Applied machine learning at Facebook: a datacenter infrastructure perspective Hazelwood et al., _HPCA’18 _
This is a wonderful glimpse into what it’s like when machine learning comes to pervade nearly every part of a business, with implications top-to-bottom through the whole stack. It’s amazing to step back and think just how fundamentally software systems have changed over the last decade in this regard.
Just how pervasive is machine learning at Facebook?
- “At Facebook, machine learning provides key capabilities in driving nearly all aspects of user experience… Machine learning is applied pervasively across nearly all services.”
- “Facebook funnels a large fraction of all stored data through machine learning pipelines, and this fraction is increasing over time to improve model quality.”
- “Looking forward, Facebook expects rapid growth in machine learning across existing and new services…. Over time, most services indicate a trend toward leveraging increased amounts of user data.. the training data sets are trending towards continued and sometimes dramatic growth.”
The modern user-experience is increasingly powered by machine learning models, and the quality of those models depends directly on the volume and quality of the data powering them: “For many machine learning models at Facebook, success is predicated on the availability of extensive, high-quality data.” Data (relevant data, of course) is one of the most valuable assets a modern company can have.
As we looked at last month with Continuum, the latency of incorporating the latest data into the models is also really important. There’s a nice section of this paper where the authors study the impact of losing the ability to train models for a period of time and have to serve requests from stale models. The Community Integrity team for example rely on frequently trained models to keep up with the ever changing ways adversaries try to bypass Facebook’s protections and show objectionable content to users. Here training iterations take on the order of days. Even more dependent on the incorporation of recent data into models is the news feed ranking. “Stale News Feed models have a measurable impact on quality.” And if we look at the very core of the business, the Ads Ranking models, “we learned that the impact of leveraging a stale ML model is measured in hours. In other words, using a one-day-old model is measurably worse than using a one-hour old model.” One of the conclusions in this section of the paper is that disaster recovery / high availability for training workloads is key importance. (Another place to practice your chaos engineering ;) ).
Looking at a few examples of machine learning in use at Facebook really helps to demonstrate the pervasive impact.
Examples of machine learning in use at Facebook
- Ranking of stories in the News Feed is done via an ML model.
- Determining which ads to display to a given user is done via an ML model: “Ads models are trained to learn how user traits, user context, previous interactions, and advertisement attributes can be most predictive of the likelihood of clicking on an ad, visiting a website, and/or purchasing a product.“
- The various search engines (e.g. videos, photos, people, events, …) are each powered by ML models, and an overall classifier model sits on top of all of them to decide which verticals to search in for any given request.
- Facebook’s general classification and anomaly detection framework, Sigma, is used for a number of internal applications including site integrity, spam detections, payments, registration, unauthorized employee access, ad event recommendations. Sigma has “hundreds of distinct models running in production every day.”
- Lumos extracts attributes and embeddings from images. (I’m not sure of the relationship of Lumos to Rosetta)
- Facer is Facebook’s face detection and recognition framework.
- Translations between more than 45 source and target languages are powered by models unique to each language pair, with about 2000 translation directions supported today. About 4.5B translated post impressions are served every day.
- Speech recognition models convert audio streams into text to provide automated captioning for video.
And these are just the highlights…
In addition to the major products mentioned above, many more long-tail services also leverage machine learning in various forms. The count of the long tail of products and services is in the hundreds.
What kinds of models are commonly used?
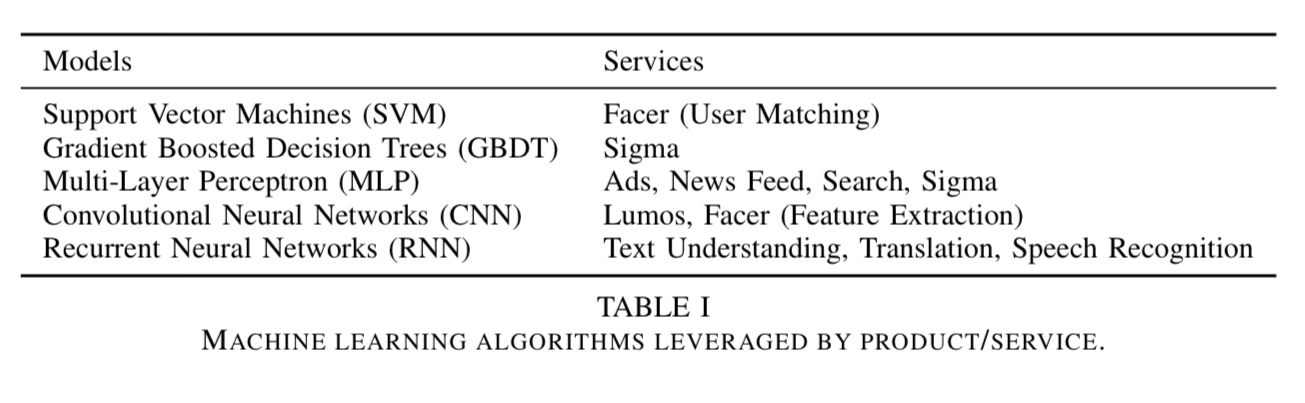
The major ML algorithms in use at Facebook include logistic regression, support vector machines, gradient boosted decision trees, and DNNs. Within the family of DNNs, MLPs are used to operate on structured data (e.g. for ranking), CNNs are used for spatial tasks (e.g. image processing), and RNN/LSTMs are use for sequence processing (e.g. language processing).
From research to production: PyTorch, Caffe2, and FBLearner
Facebook’s internal FBLearner suite of tools includes a feature store that acts as a catalog of feature generators that can be used for both training and real-time prediction: “it serves as a marketplace that multiple teams can use to share and discover features.” FBLearner Flow trains models based on workflow descriptions, and also has built in support for experiment management. Predictor uses the models trained in Flow to serve real-time predictions.
Training the models is done much less frequently than inference— the time scale varies, but it is generally on the order of days. Training also takes a relatively long time to complete – typically hours or days . Meanwhile, depending on the product, the online inference phase may be run tens of trillions of times per day, and generally needs to be performed in real time. In some cases, particularly for recommendation systems, additional training is also performed online in a continuous manner.
For research and exploration Facebook use PyTorch: “it has a frontend that focuses on flexibility, debugging, and dynamic neural networks which enables rapid experimentation.” PyTorch isn’t optimised for production and mobile deployments though, so once a model has been developed it is translated into Caffe2, Facebook’s production framework for training and deploying large-scale ML models.
Instead of simply rewriting the model, Facebook have been active in building the ONNX toolchain (Open Neural Network Exchange) for standard interchange of deep learning models across different frameworks and libraries.
Within Facebook, we’re using ONNX as a primary means of transferring research models from the PyTorch environment to the high-performance production environment of Caffe2.
Infrastructure implications
Training requires a mix of CPUs and GPUs, whereas model serving is mostly done from CPUs. For training, locality of the data sources is important as the amount of data used by the models continues to grow. The physical locations of the GPUs used for ML training are deliberately diversified to provide resilience and the ability to continue to train in the event of the loss of a region / datacenter.
For sophisticated ML applications such as Ads and Feed Ranking, the amount of data to ingest for each training task is more than hundreds of terabytes.
The data volumes also mean that distributed training becomes increasingly important. “This is an active research area not only at Facebook, but also in the general AI research community. ” During inference models are typically designed to run on a single machine, though here also Facebook’s major services are constantly evaluating whether it makes sense to start scaling models beyond the capacity of a single machine.
Beyond the data volumes, there’s also a lot of complex processing logic required to clean and normalise the data for efficient transfer and easy learning. This places a very high resource requirement on storage, network, and CPUs. The data (preparation) workload and training workload are kept separated on different machines.
These two workloads have very different characteristics. The data workload is very complex, ad-hoc, business dependent, and changing fast. The training workload on the other hand is usually regular, stable, highly optimized, and much prefers a “clean” environment.
Hardware
Moore’s law may be over, but it’s interesting to compare the progress made in two years between the 2015 “Big Sur” GPU server design used by Facebook, and the 2017 “Big Basin” GPU Server:
- Single precision floating arithmetic per GPU up to 15.7 teraflops from 7 teraflops
- High bandwidth memory providing 900 GB/s of bandwidth (3.1x the bandwidth in Big Sur)
- Memory increase from 12 GB to 16 GB
- High bandwidth NVLink inter-GPU communication
- Resulting in a 300% improvement in throughput when training the ResNet-50 image model compared to Big Sur.
Future directions
The demands of ML workloads impact hardware choices. For example compute bound ML workloads benefit from wider SIMD units, specialized convolution or matrix multiplication engines, and specialized co-processors. Techniques such as model compression, quantization, and high-bandwidth memory help to retain models in SRAM or LLC, and mitigate impact when they don’t.
Reducing the latency in incorporating the latest data into models requires distributed training, which in turn, ‘requires a careful co-design of network topology and scheduling to efficiently utilize hardware and achieve good training speed and quality.’
Addressing these and other emerging challenges continues to require diverse efforts that span machine learning algorithms, software, and hardware design.

4 thoughts on “Applied machine learning at Facebook: a datacenter infrastructure perspective”
Comments are closed.