Continuum: a platform for cost-aware low-latency continual learning Tian et al., SoCC’18
Let’s start with some broad approximations. Batching leads to higher throughput at the cost of higher latency. Processing items one at a time leads to lower latency and often reduced throughput. We can recover throughput to a degree by throwing horizontally scalable resources at the problem, but it’s hard to recover latency. In many business scenarios latency matters, so we’ve been seeing a movement overtime from batching through micro-batching to online streaming.
Continuum looks at the same issues from the perspective of machine learning models. Offline (batch) trained models can suffer from concept drift (loss of accuracy over time) as a result of not incorporating the latest data. I.e., there’s a business cost incurred for higher latency of update incorporation. Online models support incremental updates. Continuum determines the optimum time to retrain models in the presence of incoming data, based on user policy (best effort, cost-aware, or user-defined). There’s some great data here about the need for and benefit of continual learning, and a surprising twist in the tale where it turns out that even if you can afford it, updating the model on every incoming data point is not the best strategy even when optimising for lowest latency of update incorporation.
When good models go stale
There are a number of purpose-designed online learning algorithms (e.g. Latent Dirichlet Allocation for topic models, matrix factorization for recommender systems, and Bayesian inference for stream analytics). However, many mainstream ML frameworks including TensorFlow, MLib, XGBoost, scikit-learn and MALLET do not explicitly support continual model updating. It’s up to the user to code custom training loops to manually trigger retraining. Often such models are updated on much slower timescales (e.g. daily, or maybe hourly) than the generation of the data they operate over. This causes a loss in model accuracy when concept drift occurs.
Consider a Personalized PageRank (PPR) algorithm being fed data from Twitter. The following chart shows how L1 error and MAP metrics degrade over time as compared to a model trained on the very most recent data. The base model decays by about 10% in one hour.
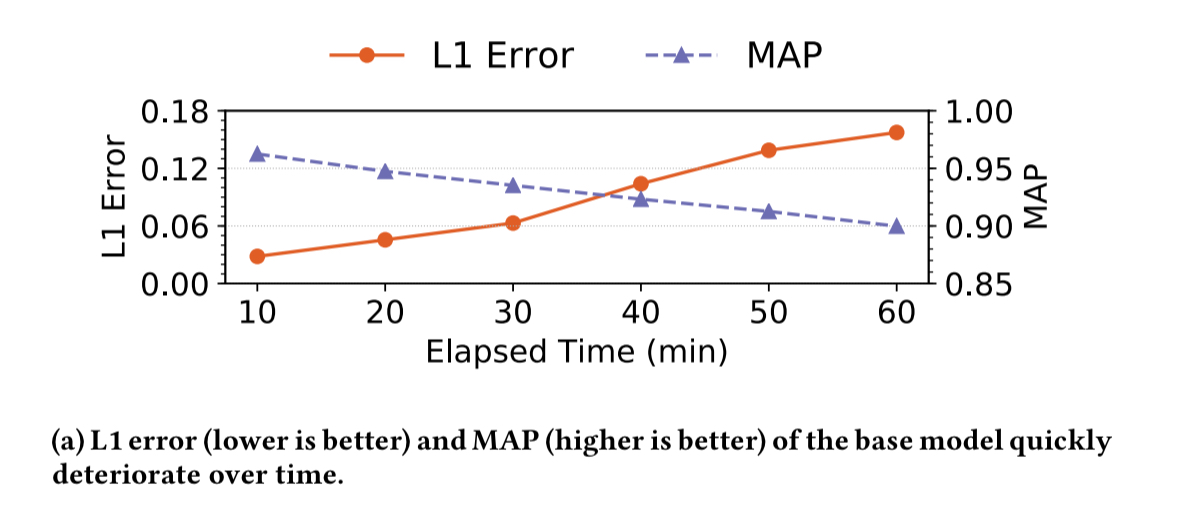
Using offline (batch) training to retrain the model from scratch every 10 minutes also takes orders of magnitude more compute than online learning, making short retraining windows using the full training data set impractical.
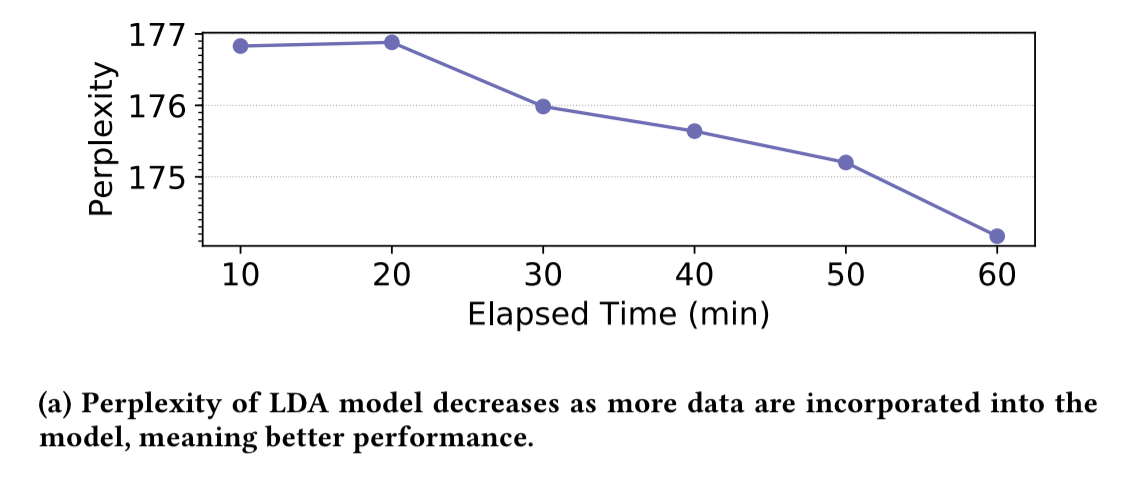
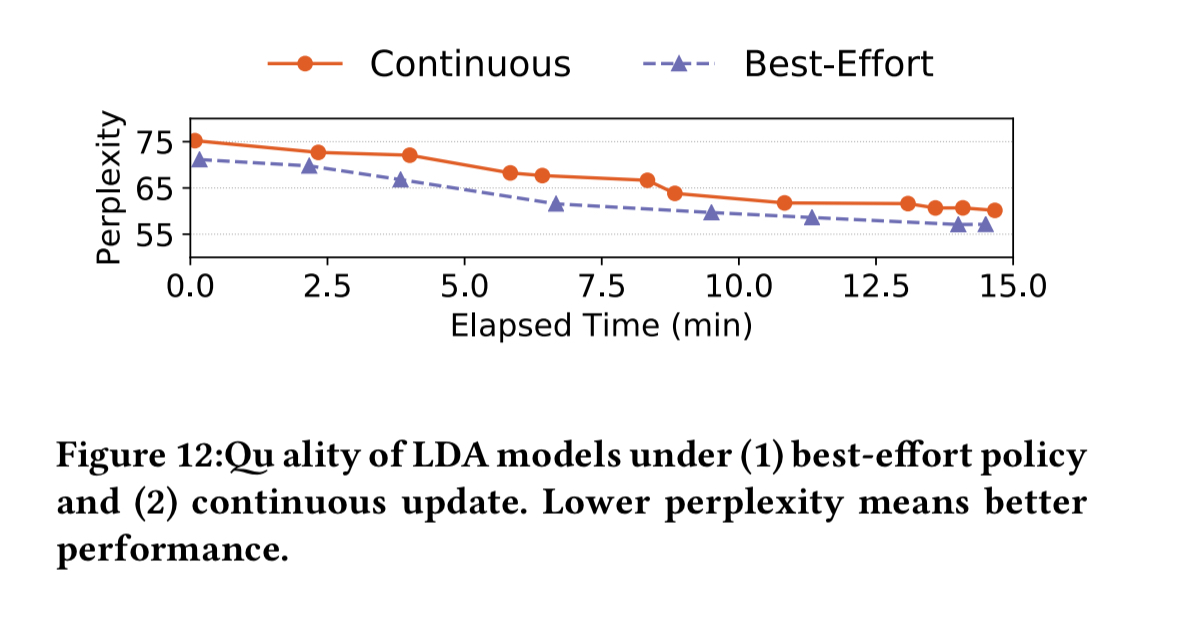
When a topic modelling model (also trained using tweets) is updated once every ten minutes, we can see that it’s perplexity (lower is better) decreases with every retraining.
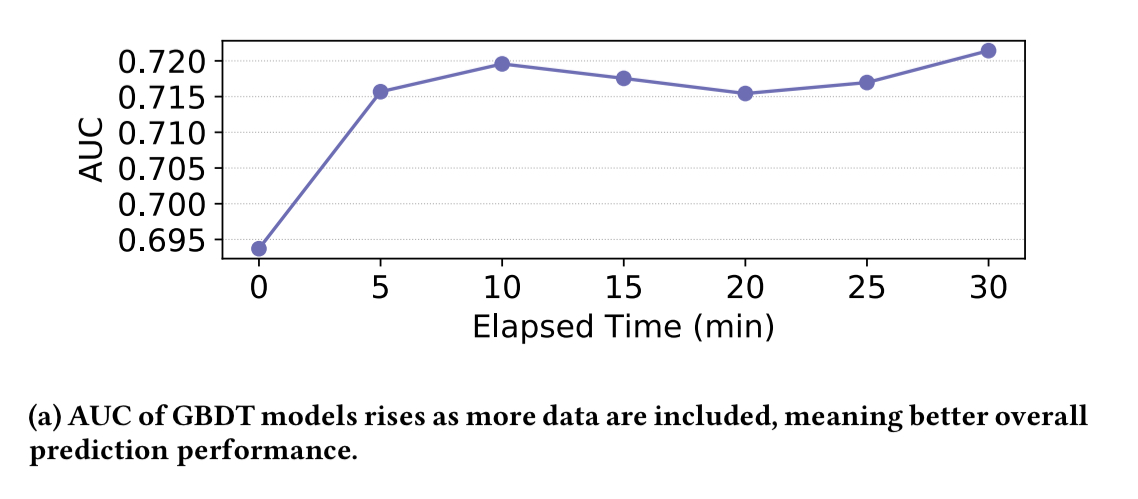
The performance of an ad recommendation system classifier similarly improves over time with model updating every five minutes.
Data recency clearly matters in a number of applications. But writing your own continual learning training loops can be as much if not more work than implementing the key logic of online learning in the first place.
An overview of Continuum
Continuum is designed to support continual learning a cross a broad set of ML frameworks. Based on an update policy, Continuum decides when to update the model.
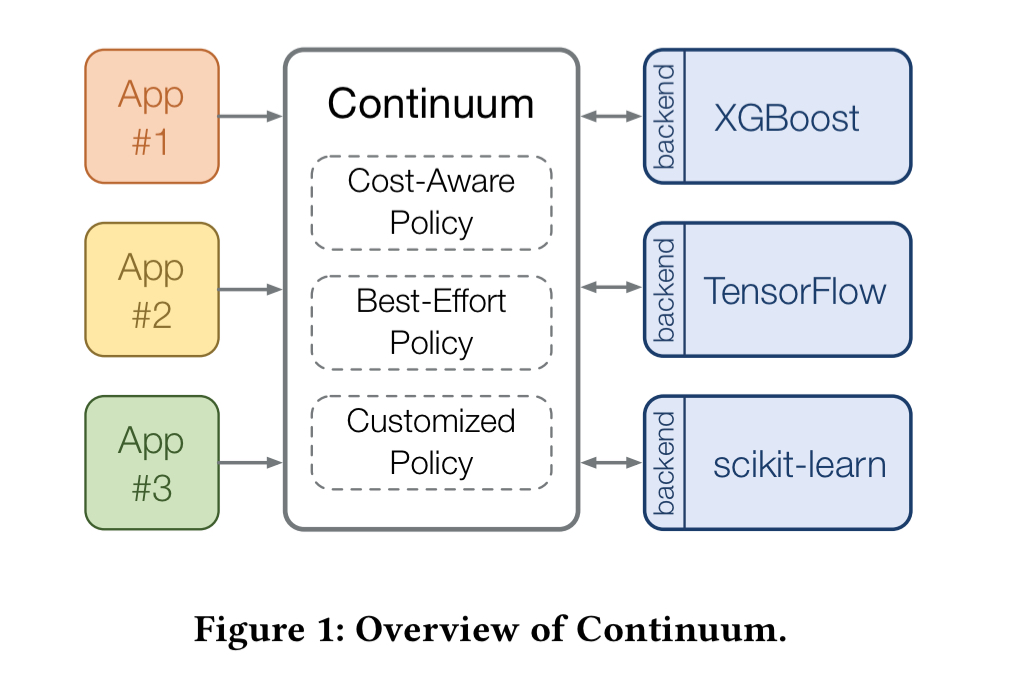
At runtime it looks like this:
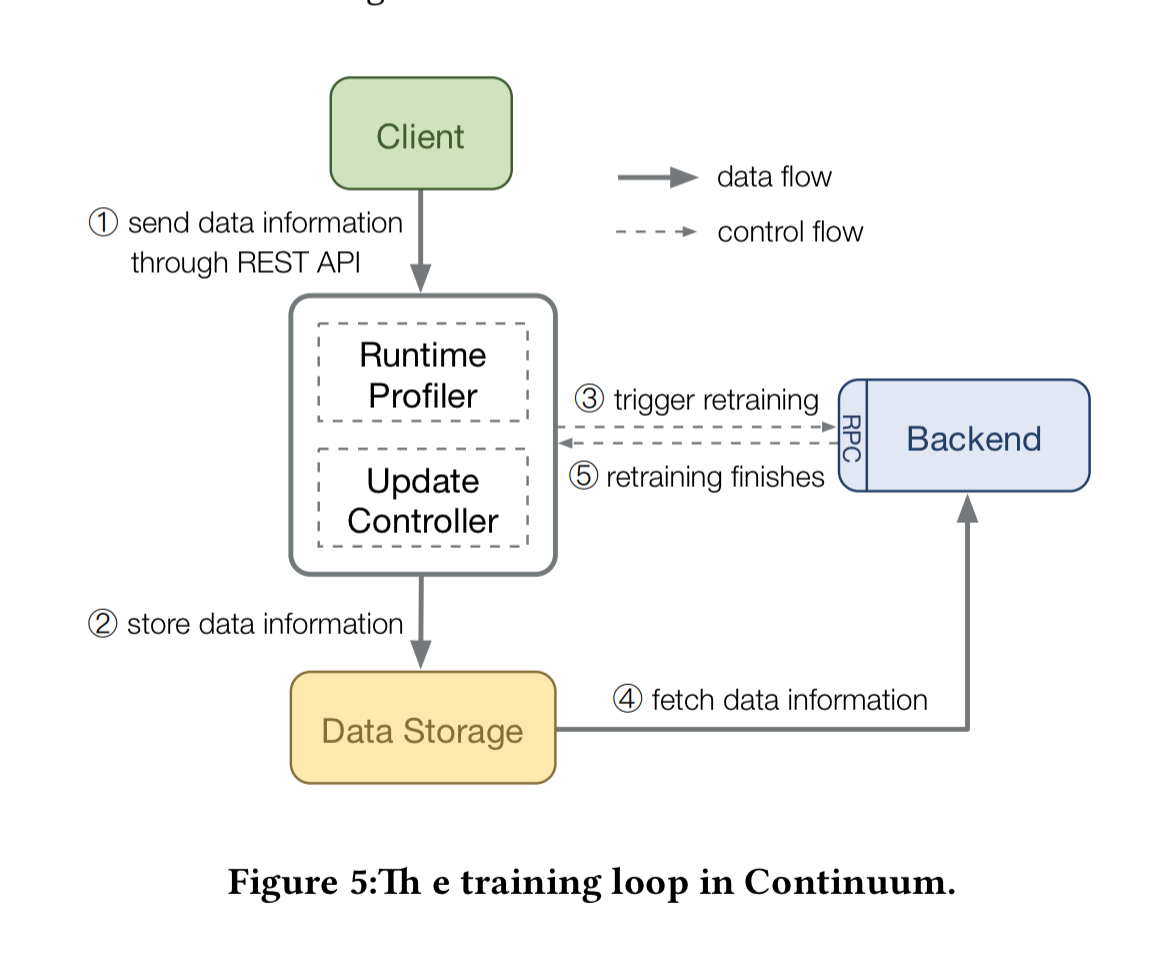
- Clients send data updates (or pointers to updated data) to Continuum
- Continuum stores the updated data
- Continuum evaluates the update policy and triggers retraining if needed
- The backend fetches the updated data from data storage and trains the model
- The backend notifies Continuum that an updated model is available. The updated model can then be shipped to a model serving system, e.g. Clipper.
Continuum is about 4,000 lines of C++ and Python, and is available in open-source here: https://github.com/All-less/continuum.
The most interesting parts of all this are the update policies that determine when to trigger retraining. There are two policies available out-of-the-box: best-effort updating, and cost-aware updating.
Best-effort updating
A straightforward approach to reduce data incorporation latency is to continuously retrain the model, where the (i+1)th update immediately follows after the i-th… However, this simple approach falls short in the presence of flash crowd data, e.g. fervent responses to celebrity posts, surging traffic due to breaking news, and increased network usage during natural disasters.
The thing is, retraining a model takes time, and it’s never going to be as fast as the rate of data arrival under such circumstances. So if a surge of data arrives just after an update has started, we’ll have to wait longer than we’d like (until that update has finished, and we can start and complete another one) before the data is incorporated. Sometimes therefore it makes sense to abort an ongoing update and restart training to incorporate the surge of data.
To determine when to abort and restart, we speculate, upon the arrival of new data, if doing so would result in reduced data latency.
Training time is predicted using a linear model as a function of the amount of training data available. In the evaluation, when compared to a continuous update policy, the abort-and-restart policy adopted by best-effort resulted in up to a 15.2% reduction in latency (time to incorporate updates in a trained model), and an average reduction of 9.5%.
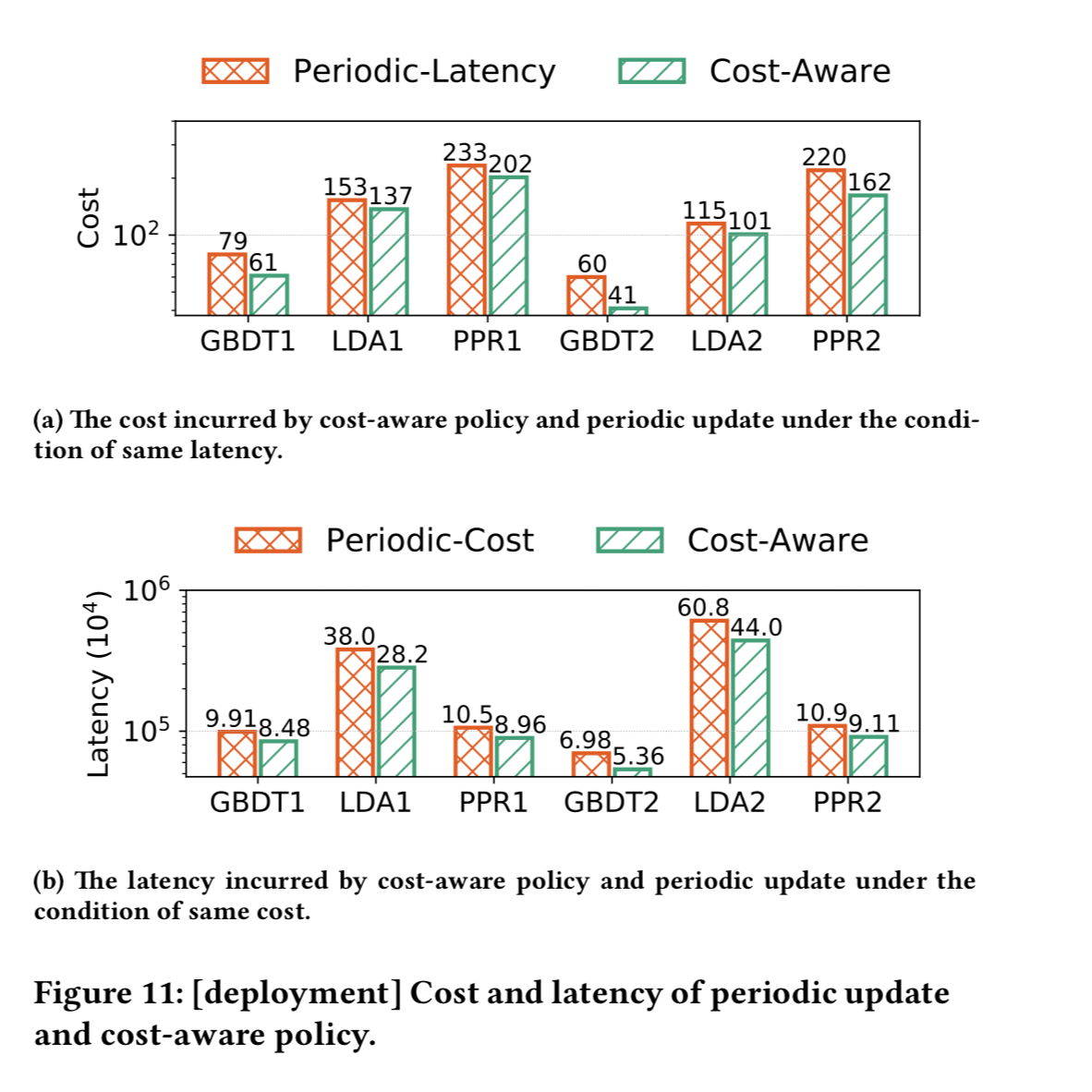
The reduction in latency pays off in increased model quality:
Cost-aware updating
The best-effort policy takes no account of the costs of retraining. The cost-aware policy seeks to provide the best reduction in latency possible within a given budget. More precisely, for every unit of training cost expended, it expects the data incorporation latency to be reduced by a configurable amount, w. It’s based on a principle of regret.
Suppose that we have accumulated D samples since the last update. If we now perform an update (at time t) we can compute the cumulative latency for those updates (see the left-hand side of the figure below). If we had instead performed at earlier update at time t’ the cumulative latency could have been lower (see the right-hand side of the figure below).
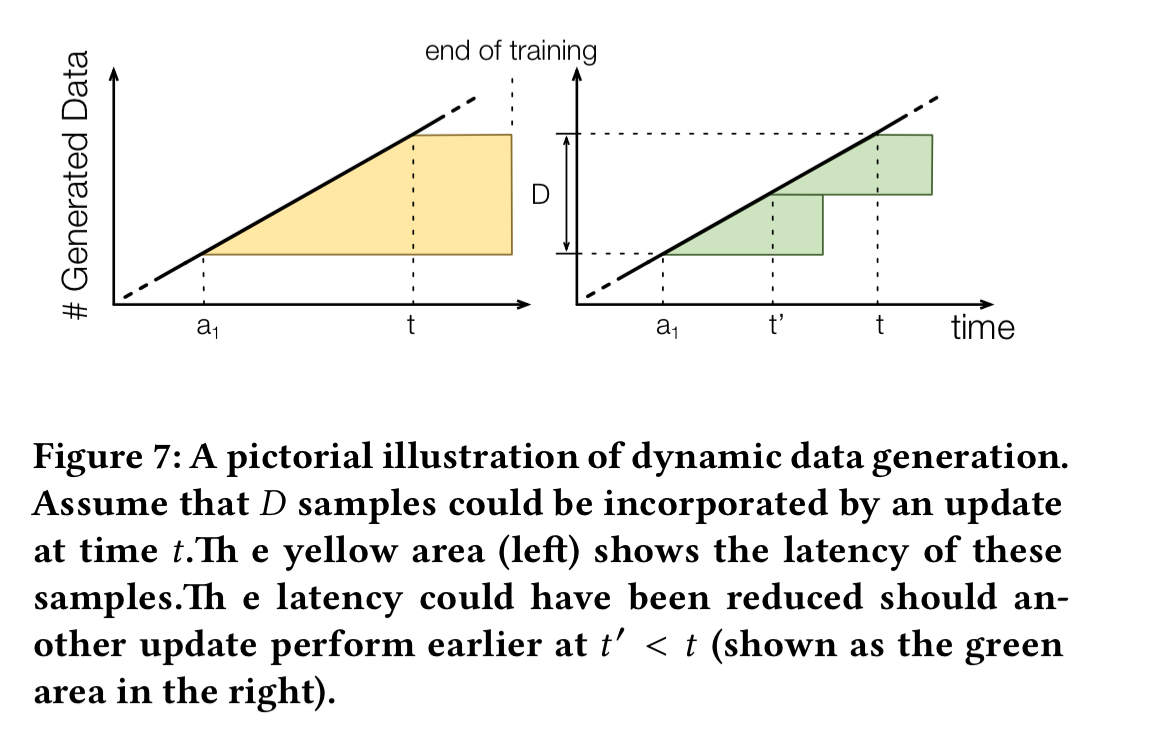
The cost-aware policy finds the t’ which gives the maximum possible latency reduction. The difference between this value and the latency from updating at time t is called the regret. When regret exceeds a threshold 
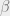

The cost-aware policy is more than a simple heuristic. We show through competitive analysis that even compared with the optimal offline policy assuming full knowledge of future data arrivals, the latency-cost sum incurred by our algorithm is no more than twice of the optimum (i.e., it is 2-competitive).
Compared to a straightforward periodic update, the evaluation shows that the cost-aware policy can reduce compute costs by 32% at the same latency, or reduce latency by 28% for the same cost.
Quality-aware updating
Another update policy that can be considered is quality-aware updating. Here a model-specific quality metric is collected, and retraining triggered whenever this drops below a certain threshold. Users of Continuum can easily provide their own quality-based update policy implementations to plug into the Continuum engine.
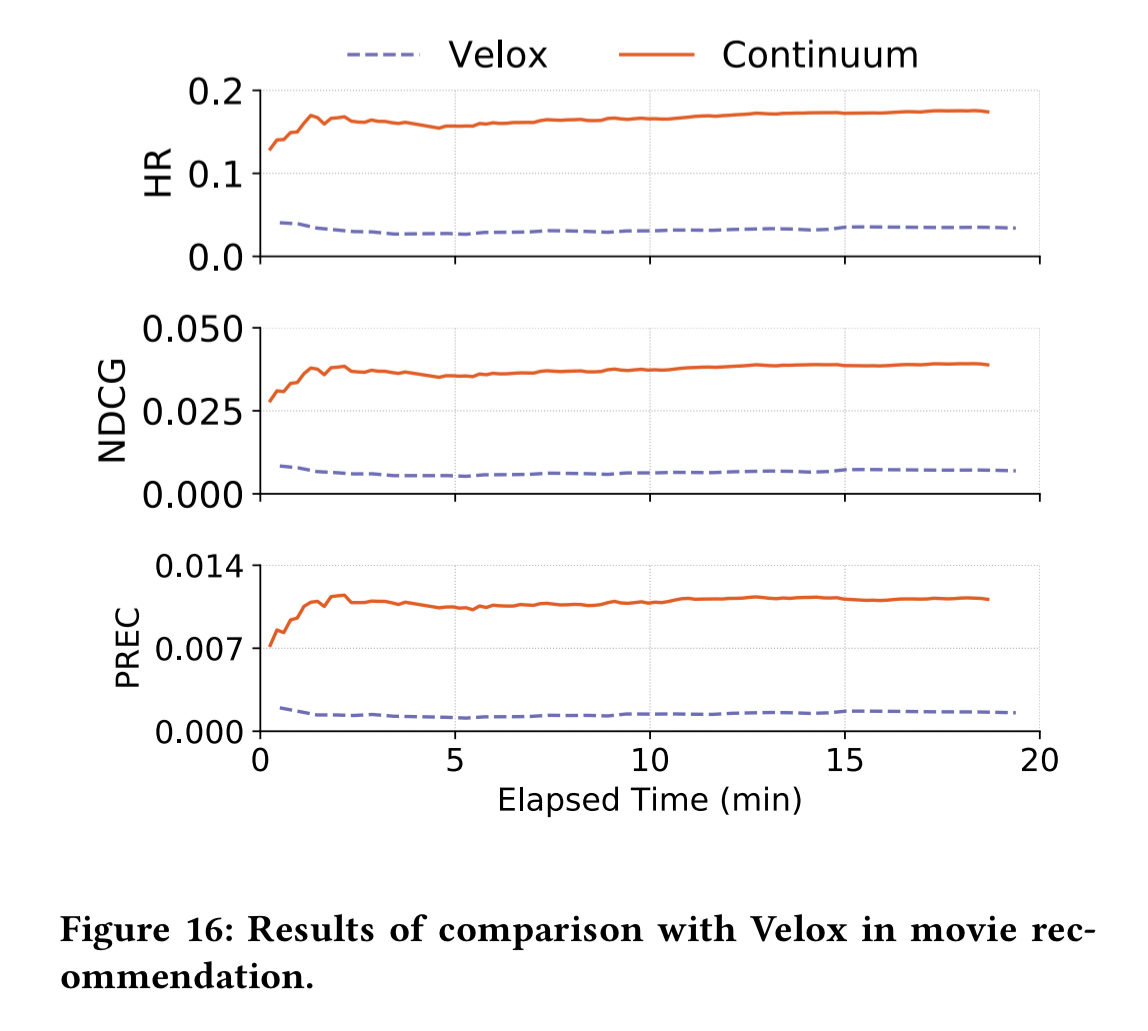
Comparison with Velox
Velox is a model serving system closely integrated with Spark MLib. “To the best of our knowledge, Velox is the only learning system that explicitly supports (offline) model updating.”
Using the MovieLens dataset a base model is trained with 95% of the data and then the remaining 5% is fed both to Velox and Continuum over a 20 minute window. Recommendation quality is assessed using hit ratio (HR), Normalized Discounted Cumulative Gain (NDCG), and precision (PREC). Continuum outperforms Velox in all metrics.

3 thoughts on “Continuum: a platform for cost-aware low-latency continual learning”
Comments are closed.