Automating chaos experiments in production Basiri et al., ICSE 2019
Are you ready to take your system assurance programme to the next level? This is a fascinating paper from members of Netflix’s Resilience Engineering team describing their chaos engineering initiatives: automated controlled experiments designed to verify hypotheses about how the system should behave under gray failure conditions, and to probe for and flush out any weaknesses. The ‘controlled’ part is important here because given the scale and complexity of the environment under test, the only meaningful place to do this is in production with real users.
Maybe that sounds scary, but one of the interesting perspectives this paper brings is to make you realise that it’s really not so different from any other change you might be rolling out into production (e.g. a bug fix, configuration change, new feature, or A/B test). In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong. Moreover, just like an A/B test, we’ll be collecting metrics while the experiment is underway and performing statistical analysis at the end to interpret the results.
Netflix’s system is deployed on the public cloud as complex set of interacting microservices.
In this type of environment, there are many potential sources of failure, stemming from the infrastructure itself (e.g. degraded hardware, transient networking problem) or, more often, because of some change deployed by Netflix engineers that did not have the intended effect.
They use a combination of timeouts, retries, and fallbacks to try to mitigate the effects of these failures, but these don’t get exercised as often as the happy path, so how can we be confident they’ll work as intended when called upon? (And on top of that, there are all of the hard-to-predict emergent behaviours arising from interactions between multiple components). Netflix have a ChAP whose role it is to help provide that confidence: a Chaos Automation Platform.
The Chaos automation platform
ChAP runs chaos engineering experiments within Netflix’s production systems.
Most ChAP experiments focus on evaluating whether the overall system would remain healthy if one of the services degraded. Two failure modes we focus on are a service becoming slower (increase in response latency) or a service failing outright (returning errors).
ChAP works with a number of other Netflix systems to carry out its tasks: FIT for fault injection, Spinnaker for provisioning baseline and canary clusters, Zuul to manage user traffic routing to the canary or baseline, Atlas and Mantis for telemetry during the experiment, Lumen dashboards for displaying metrics data, and the Kayenta automated canary analysis system.
An example hypotheses to be tested is that users should still be able to stream video even if the bookmarking service (which remembers their last watched location in a video) is down. To test this a Netflix engineer can create an experiment using the ChAP UI, “fail RPCs to the bookmark service and verify the system in general and the API service in particular remain healthy.”
Typically the baseline and canary clusters deployed for an experiment will be 1% of the size of the original cluster. Users selected (by Zuul) to be part of the canary group will be routed to the canary cluster with an additional fault-injection rule to fail calls to the bookmark service.
There are two main classes of metric we use to determine whether the injected fault has had a negative impact on system health: (i) key performance indicators (KPIs) for the users in the canary group versus the baseline group; (ii) health metrics for the canary cluster versus the baseline cluster.
After the experiment ends, Kayenta performs a statistical analysis of metrics collected from the canary cluster and compares them to those from the baseline cluster, to determine if there has been a statistically significant impact on any metrics of interest.
While Kayenta was originally designed for evaluating the health of canary deployments, we found it to be an excellent match for analyzing the results of ChAP experiments.
Safeguards
ChAP has a number of safeguards in place to minimise the blast radius of experiments:
- Experiments are only run during business hours on weekdays
- Experiments are not run when a region is failed-over for independent reasons
- The set of all concurrently executing ChAP experiments (yes, there can be lot of them executing pretty much continuously, which is where the dedicated baseline and canary clusters come in) cannot impact more than 5% of the total traffic in any one geographical region.
- If ChAP detects excessive customer impact during an experiment, the experiment is stopped immediately
Defining and running experiments
Initially ChAP was rolled out with a self-serve model whereby teams could define and run their own experiments. This mode is still available but take up from busy service teams was limited. So the Resilience Engineering team developed Monocle, a service for automatically uncovering service dependencies, and using this information to automatically generate and execute experiments.
The early failure injection testing mechanisms from Chaos Monkey and friends were like acts of random vandalism. Monocle is more of an intelligent probing, seeking out any weakness a service may have.
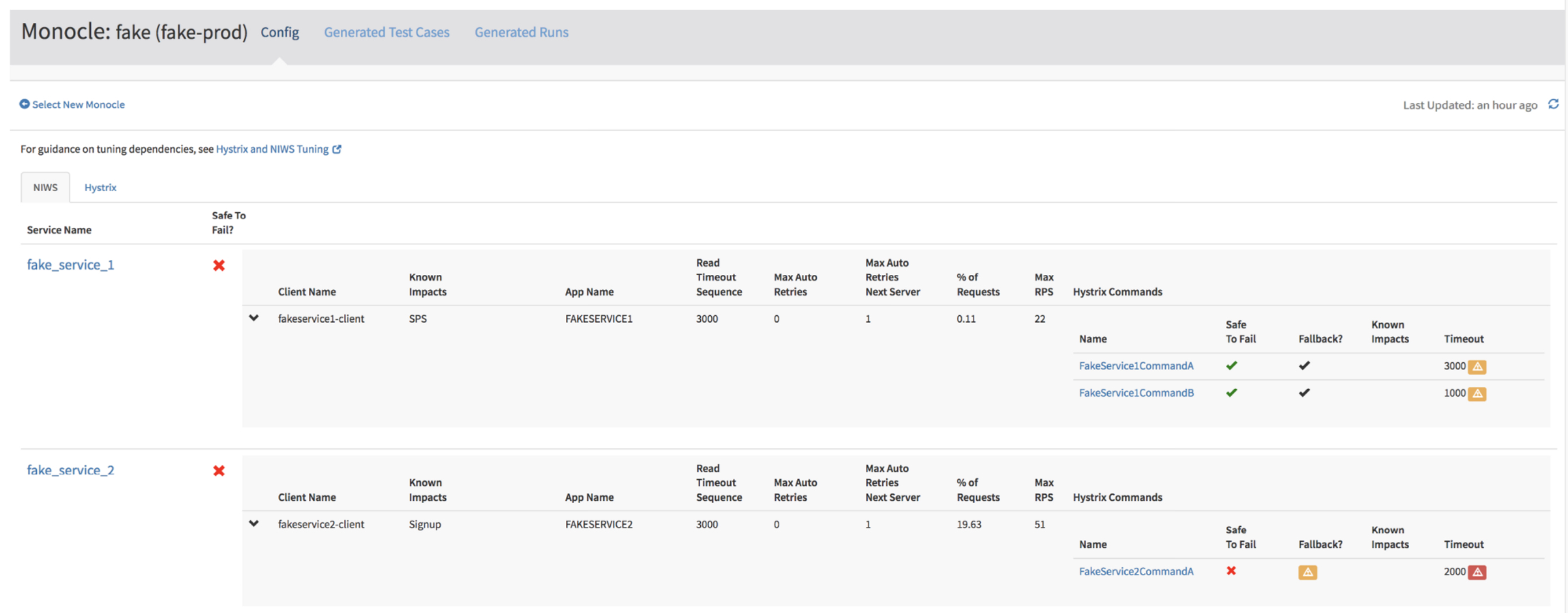
The dependency analysis part of Monocle is pretty cool all by itself, even before we get to the experiment generation. Monocle grabs data from the Atlas telemetry system, the tracing system, and by querying runtime servers for configuration information such as time values. RPCs at Netflix are wrapped as Hystrix commands. For each such command, Monocle shows the following information:
- Percentage of inbound requests triggering an invocation of the command
- Whether it is believed to be safe to fail
- Whether it is configured with a fallback
- The configured timeouts
- The observed latencies over the last 2 weeks (P90, P99, P99.5)
- The thread pool size
- The observed number of active threads over the past two weeks
- Which RPC clients the command wraps, if any
- Any known impacts associated with the command
For every RPC client Monocle shows:
- Timeout and retry configurations
- Percentage of inbound requests triggering an RPC call
- Maximum observed invocation rate in the past 2 weeks
- Which Hystrix commands wrap it, if any, and if they are safe to fail
- Any known impacts associated with the RPC client or the commands that wrap it.
(Enlarge)
In the dashboard screenshot above you can see yellow and red attention icons highlighting warnings and vulnerabilities. These have tooltips with more detail, for example:
Warning: Hystrix Command Timeout is Misaligned with RPC Client.
Timeout (1000 ms) is less than the max computed timeout of the wrapped RPC client (4000 ms). This means that Hystrix will give up waiting on RPC…
Using all this information, Monocle generates resilience experiments automatically for RPC client and Hystrix command dependencies. For each dependency there are three basic experiment types:
- Failure
- Latency just below the configured timeout (highest timeout – P99 latency over the past 7 days + 5% buffer)
- Latency causing failure (highest configured timeout + 5% buffer)
As you can imagine, with lots of services and large fan-outs, that’s a lot of potential experiments that could be run.
Monocle using heuristics to try to identify the experiments with the highest likelihood of finding a vulnerability.
Each dependency is assigned a criticality score which is a product of the dependency priority (Hystrix commands get priority over RPC clients), how frequently the dependency is triggered compared to all other dependencies in the cluster, the retry factor, and the number of dependent clients.
The criticality score is combined with a safety score and experiment weight (failure experiments, then latency, than failure inducing latency) to produce the final prioritization score. The prioritized list is filtered to remove unsafe experiments, experiments that are already running, experiments in a failed state (previously failed, and not yet inspected by a user), and experiments that have run recently. After that Monocle gets to work and starts running the remaining experiments in priority order.
It would be great to have more detail on the quantitative or qualitative improvements to resiliency at Netflix that Monocle and chaos engineering have made, but for the moment it seems we will have to suffice ourselves with this single sentence:
To date, experiments generated by Monocle have revealed several cases where timeouts were set incorrectly and fallbacks revealed the service to be more business critical than the owner had intended.
When an automated experiment reveals a potential vulnerability, a member of the Resilience Engineering team spends time manually analysing the results of the experiment before flagging them to the owner. This reduces the false positive rate and helps build trust in the system, but also sounds like the current bottleneck in the process (“this was generally a time-consuming and tedious process“).
On error rates
If you’ve read the SRE book you’ve probably come across the “four golden signals” (p60): latency, throughput, error rate, and saturation. So it’s interesting to read here that…
Although intuitively error rates seem like a reliable signal for identifying problems with the system, we found them to have some undesirable properties for use as an experimental measure.
The issue seems to stem from the fact that a single device may error over and over again, bumping up the error count, and hence ultimately the error rate. So if an error-prone device happens to be assigned to a canary cluster it can generate a spurious error signal from the perspective of the experiment. Due to this the threshold for the automatic stop safety mechanism had be substantially increased. (Tracking error rates per device might help with this??).
There are many types of controlled experiment
While the original goal for ChAP was to run fault injection experiments, we have discovered that the platform itself can be used for other types of experiments. We are currently extending ChAP to support load testing experiments, similar in spirit to RedLiner. In addition, some self-serve users have begun experimenting with using ChAP for canary deployments because of the additional analysis that ChAP provides.
As a follow-up to this paper you might also enjoy Nora Jones’ article on ‘Chaos Engineering Traps.’

{kind=link}
2 thoughts on “Automating chaos experiments in production”
Comments are closed.