Understanding, detecting and localizing partial failures in large system software, Lou et al., NSDI’20
Partial failures (gray failures) occur when some but not all of the functionalities of a system are broken. On the surface everything can appear to be fine, but under the covers things may be going astray.
When a partial failure occurs, it often takes a long time to detect the incident. In contrast, a process suffering a total failure can be quickly identified, restarted, or repaired by existing mechanisms, thus limiting the failure impact.
Because everything can look fine on the surface, traditional failure detectors or watchdogs using external probes or monitoring statistics may not be able to pick up on the problem. Today’s paper choice won the authors a best paper award at NSDI’20. It contains a study of partial failure causes, and a novel approach to fault detection using system-specific, auto-generated watchdogs.
Characterising partial failures
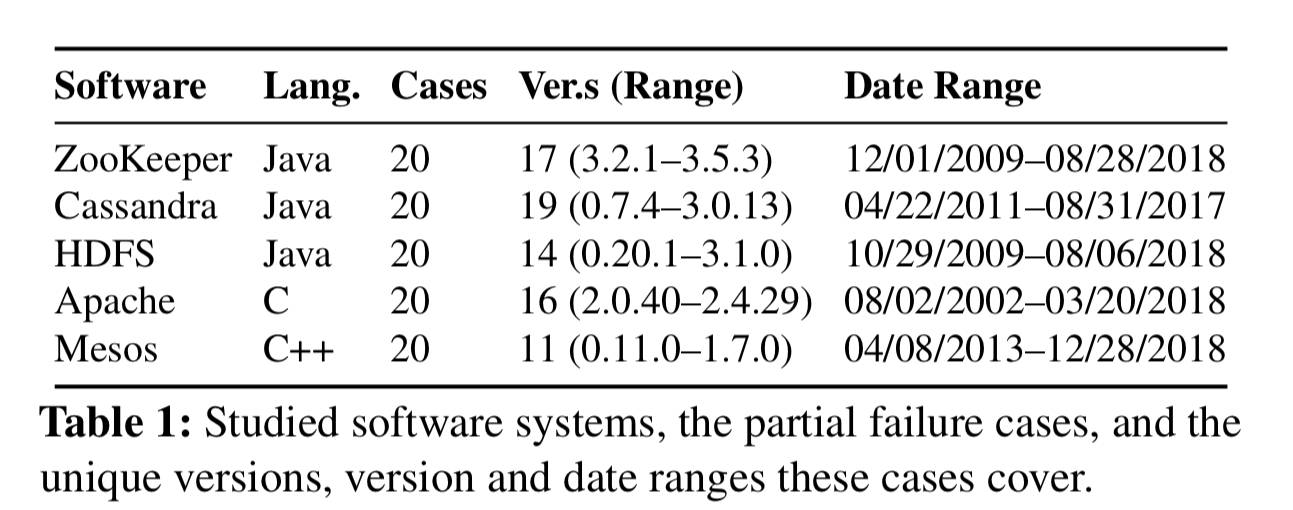
Before designing a better system for detecting partial failures, the authors set about understanding their nature and causes through a study of five software systems (ZooKeeper, Cassandra, HDFS, Apache, and Mesos). For each of these systems they crawled the bug databases to find critical issues and then randomly sampled from those issues until 20 genuine partial failure cases for each system had been collected.
Here are the key findings:
-
Partial failures appear throughout the release history of each system, 54% within the last three years.
-
There are diverse causes for partial failures, with uncaught errors, indefinite blocking, and buggy errory handling the top three, accounting for 48% of all partial failures between them. (See also: ‘Simple testing can prevent most production failures‘ and ‘[What bugs cause cloud production incidents?][]’.

-
48% of partial failures result in some part of the system being unable to make progress (‘stuck’). A further 17% exhibit slow downs big enough to be a serious problem (‘slow’).
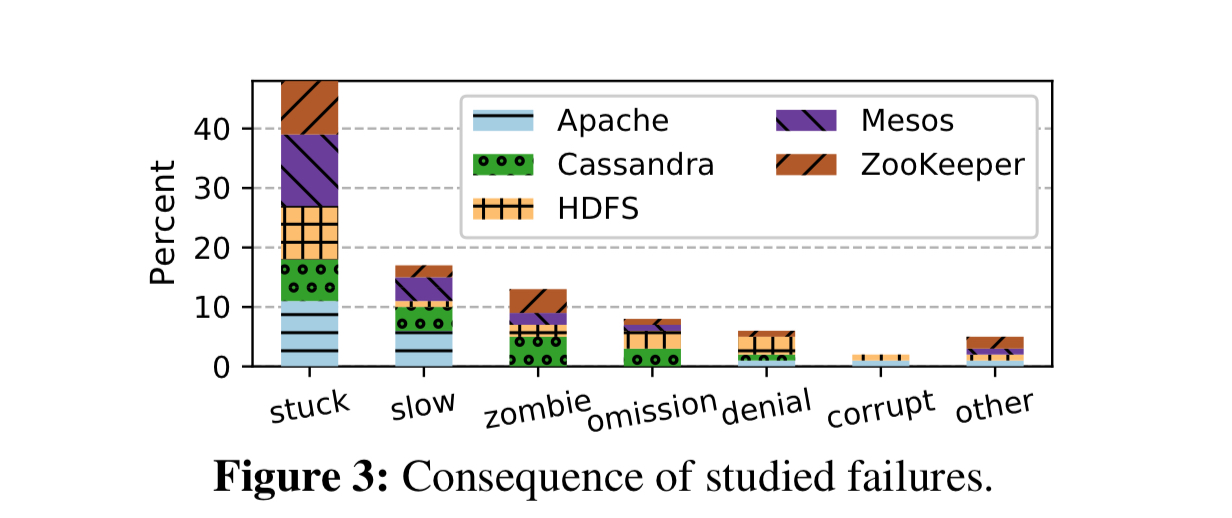
- In 13% of cases a module became a zombie with undefined failure semantics
- 15% of partial failure cases are silent (e.g. data loss, corruption, inconsistency, wrong results)
- 71% of failures are triggered by a specific environment condition, input, or faults in other processes.
- The majority (61%) of partial faults are sticky, i.e. the process will not recover unless some intervention (e.g. a restart) is made.
- It took a median of 6 days and 5 hours to diagnose these issues.
Overall, our study reveals that partial failure is a common and severe problem in large software systems. Most of the studied failures are production-dependent, which require runtime mechanisms to detect.
Detecting partial failures with custom watchdogs
So, we know that we’re going to need runtime detectors. The state-of-the-practice here is API based health-checks. The state-of-the-art is Panorama.
Practitioners currenly rely on running ad-hoc health checks (e.g. send an HTTP request every few seconds and check its response status). But such health checks are too shallow to expose a wide class of failures. The state-of-the-art research work in this area is Panorama, which converts various requestors of a target process into observers to report gray failures of this process. This approach is limited by what requestors can observe externally…
To expose partial failures, a detector needs to exercise specific code regions with carefully-chosen payloads. Heartbeat and HTTP-based tests are too generic and too divorced from the monitored process’ state. So the approach taken by the authors is to use intrinsic watchdogs – these run concurrently with the main program inside the same process. In order to get as close as possible to real program execution conditions, OmegaGen finds long-running methods in the code base, extracts their potentially vulnerable operations, and packages the result in custom generated watchdogs (‘mimic-style checkers‘). It captures the runtime execution context of the main program, and replicates this as input to the watchdogs, which then execute in a sandbox enviroment.
Generate watchdogs proceeds as follows:
- First OmegaGen identifies long-running methods (e.g.
while(true)orwhile(flag)) - Then OmegaGen looks for potentially vulnerable operations in the control flow of those long-running methods. This is largely done based on heuristics (synchronisation, resource allocaion, event polling, async waiting, invocations using external arguments, file or network I/O, complex while loop conditional, and so on). Developers can also explicitly annotate an operation as
@vulnerable - A watchdog replica of the main program is then created my a top-down program reduction from the entry point of long-running methods, retaining only the vulnerable operations in each reduced method. The resulting program preserves the original structure, and contains all vulnerable operations.
- OmegaGen then inserts hooks that capture context from the main program execution and pass it to the watchdog so that the watchdog executes with the same key state as the original.
- Finally, OmegaGen adds checks in the watchdog to catch failure signals from the execution of vulnerable operations. Liveness checks are made by setting a timer before runner a checker (default 4 seconds). Safety checks rely on the vulnerable operations to emit explicit error signals (e.g. exceptions), and will also capture runtime errors.

The watchdog driver runs the watchdogs and captures information on any detected error. Before reporting an error, a validator runs to ensure it is a genuine error. The default validator simply re-executes the checker and compares the result, which is effective in the case of transient errors. Developers can provide their own validator functions if desired.
All in, OmegaGen is about 8Kloc of Java code, making use of the Soot analysis framework.
OmegaGen in action
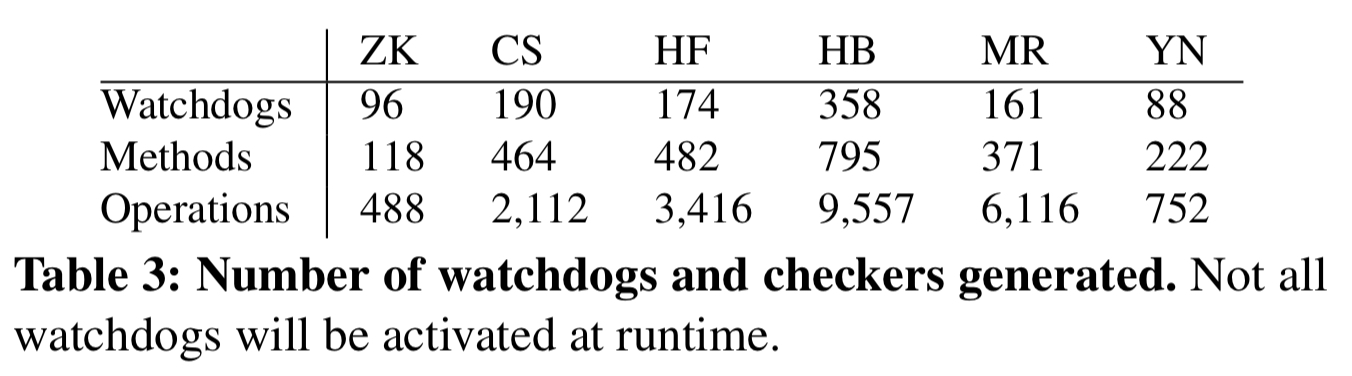
OmegaGen is evaluated using ZooKeeper, Cassandra, HDFS, HBase, MapReduce, and Yarn. It generates 10s to 100s of watchdogs for each system, configured to run checks every second. Generating the watchdogs takes from 5 to 17 minutes depending on the size of the system.
22 real-world partial failures across these six systems were then collected and reproduced. The ability of OmegaGen to detect these failures was then tested against four different baseline detectors, as shown in the following table (the existing system built-in detectors can’t handle partial failures at all).

The OmageGen watchdogs detected 20 out of the 22 issues, whereas the best baseline detector managed only 11, and all of the other three detectors combined can only manage 14. The median detection time was 4.2 seconds.

The OmegaGen watchdogs are also able to pinpoint the source of the error much more accurately than the baseline detectors (which in e.g. the client and resource detector cases can only point to the faulty process).
![]]TABLE6
A random fault injection test on the latest version of ZooKeeper triggered 16 synthetic failures, 13 of which were detected with a median detection time of 6.1 seconds. The OmegaGen watchdogs also found a genuine bug in version 3.5.5 of ZooKeeper which was confirmed by the developers and fixed.
OmegaGen watchdogs add a 5.0-6.6% overhead in terms of system throughput.
The last word
Evaluating OmegaGen on six large systems, it can generate tens to hundreds of customized watchdogs for each system. The generated watchdogs detect 20 out of 22 real-world partial failures with a median detection time of 4.2 seconds, and pinpoint the scope of failure for 18 cases; these results significantly outperform the baseline detectors.

{kind=link}
Hi Adrian, as a loyal reader of your blog, it’s really exciting to read your digest of our paper on a platform I read every week. Excellent review that I would recommend to people and we feel happy to see our work arises some interests. I’ve added a link to this article on my personal page.
Btw, please excuse me to use the comment section space to add a little more clarifications to address potential confusions (indeed we should make all these more clear in the paper! but putting everything in strict 12-pages is hard): 1) the definition of “partial failures” in this work is not strictly overlapped with “gray failures” in our previous work. The partial failures we study are focusing on program partially fail on process-level (e.g. a thread crashes), while “gray failures” could refer to service-level failures (e.g. a service instance, which is a standalone process, exit). 2) watchdog runs not strictly in a sandbox environment since that would prevent the watchdog from sharing the same environment of the main program, which might be the key for it to expose problems. So we use a state-replication approach, not so safe and trickier to operate, but it brings detection benefits :)
Looks like you’re missing a link to: https://blog.acolyer.org/2019/06/21/what-bugs-cause-cloud-production-incidents/