An empirical guide to the behavior and use of scalable persistent memory, Yang et al., FAST’20
We’ve looked at multiple papers exploring non-volatile main memory and its implications (e.g. most recently ‘Efficient lock-free durable sets‘). One thing they all had in common is an evaluation using some kind of simulation of the expected behaviour of NVDIMMs, because the real thing wasn’t yet available. But now it is! This paper examines the real-world behaviour of Intel’s Optane DIMM, and finds that not all of the assumptions baked into prior works hold. Based on these findings, the authors present four guidelines to get the best performance out of this memory today. Absolutely fascinating if you like this kind of thing!
The data we have collected demonstrate that many of the assumptions that researchers have made about how NVDIMMs would behave and perform are incorrect. The widely expressed expectation was that NVDIMMs would have behavior that was broadly similiar to DRAM-based DIMMs but with lower performance (i.e., higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest.
Optane DIMMs are here!
The Optane DIMM is the first scalable, commercially available NVDIMM.
Optane DIMMs have lower latency and higher bandwidth than storage devices connected over PCIe (including Optane SSDs), and present a memory address-based interface as opposed to a block-based NVMe interface. Compared to DRAM they offer higher density and persistence. You can buy it in 128, 256, and 512 GB capacities. An Intel CascadeLake processor die can support up to six Optane DIMMs across its two integrated memory controllers (iMCs), so that’s up to 3TB of persistent memory.
The iMC maintains separate read and write pending queues for each DIMM. Once data has reached these queues it is durable. An on-DIMM controller (the XPController) coordinates access to the Optane media with internal address translation for wear-leveling and bad-block management. The physical media is accessed in chunks of 256 bytes (an XPLine). Smaller requests are translated into larger 256-byte accesses causing write amplification. The XPController has a small XPBuffer used for write-combining.
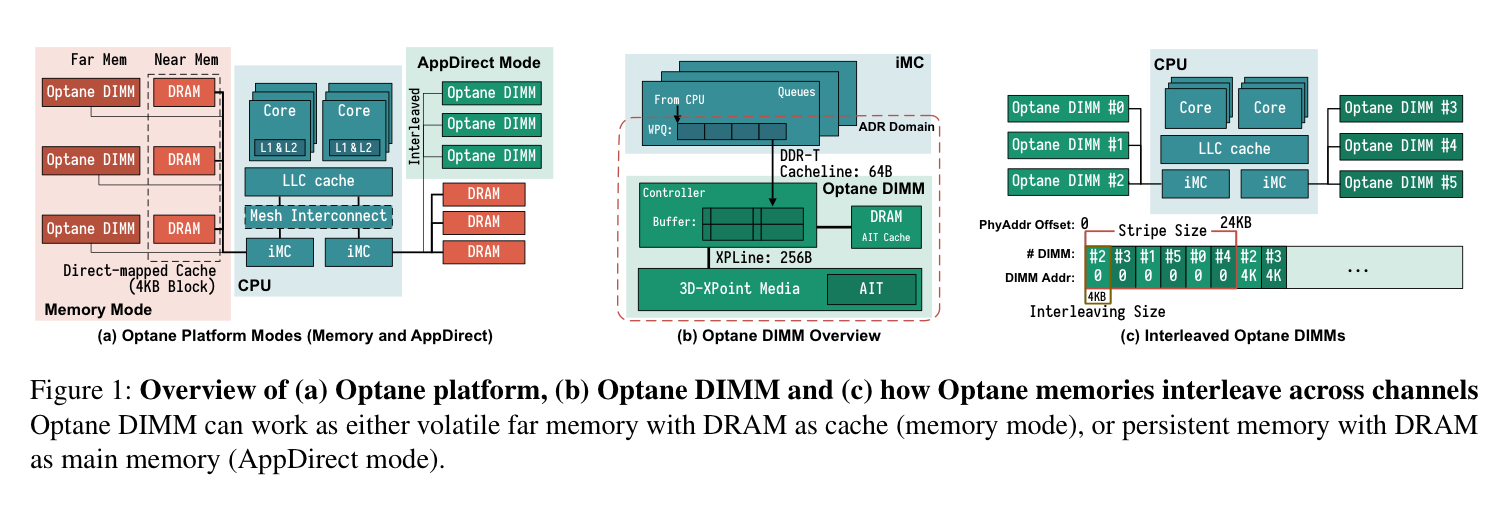
There are two modes of operation: Memory mode and App Direct mode. In memory mode the Optane DIMMs are used to expand memory capacity, without exploiting persistence. App Direct mode is the one generating all the excitement – here the Optane DIMM appears as a separate persistent memory device. Applications and files systems access App Direct memory using CPU instructions offering a variety of options for controlling the ordering of store operations: cache-line flush, cache-line write back, and non-temporal stores (bypassing the cache hierarchy). An sfence is needed to ensure that these stores are complete and persistent.
Understanding Optane DIMM performance
A Linux persistent memory (pmem) namespace can be backed by interleaved or non-interleaved Optane memory, or emulated persistent memory backed by DRAM. The authors evaluate App Direct mode Optane memory for each backing type. In what follows, the Optane baseline is six DIMMs from the same socket in a single interleaved namespace, and OptaneNI is a single Optane DIMM (hence no interleaving).
Our investigation of Optane memory behavior proceeds in two phases. First, we performe a broad systematic "sweep" over Optane configuration parameters including access patterns (random vs sequential), operations (loads, stores, fences, etc.), access size, stride size, power budget, NUMA configuration, and address space interleaving. Using this data, we designed targeted experiments to investigate anomalies and verify or disprove our hypotheses about the undelying causes…
About ten thousand data points were collected altogether, see https://github.com/NVSL/OptaneStudy.
- The read latency for Optane is 2x-3x higher than DRAM. **Optane memory is also more pattern-dependent than DRAM. The random-vs-sequential gap is 20% for DRAM but 80% for Optane memory, and this gap is a consquence of the XPBuffer.
- Loads and stores have very consistent latency, except for a few outlier cases which correlate with hot spot concentration. These spikes are rare (about 0.006% of accesses), but have latency two orders of magnitude higher than regular accesses. "We suspect this effect is due to remapping for wear-levelling or thermal concerns, but we cannot be sure."
- Whereas DRAM bandwidth is higher than Optane and scales predictably and monotonically with thread count until the bandwidth is saturated, the results for Optane are wildly different. Optane has a bigger gap between read and write bandwidth (2.9x read over write, versus 1.3x for DRAM), and non-monotonic performance with increasing thread count. Bandwidth for random accesses under 256 B is also poor.
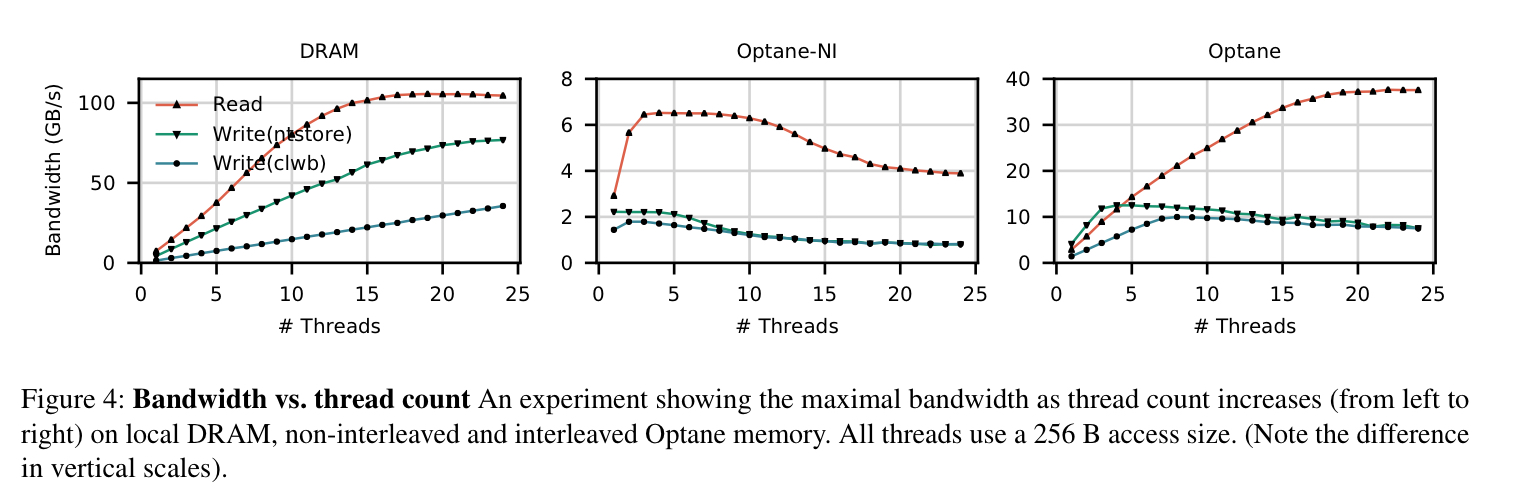
The impact of access size on bandwidth shows some marked differences between DRAM (left) and Optane:
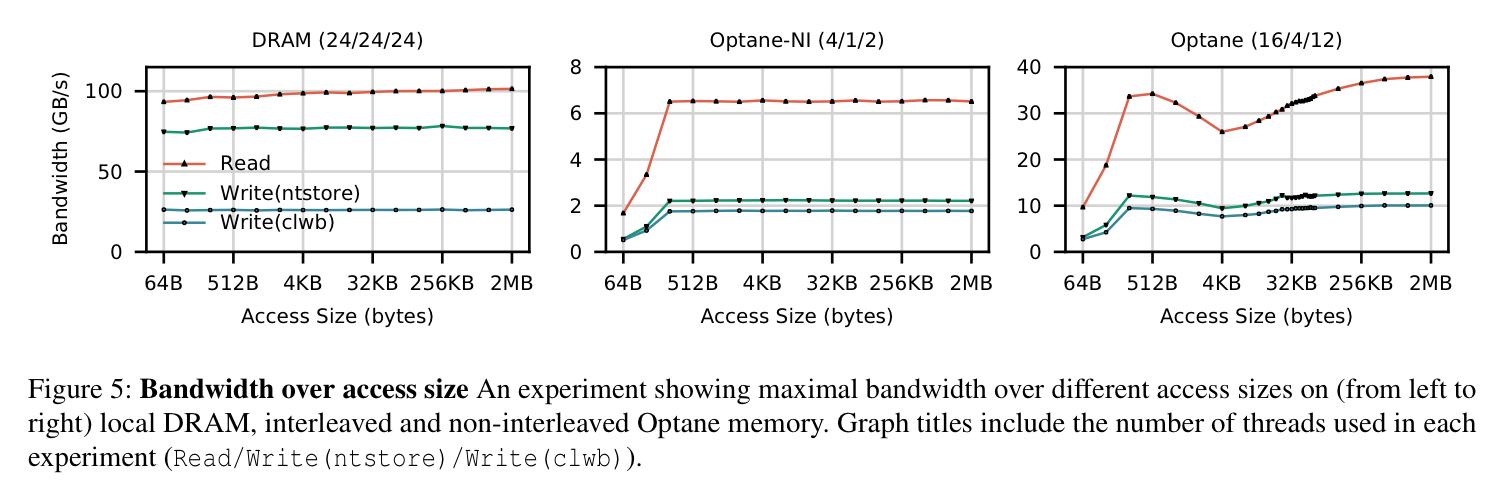
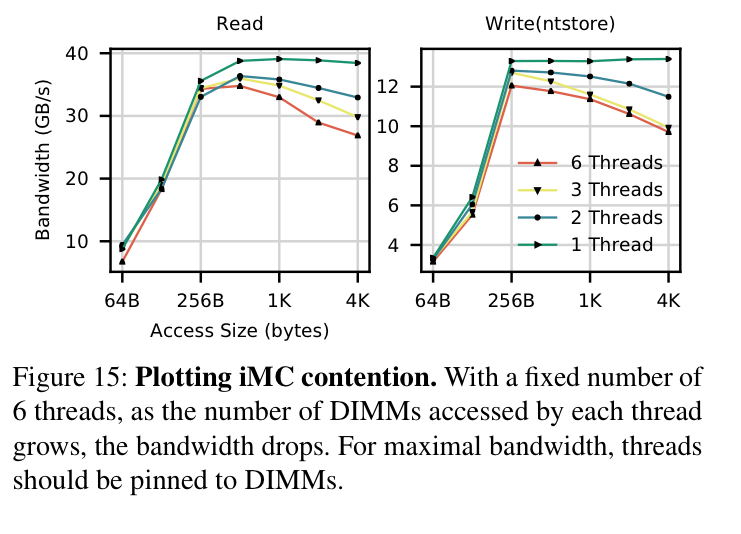
The most striking feature of the graph is a dip in performance at 4 kB – this dip is an emergent effect caused by contention at the the iMC, and it is maximised when threads perform random accesses close to the interleaving size.
Importantly for prior works, real Optane memory behavior can deviate drastically from that predicted by emulation mechanisms, which "fail to capture Optane memory’s preference for sequential accesses and read/write asymmetry, and give wildy inaccurate guesses for device latency and bandwidth."
Those differences really matter. For example, a study that looked at adapting RocksDB to use persistent memory (amongst many other systems) concluded that a fine-grained persistent memory approach worked better than moving the write-ahead log to persistent memory. But with real Optane performance characteristics, the opposite is true.
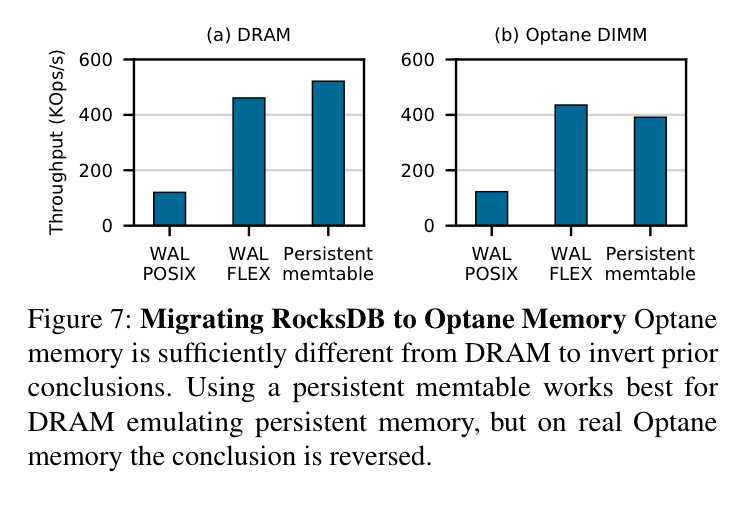
Making the most of your memory
So now that we know the truth about the way Optane DIMMs in App Direct mode behave, how should we design our systems to get the best out of them? The authors give us four guidelines to follow:
- Avoid random accesses smaller than 256 B (and where that is not possible, limit the working set to 16 kB per Optane DIMM)
- Use non-temporal stores for large transfers, and control cache evictions
- Limit the number of concurrent threads accessing an Optane DIMM
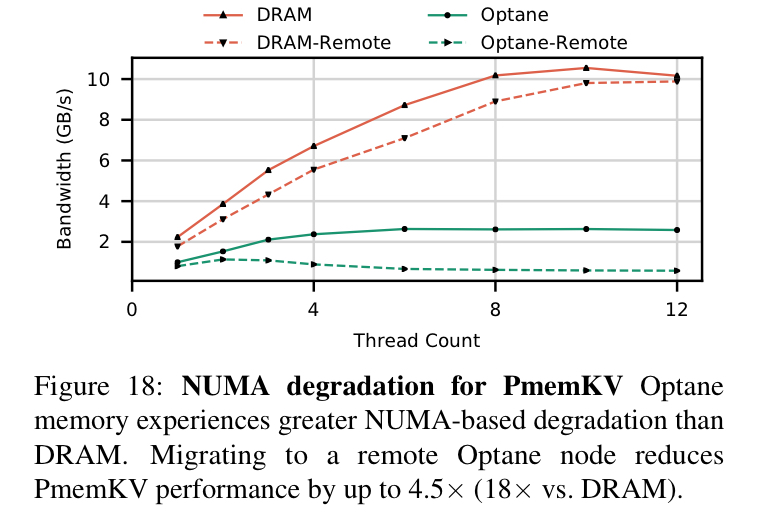
- Avoid NUMA accesses (especially read-modify-write sequences)
A metric that underpins several of these recommendations is the Effective Write Ratio or EWR.
EWR is the ratio of bytes issue by the iMC divided by the number of bytes actually written to the 3D-XPoint media (as measured by the DIMM’s hardware counters). EWR is the inverse of write amplification. EWR values below one indicate the Optane DIMM is operating inefficiently since it is writing more data internally than the application requested. The EWR can also be greater than one, due to write-combining at the XPBuffer.
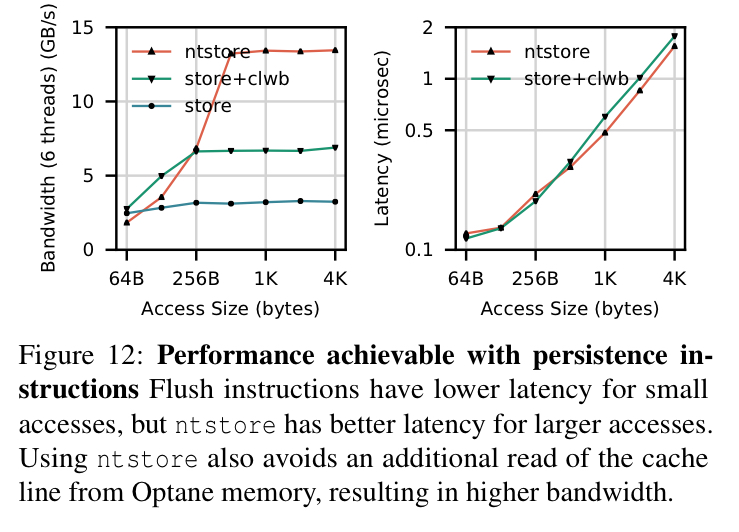
For small accesses flush instructions have lower latency, but for larger accesses ntstore is better. Flushing after each 64 B improves bandwith for accesses greater than 64 B. "We believe this occurs because letting the cache naturally evict cache lines adds non-determinism to the access stream that reaches the Optane DIMM." The EWR measurements shows that adding these flushes increase EWR from 0.26 to 0.98.
With too many concurrent threads, contention over the XPBuffer drives down EWR. Limited queue capacity in the iMC also hurts performance when multiple cores target a single DIMM. "Our hypothesis is that, since Optane DIMMs are slow, they drain the WPQ slowly, which leads to head-of-line blocking effects."
NUMA impacts Optane much more than DRAM, and the effect is especially acute with mixed loads and stores across multiple threads: the performance gap between local and remote Optane memory for the same workload can be over 30x, whereas for DRAM its closer to 3.3x.
Section 5 in the paper, in addition to discussing these guidelines, also contains illustrative examples of the impact of adhering to them in real systems (vs prior evaluations done with emulation):
- RocksDB improves EWR from 0.434 to 0.99
- The NOVA NVMM file system improves write performance by up to 7x.
- Micro-buffering in Intel’s PMDK is improved by using normal stores with flushes (instead of non-temporal stores) for small objects
- Multi-NVDIMM NOVA improves bandwidth by 3-34% by limiting the number of writers per DIMM
Watch this space
The guidelines… provide a starting point for building and tuning Optane-based systems. By necessity, they reflect the idiosyncracies of a particular implementation of a particular persistent memory technology, and it is natural to question how application the guidelines will be to both other memory technologies and future versions of Intel’s Optane memory… We believe that our guidelines will remain valuable both as Optane evolves and as other persistent memories come to market.
