Gray failure: the Achilles’ heel of cloud-scale systems Huang et al., HotOS’17
If you’re going to fail, fail properly dammit! All this limping along in degraded mode, doing your best to mask problems, turns out to be one of the key causes of major availability breakdowns and performance anomalies in cloud-scale systems. Today’s HotOS’17 paper is a short piece discussing Microsoft Azure experiences with such gray failures.
… cloud practitioners are frequently challenged by gray failure: component failures whose manifestations are fairly subtle and thus defy quick and definitive detection. Examples of gray failure are severe performance degradation, random packet loss, flaky I/O, memory thrashing, capacity pressure, and non-fatal exceptions.
Just like all the other kinds of failures, the larger your scale, the more common gray failures become. Common enough indeed that:
Our first-hand experience with production cloud systems reveals that gray failure is behind most cloud incidents.
A definition of gray failure
First we need to understand the enemy. Anecdotes of gray failure have been known for years, but the term still lacks a precise definition.
We consider modeling and defining gray failure a prerequisite to addressing the problem.
The model proposed by the authors is the result of an extensive study of real incidents in Azure cloud services. It’s all a question of perspective.
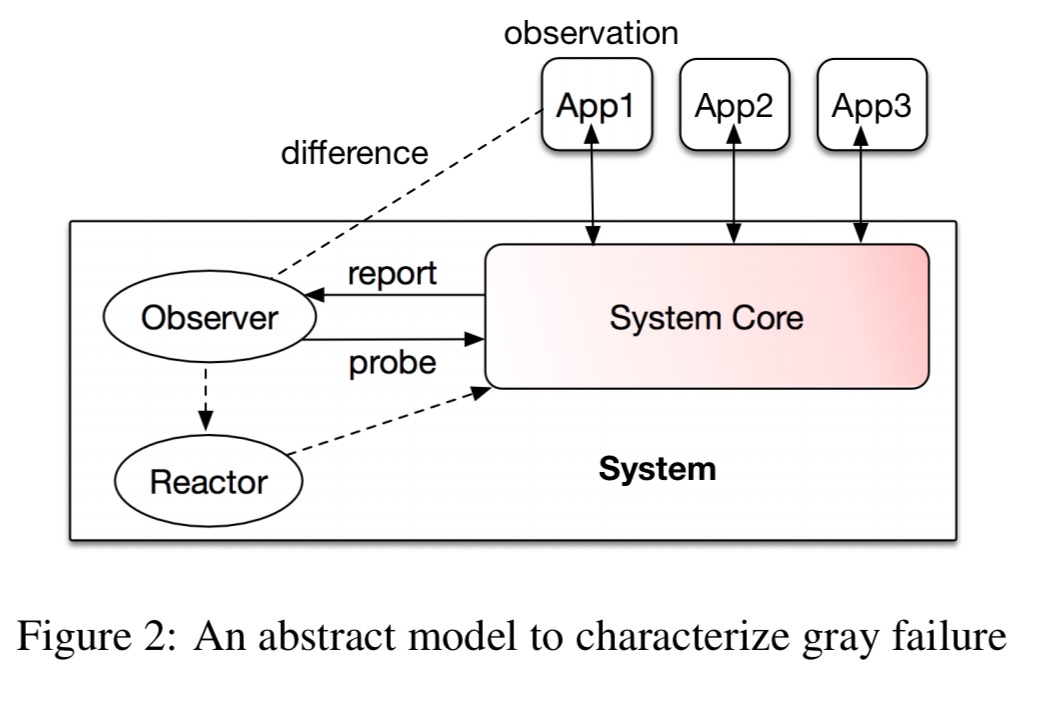
Consider some system being monitored by a failure detector (observer in the figure above). If the observer detects a fault, a reactor takes action (for example, restarting components). Meanwhile, there are all kinds of clients (apps in the figure above) using the system. By virtue of interacting with it, these apps make their own observations of the health of the system (are responses slow, errors being reported, etc..). Cloud systems may be used simultaneously by many different kinds of apps, each with their own perspective on the health of the system.
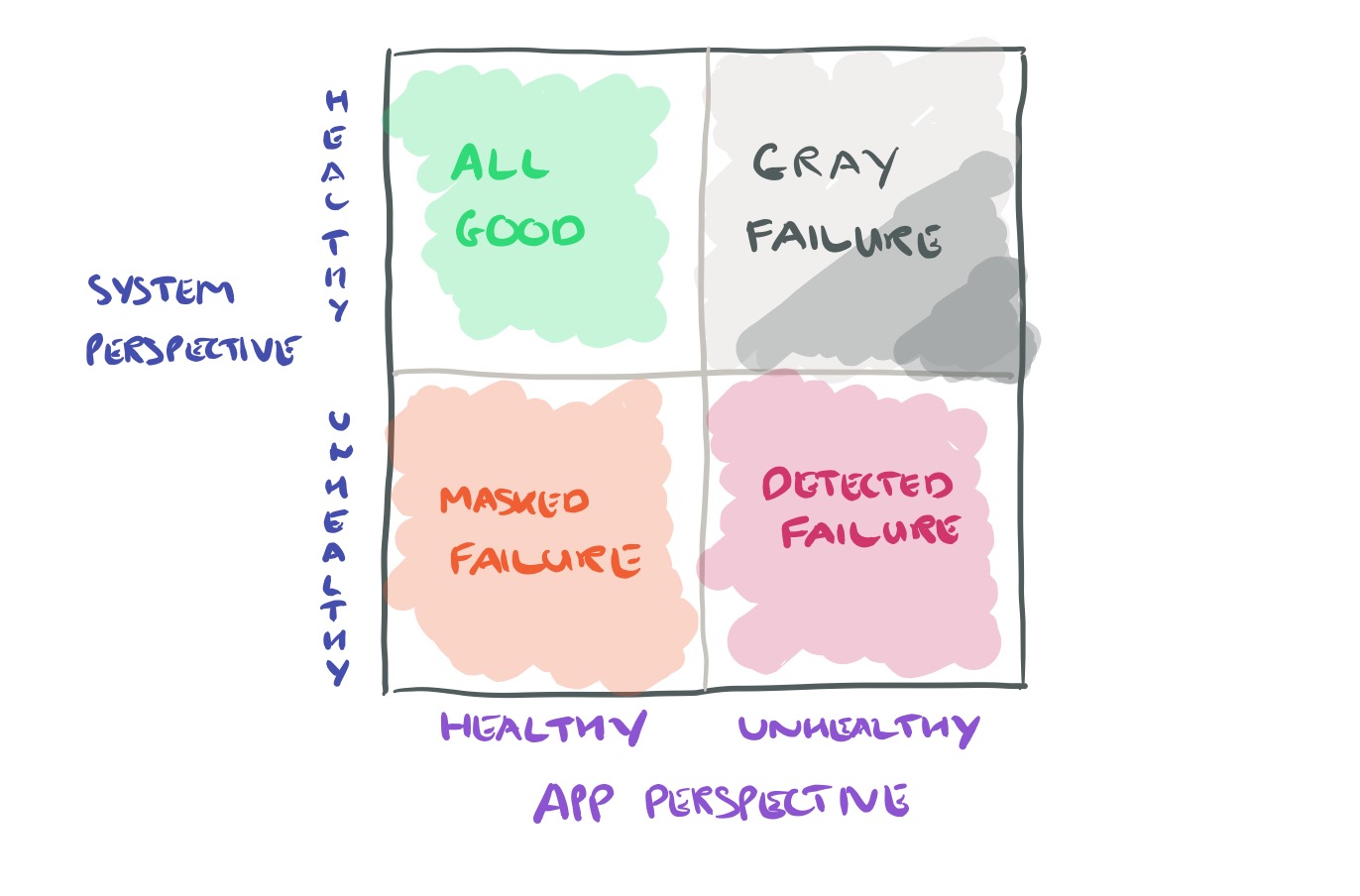
We define gray failure as a form of differential observability. More precisely, a system is defined to experience gray failure when at least one app makes the observation that the system is unhealthy, but the observer observes that the system is healthy.
Considering the system and its client apps, we can draw the following quadrant of gray:
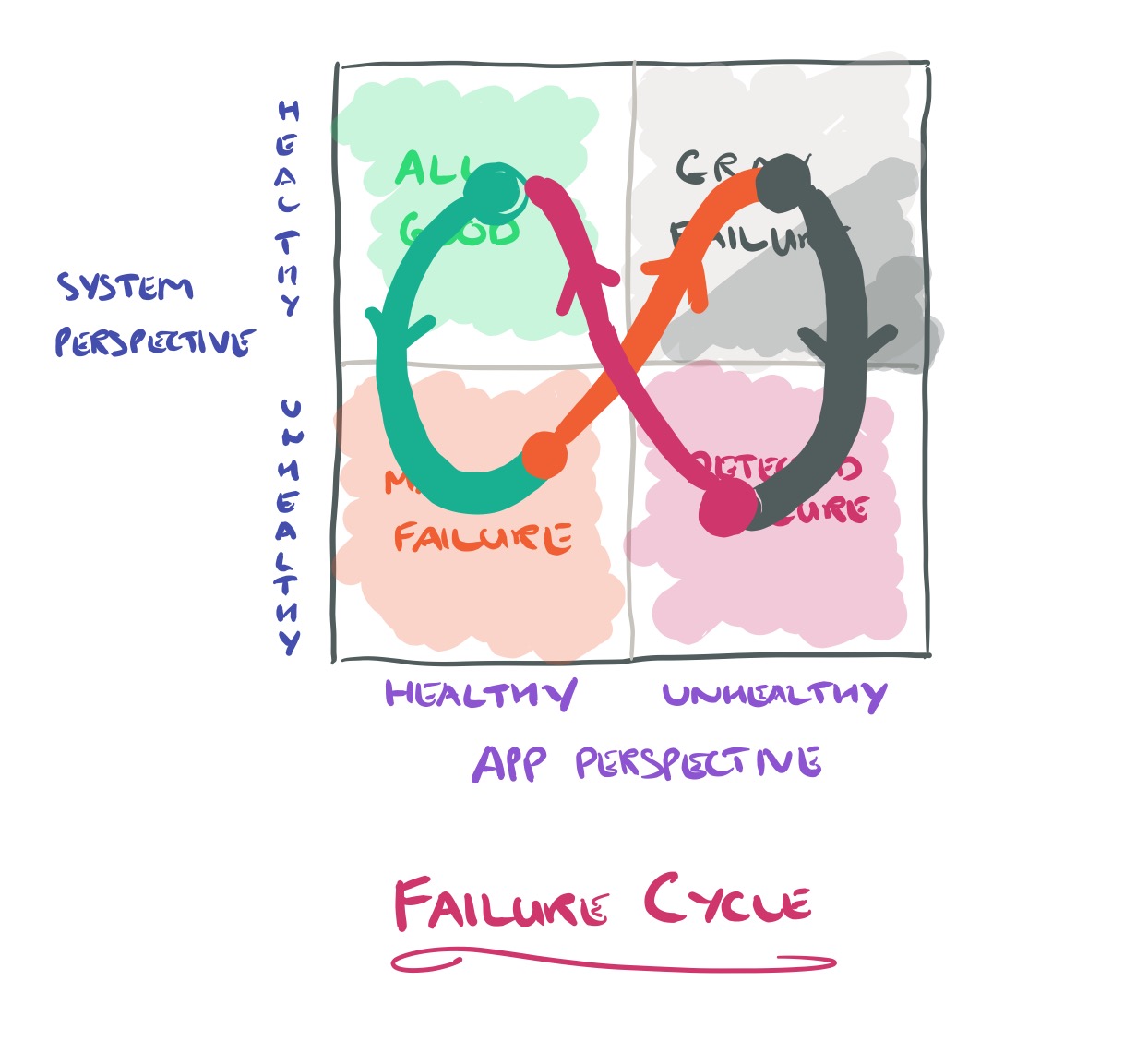
There’s also a cycle of gray that many systems tend to follow:
… initially the system experiences minor faults (latent failure) that it tends to suppress. Gradually, the system transits into a degraded mode (gray failure) that is externally visible but which the observer does not see. Eventually the degradation may reach a point that takes the system down (complete failure), at which point the observer also realizes the problem. A typical example is a memory leak.
During a gray failure with intermittent misbehaviour, we can go round the cycle many times.
Gray failure examples
Let’s look at some gray failure examples from the Azure world to make this all a bit more concrete.
More redundancy == less availability !?
Data center networks can route around failing switches, but typically do not re-route packets when switches experience intermittent failures such as random and silent packet drops. The gray failure results in application glitches or increased latency.
As a consequence, we sometimes see cases were increasing redundancy actually lowers availability.
Just as with tail latency, the chances of experiencing this go up exponentially with the fan-out factor (number of services involved) in processing a given request. If we have n core switches (or indeed, any n resources used to process requests) then the probability that a certain switch is traversed by a request is given by 
This probability rapidly approaches 100% as m becomes large, meaning each such request has a high probability of involving every core switch. Thus a gray failure at any core switch will delay nearly every front-end request.
The more switches you have (for example, for increased redundancy), the more likely at least one of them will experience a gray failure!
Works for me!
The authors describe incidents where unhealthy VMs are internally experiencing severe network issues, but the failure detector is receiving heartbeats via a host agent that communicates with the VM using local RPC. Thus the problem is never spotted and no recover happens until a user reports an issue. This leads to long gaps between the point of user impact and the point of resolution.
When the cure is worse than the disease
An Azure storage data server was experiencing severe capacity constraint, but a bug caused the storage manager not to detect the condition. As the storage manager sent more requests to the overloaded data server it eventually crashed and rebooted, which did not fix the underlying problem so the cycle repeated.
The failure detector did pick up on the continual rebooting, concluded the data server was irreparable and took it out of service. This put pressure on the remaining healthy servers, causing more servers to degrade and experience the same ultimate fate.
Naturally, this eventually led to a catastrophic cascading failure.
(Aside, it sounds like they need a back-pressure mechanism!).
Finger-pointing at dawn
VMs run in compute clusters, and their virtual disks lie in storage clusters accessed over the network. Sometimes a storage or network issue means a VM can’t access its virtual disk, which can lead to a crash.
If no failure detector detects the underlying problem with the storage or network, the compute-cluster failure detector may incorrectly attribute the failure to the compute stack in the VM. For this reason, such gray failure is challenging to diagnose and
respond to. Indeed, we have encountered cases where teams responsible for different subsystems blame each other for the incidents since no one has clear evidence of the true cause.
Protecting against gray failures
First note that the standard distributed systems mechanisms for availability don’t work well with gray failures because such failures are not part of their failure model:
A myriad of techniques have been proposed to leverage redundancy and replication to tolerate component faults, e.g., primary/backup replication, RAID, Paxos, and chain replication. Many of these techniques assume a simple failure model: fail-stop. Different from fail-stop, a component experiencing gray failure appears to be still working but is in fact experiencing severe issues. Such discrepancy can negatively impact traditional techniques and cause fault-tolerance anomalies.
The next thought that went through my mind was “Isn’t this just inadequate monitoring?” If you want to understand how well your website is performing for example, send it external requests similar to the ones that users will submit. Under that hypothesis the differential observability problem is caused by insufficient/inappropriate observations that don’t capture what truly matters to the client.
Although it would be ideal to eliminate differential observability completely by letting the system measure what its apps observe, it is practically infeasible. In a multi-tenant cloud system that supports various applications and different workloads, it is unreasonable for a system to track how it is used by all applications.
There’s a deeper problem lurking here too, which goes back to the binary fail-stop model. Failure detectors typically send an “it failed” message which then initiates recovery, but gray failure is not such a black-and-white issue.
A natural solution to gray failure is to close the observation gaps between the system and the apps it services. In particular, system observers have traditionally focused on gathering information reliably about whether components are up or down. But, gray failure makes these not just simple black-or-white judgements. Therefore, we advocate moving from singular failure detection (e.g., with heartbeats) to multi-dimensional health monitoring.
Another way to increase the chances of closing the observation gap is to combine observations from many different vantage points.
… since gray failure is often due to isolated observations of an observer, leveraging the observations from a large number of different components that are complementary to each other can help uncover gray failure rapidly. Indeed, many gray failure cases we investigated are only detectable in a distributed fashion because each individual component has only a partial view of the entire system (so the gray failures are intrinsic).
Exactly how to do this is an open question. If the observations are taken close to the core of the system for example, they may not see what the clients see. But if taken near the apps, built-in fault tolerance mechanisms may mask faults and delay detection of gray failures.
We envision an independent plane that is outside the boundaries of the core system but nevertheless connected to the observer or reactor.
This sounds very like a classic centralised control style solution to me (I could well be wrong, we only have this one sentence to go on!). I wonder what a solution starting from the premises of promise theory might look like instead?
A final technique that may help with gray failure comes through understanding how the gray failure cycle evolves over time. If these timeseries patterns can be learned, then we can predict more serious failures and react earlier. Since many faults truly are benign though, care must be taken not to do more harm than good.
The last word
As cloud systems continue to scale, the overlooked gray failure problem becomes an acute pain in achieving high availability. Understanding this problem domain is thus of paramount importance… We argue that to address the problem, it is crucial to reduce differential observability, a key trait of gray failure.

How about a QoS API for the apps to feed back their actual experience to the out-of-core ‘quality reconciliation system’, which is also connected to the core observer-reactor. In many cases this could just be instrumentation within an app client library supplied by the cloud provider.
Before reading what the authors suggested for protecting against gray failures, I wrote down what I would suggest.
1. You don’t have to detect them, but you can do corrections proactively and preemptively. Rejuvenate software by resetting parts. This takes care of memory leaks. Randomize which routers you use (and actually through these you will be able to observe performance difference and pinpoint the problematic routers).
2. The detection of these latent partial failures would involve cooperation at every layer of the stack. Randomizing the detector would help, that is have multiple detectors (at different perspectives) rotating the monitoring responsibility of the service. Also having an API where even clients can file complaints/suspicions can help. (Masking small faults is good, but even then these should be logged, and a complaint filed.) Of course you shouldn’t immediate act on these, otherwise this suspicion mechanism could become the Achilles heel of the system, a paranoid node could do disproportional damage thinking that other services rather than itself is the problem. There should be a verification mechanism, maybe through redundancy would be needed. Or at least use a consensus box to make system-wide consistent (even if not 100% accurate) decision about the situation, and make this visible/accessible to every service so there is no uncertainty about the verdict.
My point 2 has parallels with what the authors suggest with multidimensional health monitoring.
That’s a fantastic thought exercise to go through before reading the author’s solution!
As it seems that you need fault-tolerance in order to enter a gray state, perhaps monitoring when and how frequently faults are handled would provide the information needed to identify that a gray state has been entered, and also give hints as to the cause. Furthermore, with a suitable model of the system, it might be possible to predict when the cascading faults that lead to systemic failure are imminent.
To avoid generating excessive information, some of these data could be reduced to aggregates (especially for low-level subsystems), such as the rate or ratio of dropped packets.
One big obstacle to this approach is that it requires all (or most) subsystems to participate; it is not something that could be layered on top of most existing systems.
Hystrix to the rescue!
It allows observer to look through the lenses of reactor.
Thank you for this Adrian! This article inspired me to start writing..
My first two articles are about detecting and diagnosing Grey Failures; techniques I’ve been using for about a decade.
http://billduncan.org/
See my article on “Shades of Grey”
Thanks again!
I’m coming from a different context and don’t see how you got your probability formula based on the configuration that I’m imaging (and might be wrong). Can you/someone give more details about the configuration and how you arrived at the formula?