ScootR: scaling R dataframes on dataflow systems Kunft et al., SoCC’18
The language of big data is Java ( / Scala). The languages of data science are Python and R. So what do you do when you want to run your data science analysis over large amounts of data?
…programming languages with rich support for data manipulation and statistics, such as R and Python, have become increasingly popular… [but]… they are typically designed for single machine and in-memory usage…. In contrast, parallel dataflow systems, such as Apache Flink and Apache Spark, are able to handle large amounts of data. However, data scientists are often unfamiliar with the systems’ native language and programming abstraction, which is crucial to achieve good performance.
A tempting solution is to embed Python / R support within the dataflow engine. There are two basic approaches to this today:
- Keep the guest language components in a separate process and use IPC (inter-process communication) to exchange input and output data between the dataflow engine and the guest language process. This approach can support the full power of the guest language, but pays a heavy price in IPC and serialisation costs.
- Use source-to-source (STS) translation to translate guest language code into the dataflows native API. The translated code can achieve near native performance, but comprehensive source-to-source translation is difficult and so tends to be restricted to a subset of the guest language functions and libraries.
SparkR is of interest here because it supports both STS translation and IPC. It uses STS where possible, and falls back to IPC outside of this. Executing a simple user-defined function via IPC is about 100x slower than native execution after STS translation:

Clearly what we want is the performance of native execution (STS), but with the flexibility to use the full scope of the guest language and libraries. In theory we could just invest in building better and better STS translators (e.g., R to Java in this case), but this entails a huge effort and results in a hard-to-maintain point solution.
When faced with an M:N style integration problem, it often pays to look for a common intermediate representation (IR). If only there was some IR which both Java and R (and Python, Ruby, JavaScript,… ) could compile into, then we could build the inter-operation at the IR level. The JVM has byte code, LLVM has bitcode, and a little bit closer to home, Weld has an IR based on linear types.
In this research, Graal and Truffle provide the common ground (see One VM to rule them all).
Graal, Truffle, and FastR
Truffle is a language implementation framework that supports development of high performance language runtimes through self-optimising AST interpreters. The ASTs collect profiling information at runtime and specialise their structure accordingly. Languages built on top of Truffle can efficiently exchange data and access functions.
Graal is a dynamic compiler that produces highly-optimised machine code as soon as a Truffle AST reaches a stable state. De-optimisations and speculation failures are handled automatically by falling back to the AST.
The GraalVM is a multi-language execution runtime capable of running multiple languages in the same virtual machine instance, with full interoperability between all its supported languages.
GraalVM can execute Java applications on top of the HotSpot Java VM, and can execute other Truffle-based language runtimes such as JavaScript, Ruby, Python, and LLVM.
One of the default languages of the GraalVM is fastR, a high-performance GNU-R compatible R language runtime implemented using Truffle and relying on the Graal dynamic compiler. fastR supports the C API from GNU-R, and so can support many of the R packages that depend on underlying C implementations. Some R packages rely on GNU-R internals which make fastR integration harder, but fastR is continually being enhanced to support these too.
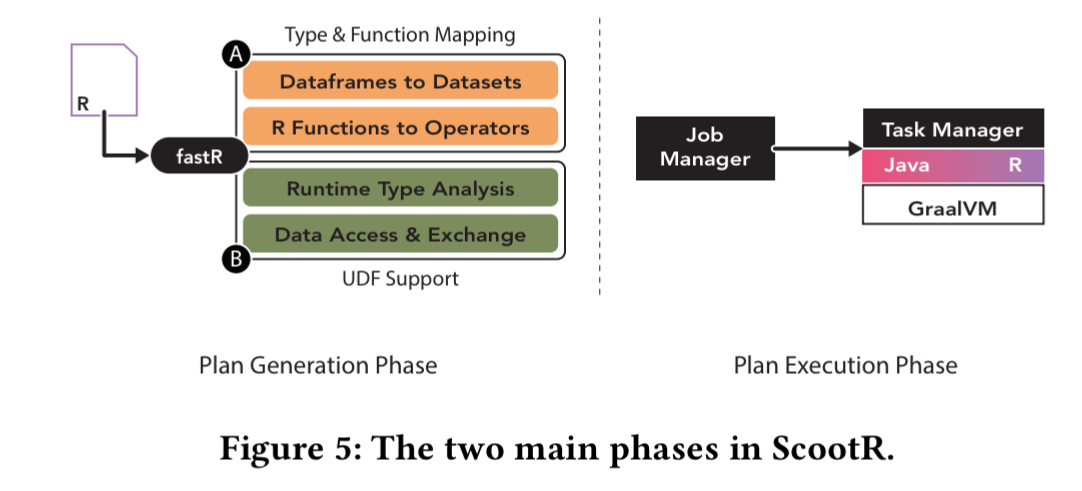
Introducing ScootR
ScootR builds on the capabilities of the GraalVM to expose Flink’s internal data structures to the fastR engine. First ScootR creates an execution plan based on the R source code, and then this plan can be deployed and executed on a Flink cluster. R user-defined functions (UDFs) are executed in parallel by each worker node, and automatically optimised by the Graal JIT compiler.
Here’s an example R application making use of the ScootR dataframe API:

R dataframes are mapped to Flink TupleN dataset types, and invocations to ScootR’s API are mapped to Flink operators via new Truffle AST nodes (_RBuiltinNode_s). For R functions that involve user-defined code, ScootR needs to infer the input and output types. Input types are specified by the user when reading files (e.g., line 7 in the listing above). For output types ScootR just instantiates a temporary tuple, invokes the function, and inspects the output.
For efficient access of Java data types within R and vice-versa, ScootR makes use of Truffle’s language interoperability features. R functions are also rewritten to create and return Flink tuples directly in the R function.
Here’s an example of the execution plan generated for the sample R program above.
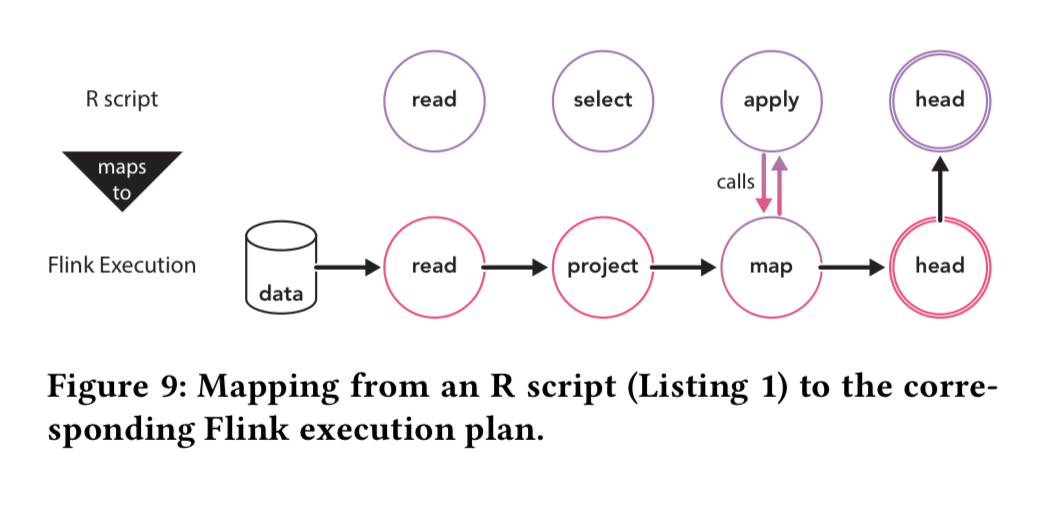
Only the apply function includes user-defined code, all other functions are replaced with the corresponding Flink operators during the plan generation phase.
Evaluation
The evaluation is based on two datasets:
- The Airline On-Time Performance Dataset with arrival data for US flights, converted into CSV format. The resulting file size is 9.5GB.
- The Reddit Comments Dataset (four consecutive months’ worth, at about 14GB per month in CSV format).
ScootR is compared against native GNU-R, fastR, and SparkR, as well as against natively coded pipelines in Spark and Flink. Here are the single node and cluster comparisons for an ETL pipeline on the airline data as follows:

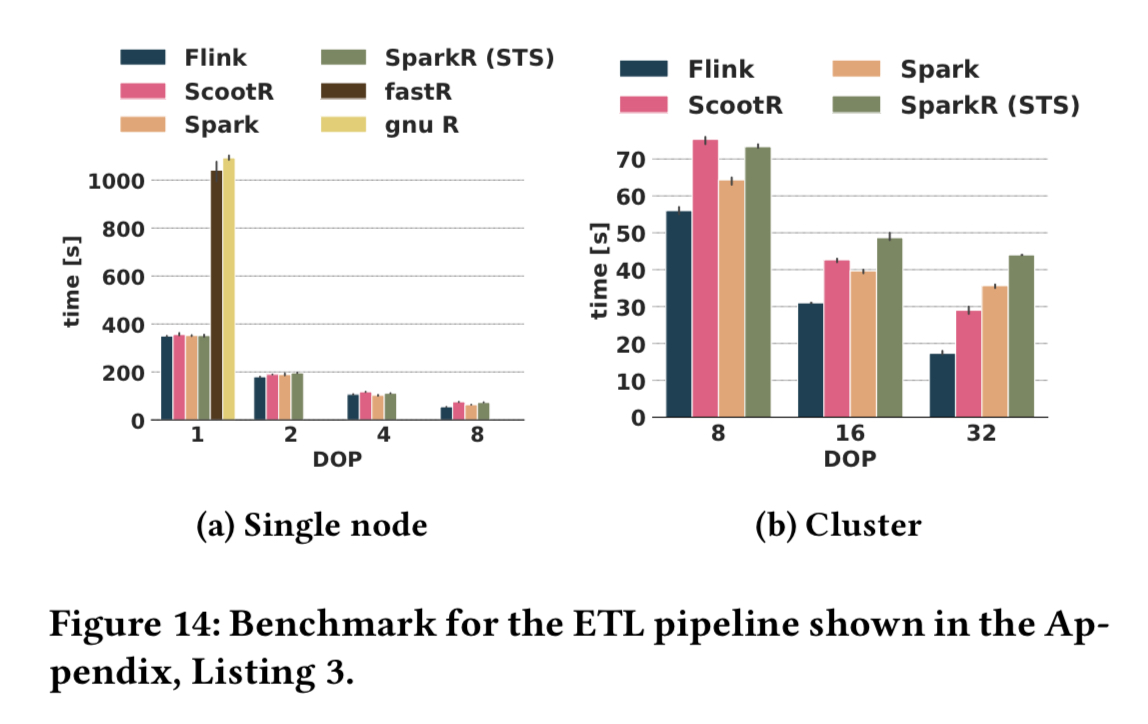
Key findings from the evaluation are as follows:
- For non-UDF functions, both ScootR and SparkR provide reliable mapping of R functions to native API calls with overhead below 1.2x.
- With UDFs, ScootRs performance is competitive with SparkR’s STS approach when SparkR is able to use STS, and an order of magnitude faster when SparkR has to fallback to IPC.
- Total overheads in operator pipelines (vs fully native) are up to 1.2x for SparkR with STS, and up to 1.4x for ScootR.
- Both SparkR and ScootR outperform GNU-R and fastR, even for single-threaded execution on a single node.
One possible direction for future work is to integrate other dynamic languages with Truffle support, such as JavasScript or Python.
