Columnstore and B+ tree – are hybrid physical designs important? Dziedzic et al., SIGMOD’18
Earlier this week we looked at the design of column stores and their advantages for analytic workloads. What should you do though if you have a mixed workload including transaction processing, decision support, and operational analytics? Microsoft SQL Server supports hybrid physical design combining both column store and B+ tree indexes in the same database.
It is generally understood that columnstores are crucial to achieving high performance for analytic queries and that B+ tree indexes are key to supporting transactional workloads efficiently. However, it is not well understood whether hybrid physical designs – both columnstore and B+ tree indices on the same database and potentially the same table – are important for any of the above workloads.
Through a series of benchmarks the authors show that hybrid physical designs can result in more than an order of magnitude lower execution costs for many workloads when compared to alternatives using B+ tree-only or columnstore-only. The Database Engine Tuning Advisor (DTA) for SQL Server is extended to analyze and recommend the appropriate indices for a given workload. Support for columnstore indices and the new DTA functionality was released in January 2017 as part of the Community Technology Preview release for Microsoft SQL Server 2017.
Physical design options in SQL Server
RDBMSs have supported B+ trees and heap files for several decades. With the advent of columnstores, which significantly outperform B+ trees for data analysis workloads, many commercial RDBMS vendors have added support for columnstore indexes (CSI)…
In SQL Server columnstores are treated as indexes. They can be primary (the main storage for all columns of the table) or secondary (e.g., just a subset of columns). You can have any combination of primary and secondary indexes on the same table. The primary can be a heap file, B+ tree, or a columnstore, and secondaries can be B+ trees or columnstore. At most one columnstore index is supported per table though.
SQL Server columnstores support vectorised operations and compression using run-length encoding and dictionary encoding. Within a columnstore, column data is held in column segments, each with data for 100K-1M rows. Inserts are handled using delta stores implemented as B+ trees. Secondary columnstores, optimised for operational analytics, used a B+ tree delete buffer for logical deletion of rows. This is periodically compressed into a delete bitmap storing the physical identifiers of the deleted rows. Primary columnstores don’t support delete buffers and work directly with delete bitmaps instead.
Microbenchmarks
The authors conducted a series of microbenchmarks as follows:
- scans with single predicates with varying selectivity to study the trade-off between the range scan of a B+ tree vs a columnstore scan
- sort and group-by queries to study the benefit of the sort order supported by B+ trees (columnstores in SQL Server are not sorted).
- update statements with varying numbers of updated rows to analyze the cost of updating the different index types
- mixed workloads with different combinations of reads and updates
The key findings are summarised in the table below.
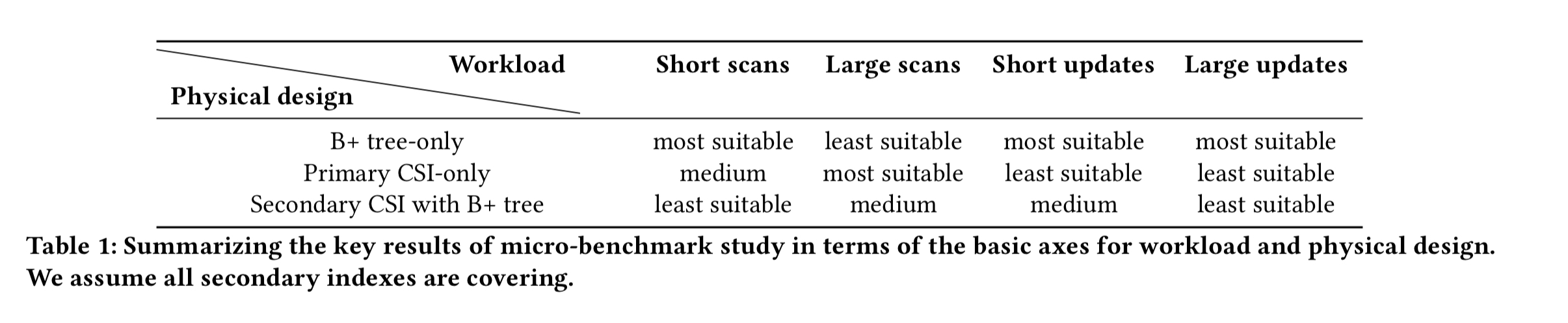
In a nutshell, B+ tree indexes are suitable for short range scans where the index allows efficient point and short range lookups. B+ trees are also the cheapest to update. On the other hand, primary CSIs are most suitable for large scans and bulk updates typical in data warehousing and analysis workloads. Secondary CSIs can provide significant speed-up for operational analytics on the same database where the OLTP application generating the data also runs. The basic workload axes can be combined in a variety of ways where a mix of the basic physical design axes are needed for optimal performance.
Well, surprise! B+ trees are good for OLTP, and columstores are good for analytics. Where things get interesting though, is when we combine the two for certain workloads….
Recommending hybrid designs
The Database Engine Tuning Advisor (DTA) recommends B+ tree indexes (primary and/or secondary), materialized views, and partitioning.
We extended DTA to analyze the combined space of B+ tree and columnstore indexes. By analyzing the workload, DTA is now capable of recommending B+ tree indexes only, columnstore indexes only, or a combination.
The high level architecture of DTA is shown in the figure below.
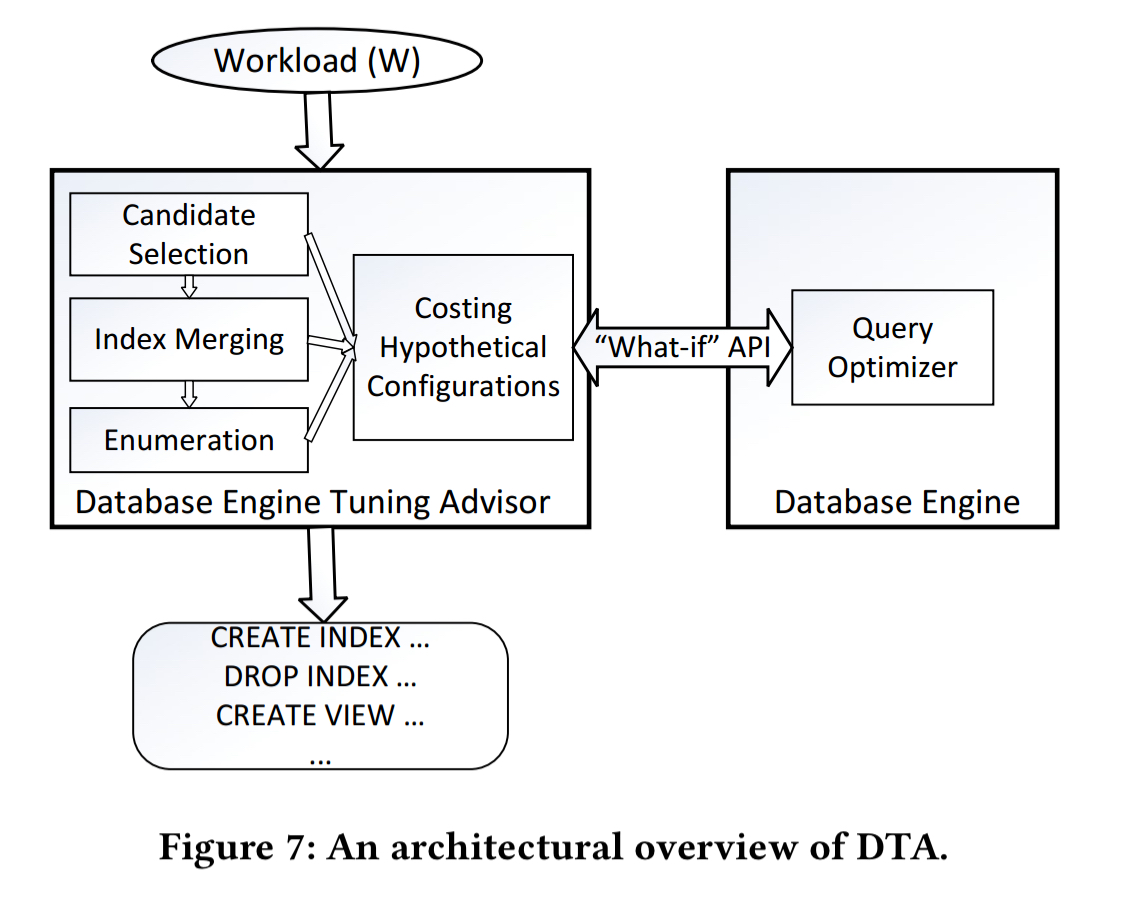
DTA begins with a local per-query analysis stage called candidate selection, which determines the optimal set ofd indexes for each query. Then it proceeds to global analysis, starting out by considering the potential to merge indexes on the same table. Once this is done DTA selects a final set of indexes to minimise the total cost of the workload subject to specified constraints.
DTA uses a cost-base search, which means it needs to estimate the costs using some indexes it hasn’t actually built yet. The “what-if” API is used to simulate such hypothetical indexes.
During the candidate selection phase DTA considers columnstore indexes on the tables referenced in the query. Given the constraint in SQL Server of only one columnstore index per table DTA chooses to include all columns with data types suitable for columnstore indexes. (And if the table includes a column with an unsupported data type, then a primary columnstore index is ruled out).
During merging there’s not much extra that can be done – only one columstore index is supported per table, and we can’t merge a columnstore index with a B+ tree index. During the final selection phase it is necessary to estimated per-column sizes for cost estimation. For hypothetical indexes, we need to do this without actually building the index. DTA uses block-level sampling coupled with techniques to estimate the impact of compression.
The effectiveness of run-length encoding depends on the number of runs in the column and the length of each run… SQL Server uses a greedy strategy that picks the next column to sort by based on the column with the fewest runs; we mimic this approach in our [estimation] technique.

The GEE estimator is used to estimate the number of distinct values for a set of columns.
Evaluation
The paper closes with an evaluation of both industry-standard benchmarks and real-world customer workloads to see how well the hybrid physical designs suggested by DTA improve query performance.
Read-only workloads are based on the TPC-DS benchmark and five real customer workloads. For mixed workloads, the CH benchmark (an extension of TPC-C) is used.
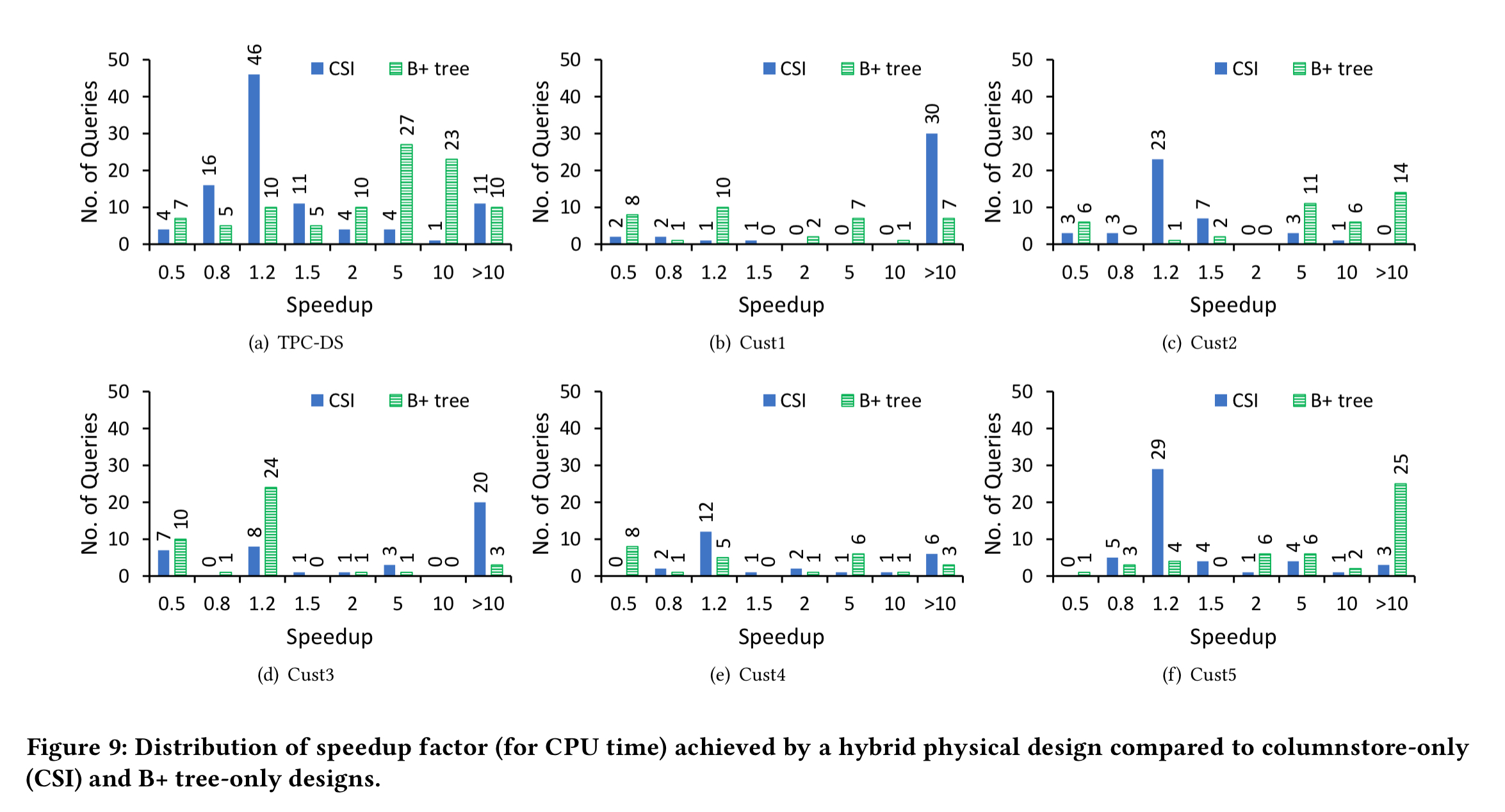
Figure 9 below shows the results for the read-only workloads. In each chart the blue bars show the speed-up obtained by the hybrid design vs CSI-only, and the green bars show the speed-up versus a B+ tree only design. For example, on TPC-DS, 46 queries were sped-up by a factor of 1.2x when comparing the hybrid design to a CSI only design.
(Enlarge)
… hybrid leverages the best of columnstores and B+ tree across several workloads. For each workload, there are several queries for which a hybrid physical design results in more than an order of magnitude improvement in execution cost. In some cases, the improvement is 2-3 orders of magnitude.
An example of a TCP-DC query that really benefits from the hybrid design is query #54. It references several large fact tables and as well as many dimension tables. The predicates on the dimension tables are selective enough that B+ trees have a significant advantage. Other tables have columnstore indexes. A similar pattern emerges with the workload of customer four where the optimiser uses an index seek on the fact table(s) followed by a scan of the columnstore on the dimensions, joining the tables with a hash join.
Here are the results for the CH workload:
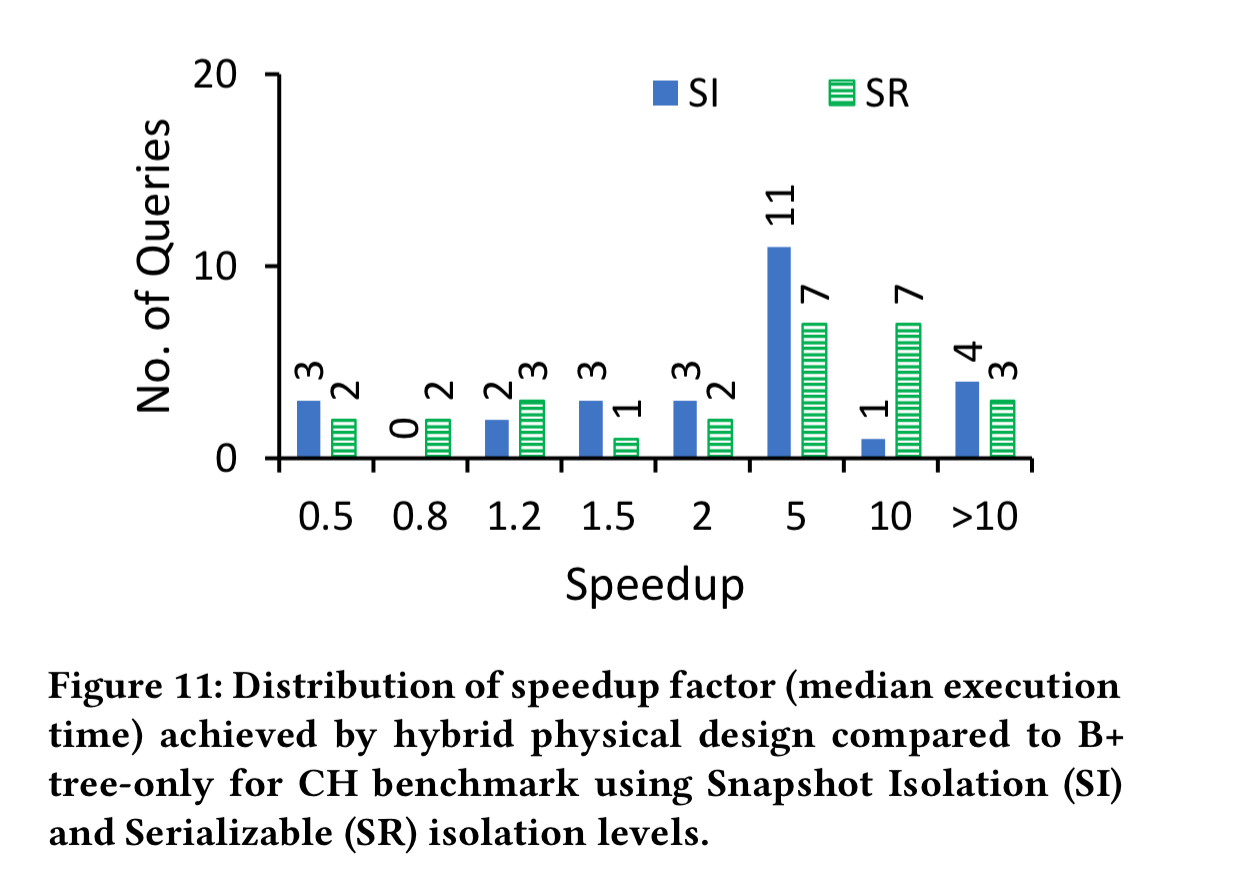
The hybrid design significantly speeds up the H (analytic) queries, while resulting in a moderate slow-down for the C (OLTP) queries – mostly the write transactions NewOrder and Payment.

{kind=link}
Thank you very much for covering our work.
I’d like to add that columnstore compression in SQL Server consists of 3 stages: encoding (dictionary or value based), row ordering, and compression (using run-length encoding or bit-packing). More about it can be found in this paper: “SQL server column store indexes” https://dl.acm.org/citation.cfm?id=1989448
CH benchmark is a mix of TPC-C and TPC-H benchmarks: https://dl.acm.org/citation.cfm?id=1988850
Small typos: “optimal set of(d) indexes for each query.” – remove (d).
“During the final selection phase it is necessary to estimate(d) per-column sizes for cost estimation.” – remove (d).
I enjoy reading this series of posts. Thank you. I especially like the links to papers that you provide.
Is there any open source database that offers a columnstore-B+ tree hybrid design?
You can join a table that is managed by a column store engine with a table that is managed by a row store engine in MariaDB, however, if you create a column oriented table, you cannot create a secondary B+ tree for such a table (at least, this was the state when I looked into it last year in October). Moreover, MariaDB does not support spilling to disk for queries executed against its columnstores (for aggregation, the whole hash table has to fit into memory, but you can execute ‘disk-based’ joins).