Rosetta: large scale system for text detection and recognition in images Borisyuk et al., KDD’18
Rosetta is Facebook’s production system for extracting text (OCR) from uploaded images.
In the last several years, the volume of photos being uploaded to social media platforms has grown exponentially to the order of hundreds of millions every day, presenting technological challenges for processing increasing volumes of visual information… our problem can be stated as follows: to build a robust and accurate system for optical character recognition capable of processing hundreds of millions of images per day in realtime.

Images uploaded by clients are added to a distributed processing queue from which Rosetta inference machines pull jobs. Online image processing consists of the following steps:
- The image is downloaded to a local machine in the Rosette cluster and pre-processing steps such as resizing (to 800px in the larger dimension) and normalization are performed.
- A text detection model is executed to obtain bounding box coordinates and scores for all the words in the image.
- The word location information is passed to a text recognition model that extracts characters given each cropped word region from the image.
- The extracted text along with the location of the text in the image is stored in TAO.
- Downstream applications such as search can then access the extracted textual information corresponding to the image directly from TAO.
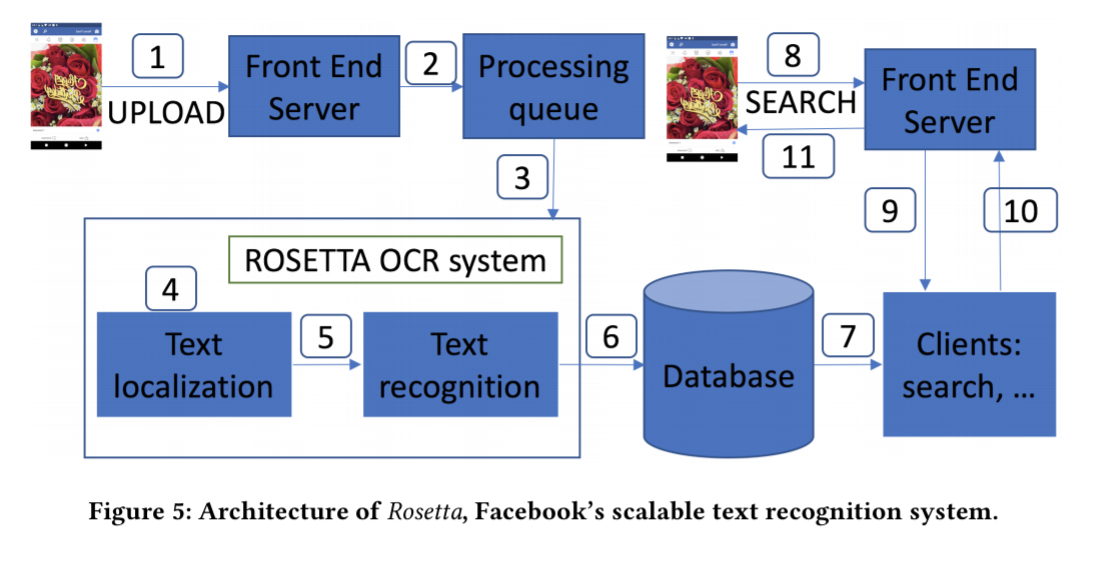
The most interesting part is of course the text extraction using the two-step process outlined above.
This two-step process has several benefits, including the ability to decouple training process and deployment updates to detection and recognition models, run recognition of words in parallel, and independently support text recognition for different languages.
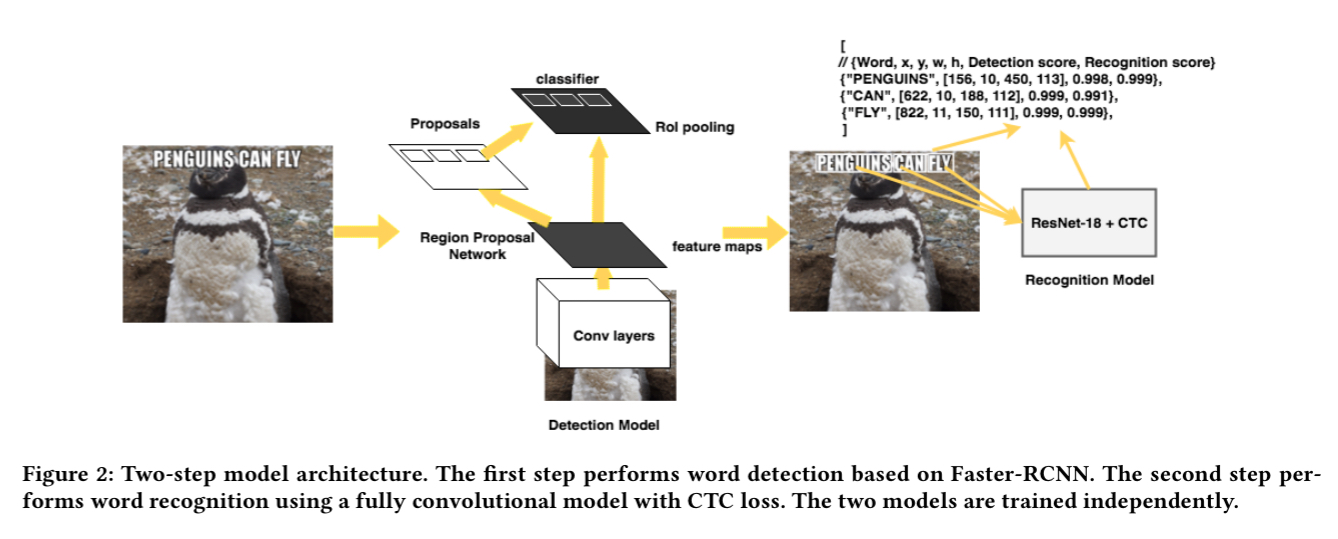
Text detection in Rosetta
Text detection is the most compute and latency sensitive component. After evaluating several different approaches the authors settled on the Faster-RCNN detection model. Amongst other reasons, Faster-RCNN was readily available to them as part of the Facebook Detectron platform. Since Detectron has been open-sourced by Facebook, that means it’s readily available to you too!
Faster-RCNN learns a fully convolutional CNN that can represent an image as a convolutional feature map. It also learns a region proposal network that takes the feature map as an input and produces a set of k proposal bounding boxes that contain text with high likelihood, together with their confidence score. There are a number of different choices for the convolutional body of Faster-RCNN. In tests, ShuffleNet proved the fastest (up to 4.5x faster than ResNet-50).
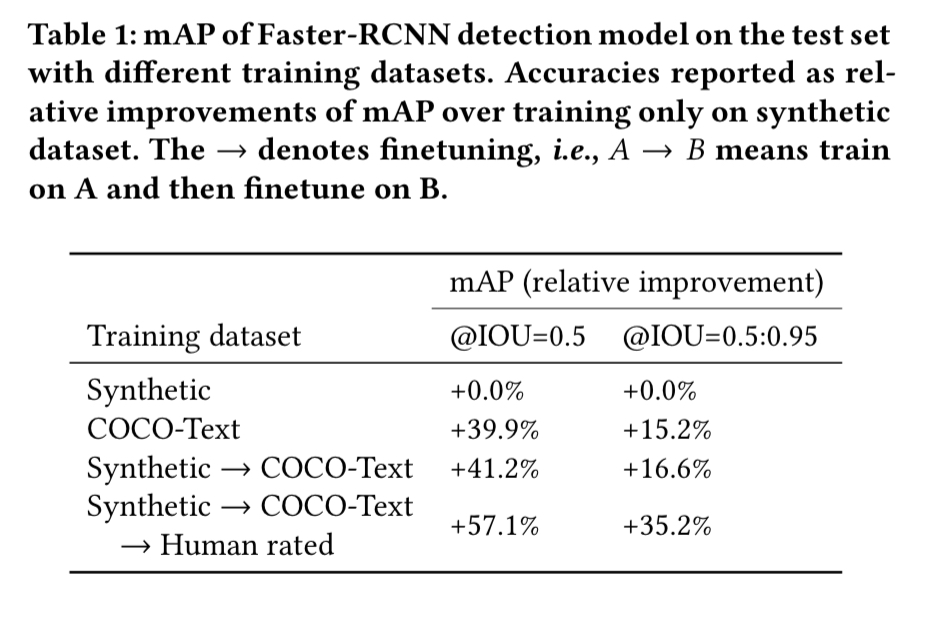
To train the text detection model the team initially used the COCO-Text dataset, but the wide-variety of text in images uploaded to Facebook (including e.g. lots of images with overlaid words) didn’t match well to the COCO-Text training set. In the end, the team used three different datasets for training: first an artificially generated dataset with text overlaid images; then COCO-Text; and finally a human-rated dataset specifically collected for Facebook client applications. The following table shows how accuracy improved as the various datasets were introduced.
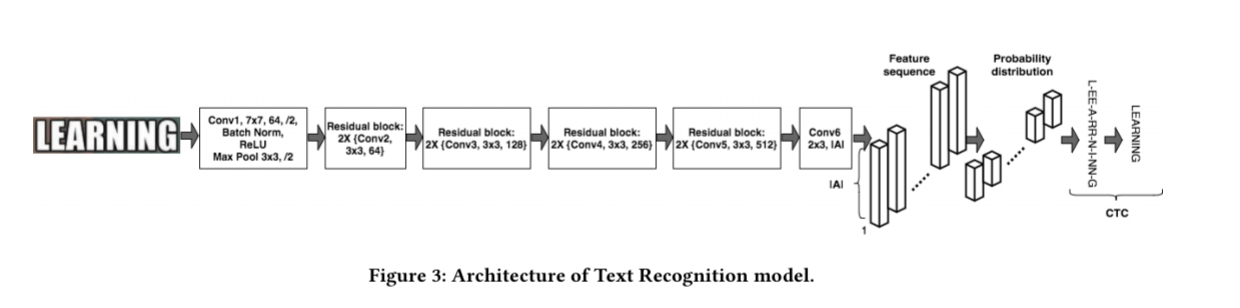
Text recognition in Rosetta
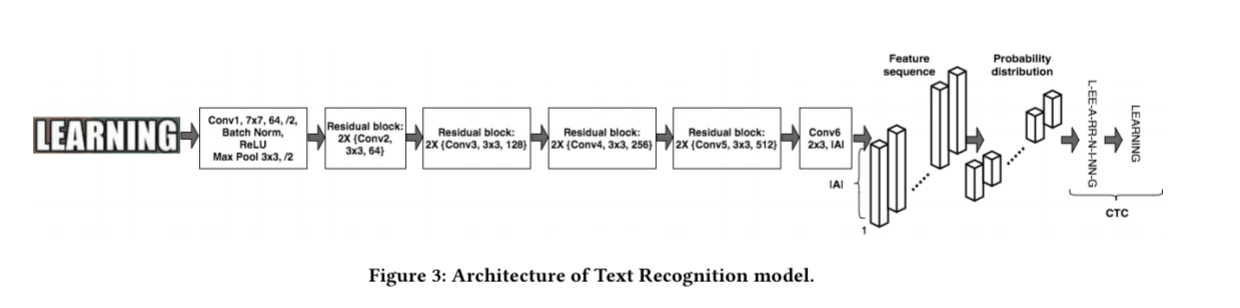
Text recognition is done using a fully-convolutional model called CTC (because it uses a sequence-to-sequence CTC loss during training) that outputs a sequence of characters. The last convolutional layer predicts the most likely character at every image position of the input word.
(Enlarge)
… every column of the feature map corresponds to the probability distribution of all characters of the alphabet at that position in the image, and CTC finds the alignments between those predictions, which may contain duplicate characters or a blank character, and the ground truth label.
For example, given the input training word LEARNING, the model might produce the sequence of characters ‘L-EE-A-RR-N-I-NN-G,’ which includes blanks (‘-’) and duplicates.
Decoding greedily takes the most likely character at every position of the sequence, and the in post-processing contiguous duplicate characters not delimited by the blank character are removed.
… a pre-defined dictionary would be too limiting for many real-world applications, which require recognizing more than just simple words as in the case of URLs, emails, special symbols and different languages. Therefore, an important architectural decision and a natural choice was to use a character-based recognition model.
A fixed width is needed at training time to be able to efficiently train using batches of images. Word images are resized to 32×128 pixels, with right-zero padding if the original is less than 128 pixels wide. This minimises the amount of distortion introduced in the images. During testing images are resized to a height of 32 pixels, preserving their aspect ratio (regardless of resulting width).
The number of character probabilities emitted is dependent on the width of the word image. A stretching factor of 1.2 was found to lead to superior results compared to using the original aspect ratio (you get 20% more output probabilities that way).
Training the CTC model proved difficult with it either diverging after just a few iterations or training too slowly to be of practical use. The solution was to use curriculum learning, i.e., starting with a simpler problem and increasing the difficulty as the model improves.
Training started with words of three characters or less, with the maximum word length increasing at every epoch. The width of images was also reduced initially. Training started with a tiny learning rate and this was also gradually increased at every epoch.
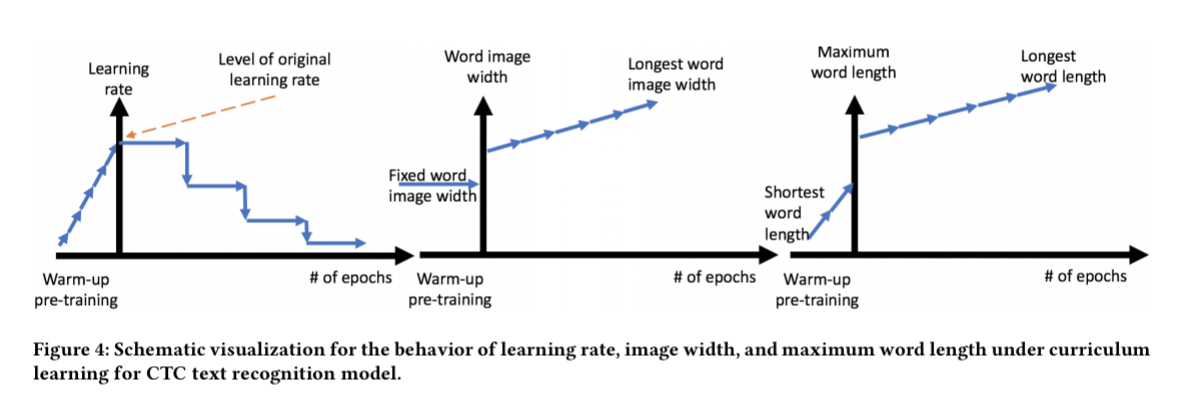
The overall accuracy of the system was further improved by 1.54% by introducing random jittering in the training set — randomly moving the bounding box coordinates of ground truth to model the behaviour of noise from the detection model.
Our system is deployed to production and processes images uploaded to Facebook everyday.

{kind=link}
Hi. The link to the paper appears to link to an old Morning Paper post. The PDF appears to be available through SciHub or through payment.
I’ll look into that straightaway, thanks!
The link should be this one btw: http://www.kdd.org/kdd2018/accepted-papers/view/rosetta-large-scale-system-for-text-detection-and-recognition-in-images If you follow the download link from there you should get free access in the ACM DL.