commit and prepare logs…
However, such a data loss fault in the primary’s prepare log would be detected, outside anarchy, because (i) the (correct) follower of view i would reply in the view change and (ii) an entry in the primary’s prepare log causally precedes the respective entry in the follower’s commit log. By simply verifying the signatures in the follower’s commit log, the fault of a primary is detected.
(A fault in the commit log of a follower is detected by verifying the signatures in the commit log of the primary).
Evaluation
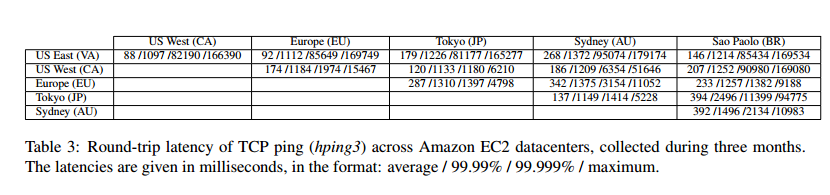
As an interesting bonus, the authors gathered data on round-trip times between Amazon EC2 datacenters worldwide over a period of three months (they did this in order to set the timeout value). Here it is:
(Click for larger view).
While we detected network faults lasting up to 3 minutes, our experiment showed that the round-trip latency between any two datacenters was less than 2.5 seconds 99.99% of the time. Therefore, we adopted the value of Δ = 2.5/2 = 1.25 seconds.
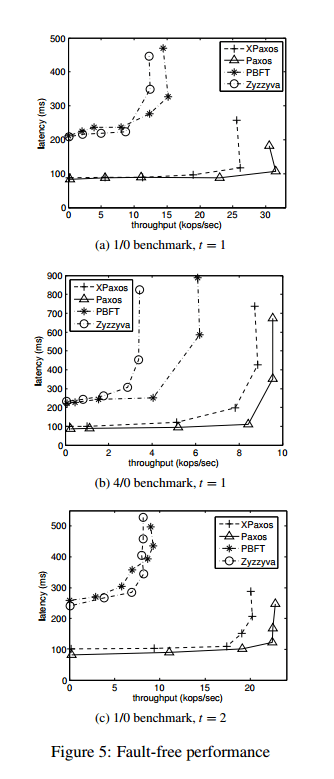
XPaxos was compared against the PBFT and Zyzzyva BFT protocols, and a WAN-optimized variation of crash-tolerant Paxos (CFT).
Here you see that XFT provides throughput and latency very similar to WAN-optimized Paxos:
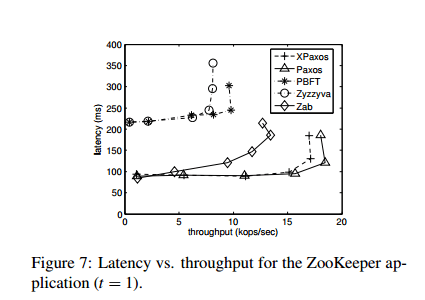
The team also created ZooKeeper variants using all three of the above protocols, plus XPaxos, and compared to the native Zookeeper Atomic Broadcast (Zab) protocol.
An analysis of reliability showed that…
… in typical configurations, where few faults are tolerated, a CFT system as a whole loses one nine of consistency [compared to XPaxos] from the likelihood that a single replica is benign.
The authors conclude:
Going beyond the research directions outlined above, this paper opens also other avenues for future work. For instance, many important distributed computing problems that build on SMR, such as distributed storage and blockchain, deserve a novel look at them through the XFT prism.

Just a small typo: s/CTF/CFT/ in “Whereas XFT always provides strictly stronger consistency and availability guarantees than CTF”