Fail-slow at scale: evidence of hardware performance faults in large production systems Gunawi et al., FAST’18
The first thing that strikes you about this paper is the long list of authors from multiple different establishments. That’s because it’s actually a study of 101 different fail-slow hardware incidents collected across large-scale cluster deployments in 12 different institutions.
Last year we looked at ‘Gray failure: the Achilles’ heel of cloud-scale systems,’ in which partial failures and system components running in degraded mode were revealed to be involved in many production incidents, and difficult to detect and diagnose with today’s systems. In ‘Fail-slow at scale’ we have a catalog of ways in which hardware has been shown to run in degraded mode, causing all sorts of problems. Fail-slow hardware, like file system faults and network partitions, should be added to the list of things that occur much more frequently than we’d like to think, and cause a lot of damage when they do occur.
This paper highlights an under-studied “new” failure type: fail-slow hardware, hardware that is still running and functional but in a degraded mode, slower than its expected performance. We found that all major hardware components can exhibit fail-slow faults.
These faults may be comparatively rare, but they can trigger chains of cascading events, resulting visible failures some distance from the original cause. Perhaps because of this, and because the partial failures are often deliberately masked in the hardware without enough metrics to surface them, troubleshooting fail-slow hardware based incidents can be very time-consuming:
The fail-slow hardware incidents in our report took hours or even months to detect (pinpoint). More specifically, 1% of the cases are detected in minutes, 13% in hours, 13% in days, 11% in weeks, and 17% in months (and unknown time in 45%).
One of the conclusions is that many modern deployed systems do not anticipate this failure mode. The authors offer a set of suggestions to hardware vendors, operators, and systems designers to improve the state of affairs.
Guidelines for vendors
- Instead of implicitly masking errors whenever possible, consider throwing explicit error signals when error rates far exceed the expected rate.
- Expose device-level performance statistics at fine enough granularity to be able to pinpoint device degradation. (The information from S.M.A.R.T. was deemed insufficient to act upon).
Guidelines for operators
- Enable online (in-situ) diagnosis, since many problems cannot be reproduced offline (back in the office).
- Monitor all hardware components.
- Capture full-stack performance data and use statistical approaches to pinpoint and isolate root causes.
Guidelines for system designers
- Make implicit error masking explicit (this is the software equivalent of the advice given above to hardware vendors). “Software systems should not just silently work around fail-slow hardware, but need to expose enough information to help troubleshooting.”
- Consider converting fail-slow faults to fail-stop. One example given is skipping a caching layer altogether when SSDs are misbehaving. Another example is to fail-stop after sufficient recurrence of fail-slow incidents (e.g., tripping a circuit breaker after too many retries). Doing this requires an ability to shut-off devices at a fine-grained level.
- Use fault-injection to explore fail-slow scenarios:
… we strongly believe that injecting root causes reported in this paper will reveal many flaws in existing systems. Furthermore, all forms of fail-slow hardware such as slow NIC’s, switches, disks, SSD, NVDIMM, and CPUs need to be exercised as they lead to differrent symptoms. The challenge is then to build future systems that enable various fail-slow behaviors to be injected easily.
Let’s now take a look at some of the characteristics and causes of fail-slow incidents.
Root causes
There can be a variety of root causes — these can be internal to the hardware component (for example, device wear or firmware issues), or external (for example, configuration, environment, temperature or power issues).
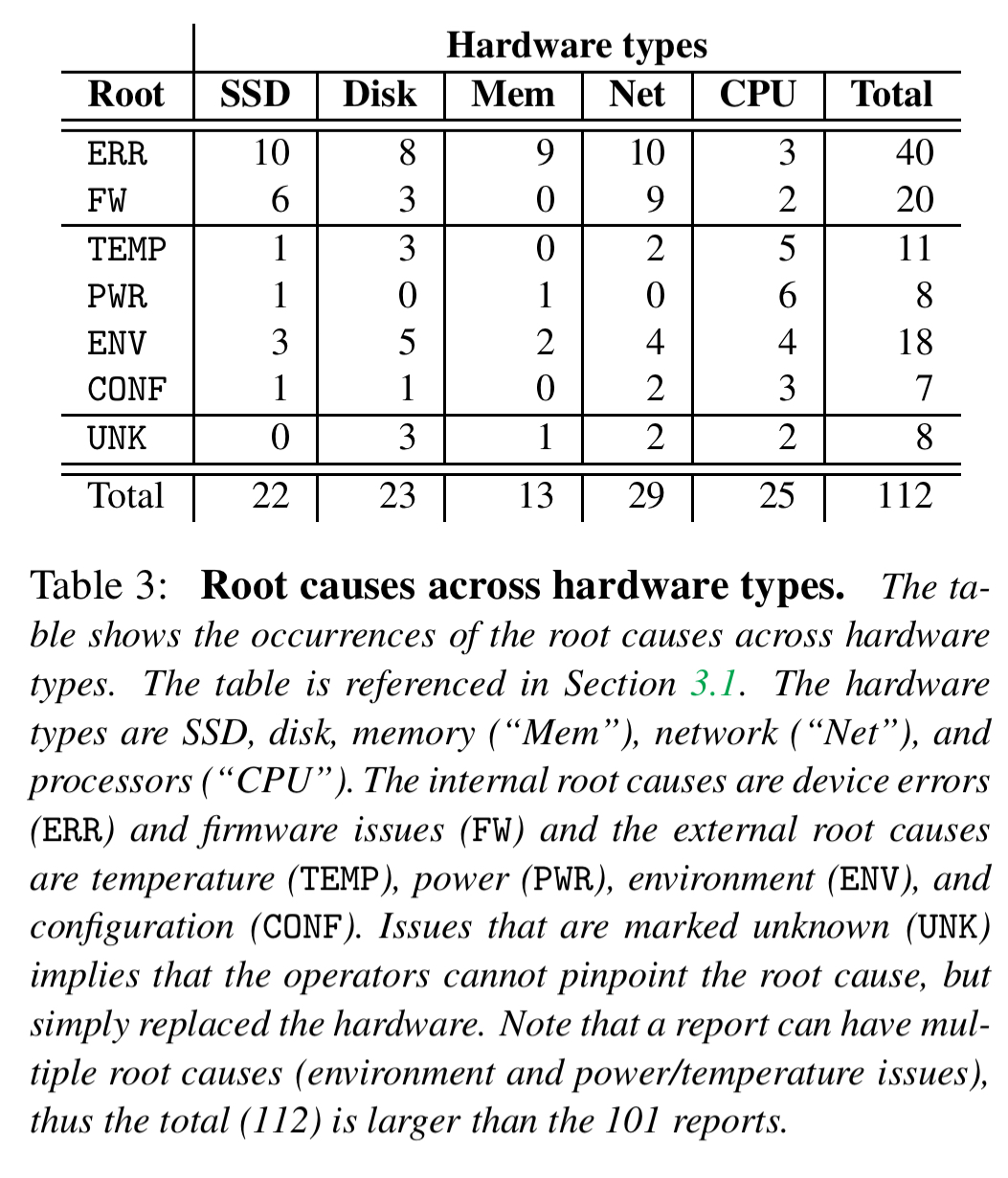
Section 4 in the paper describes the myriad ways that SSDs, Disks, Memory, and Network components can suffer from internal failures. And even when a component would otherwise function just fine, section 5 catalogues a long list of external factors that have been known to cause partial failures:
- Temperature: clogged air filters, cold-air-under-floor systems, broken fans, buggy fan firmware, poor assembly/design such that heat-sinks are ineffective. For example, “there was a case where a fan in a compute node stopped working, and to compensate this failing fan, fans in other compute nods started to operate at their maximal speed, which then generated heavy noise and vibration that degraded the disk performance.”
- Power: reduced power can easily trigger fail-slow hardware faults. Causes include insufficient capacitors, PCU firmware bugs, fail-partial power supplies, power hungry neighbours (drawing too much power under periods of heavy load), and faulty motherboard sensors.
- Enviroment: altitude (failure to provide enough cooling for high altitude), cosmic events, loose interconnects, vibrations (e.g. from fans).
- Configuration errors due to buggy BIOS firmware and simple human mistakes (e.g., in mapping PCIe cards to slots).
Fault conversion
Fail-stops in some components can cause others to exhibit fail-slow behaviour:
For example, a dead power supply throttled the CPUs by 50% as the backup supply did not deliver enough power; a single bad disk exhausted the entire RAID card’s performance; and a vendor’s buggy firmware made a batch of SSDs stop for seconds, disabling the flash cache layer and making the entire storage stack slow.
Likewise frequent transient failures can result in fail-slow behaviour due to the overheads of error masking (retries, repairs, etc..). When errors ceases to be rare, the masking overhead becomes the normal case performance.
Partial internal failures whereby only some part of the device is unusable can also lead to fail-slow behaviour.
Symptoms
Fail-slow conditions can manifest in several different ways.
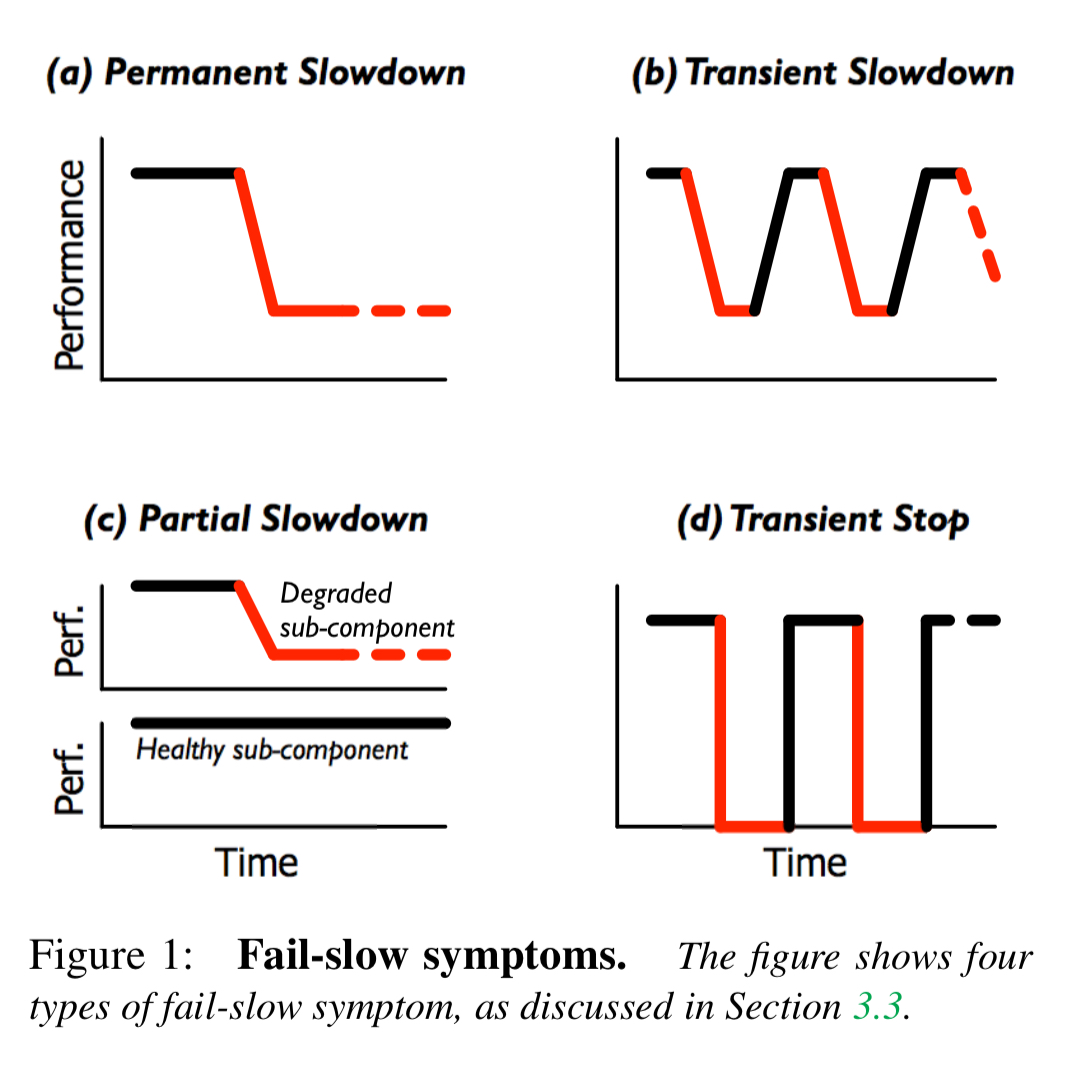
The slowdown may be permanent, or the device may fluctuate between normal and degraded performance. Some parts of the device may continue to offer full performance while others are degraded, and in other situations a device may periodically reboot itself, leading to periods of complete unavailability.
Cascading failures
…between the actual root cause and the hardware’s fail-slow symptom, there is a chain of cascading root causes… the fail-slow symptom then creates cascading impacts to the high-level software stack, and potentially to the entire cluster.
We’ve already seen the example of the failing fan leading to a cascade of events ending in degraded disk performance. Another example is a faulty sensor in a motherboard reporting a false value to the OS, thus making the CPUs run slower in energy saving mode. Fail-slow hardware problems can cascade into the software stack – for example, in an HBase deployment a memory card at 25% of normal speed caused backlogs, out-of-memory errors, and crashes.
The last word
The paper is packed with anecdotes that I didn’t have space to cover here. It’s well worth a read to get a finer appreciation of the kinds of hazards that await when building and operating systems at scale.
We believe fail-slow hardware is a fundamentally harder problem to solve [than fail-stop]. It is very hard to distinguish such cases from ones that are caused by software performance issues. It is also evident that many modern, advanced deployed systems do not anticipate this failure mode. We hope that our study can influence vendors, operators, and system-designers to treat fail-slow hardware as a separate class of failures and start addressing them more robustly in future system.

6 thoughts on “Fail-slow at scale: evidence of hardware performance faults in large production systems”
Comments are closed.