Protocol aware recovery for consensus based storage Alagappan et al., FAST’18
Following on from their excellent previous work on ‘All file systems are not created equal’ (well worth a read if you haven’t encountered it yet), in this paper the authors look at how well some of our most reliable protocols — those used in replicated state machines (RSM) — handle storage faults and corruptions. The report is not good:
Our analyses show that most approaches employed by currently deployed systems do not use any protocol-level knowledge to perform recovery, leading to disastrous outcomes such as data loss and unavailability.
Aren’t these protocols (such as Raft and Paxos) explicitly designed to ensure agreement and tolerate failed nodes? The gold standard that you reach for when dealing with the most critical data that needs strong durability and consistency guarantees? Yes they are, but you always have to pay attention to the failure model the system is designed for. Storage faults and data corruptions weren’t part of that failure model. Somebody forgot to tell that to the real world.
Having demonstrated the problem, the authors go on to design a new protocol-aware recovery approach.
To correctly recover corrupted data from redundant copies in a distributed system, we propose that a recovery approach should be protocol aware. A protocol-aware recovery (PAR) approach is carefully designed based on how the distributed system performs updates to replicated data, elects the leader etc..
Failure to be protocol-aware might lead, for example, to a node attempting to fix its data from a stale node, potentially leading to data loss. The solution is CTRL, corruption-tolerant replication. It comprises a local storage layer that can reliable detect faults, and a distributed protocol to recover from them using redundant copies. The authors won a best paper award at FAST’18 for their work.
What could possibly go wrong?
Inside a storage device, faults manifest as either block errors or corruptions. Block errors arise when the device internally detects a problem with a block and throws and error upon access. Corruption can occur due to lost and/or misdirected writes and may not be detected by the device. Some file systems (e.g. btrfs) can detect corruption and return an error to applications. (See also ccfs ). Others, such as ext4, simply silently return corrupted data if the underlying block is corrupted.
In either case, storage systems build atop local file systems should handle corrupted data and storage errors to preserve end-to-end data integrity.
Keeping redundant copies on each node is wasteful in the context of distributed systems where the data is inherently replicated.
Within a replicated state machine system, there are three critical persistent data structures: the log, the snapshots, and the metainfo. The log maintains the history of commands, snapshots are used to allow garbage collection of the log and prevent it from growing indefinitely, and the metainfo contains critical metadata such as the log start index. Any of these could be corrupted due to storage faults. None of the current approaches analysed by the authors could correctly recover from such faults.
The authors conducted both a theoretical and practical (fault-injection) analysis of real world systems including ZooKeeper, LogCabin, etcd, and a Paxos-based system, resulting in a taxonomy of current approaches.
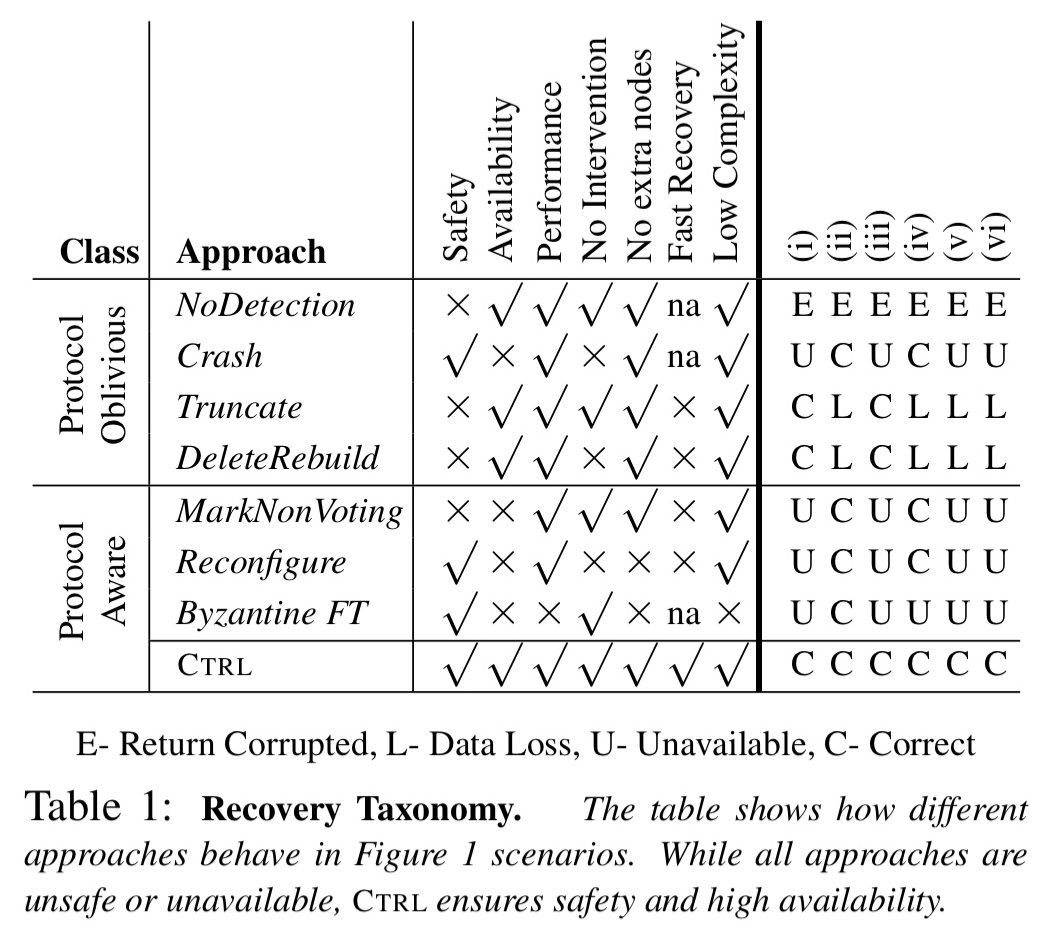
The first group of responses are protocol oblivious, of which the most trivial is no have no detection strategy at all and just trust the underlying file system. Slightly better is to use checksums to detect corruptions and crash the node on detecting an error. (LogCabin, ZooKeeper, etcd all crash sometimes when their logs are faulty, ZooKeeper also crashes on corrupt snapshots). Crashing harms availability, so another strategy is to truncate the log at the point of detection of faulty data. Unfortunately this can also lead to silent data loss if the recovering node form a majority with other nodes that are lagging (demonstrated in ZooKeeper and LogCabin). A more severe form of truncate is to delete and rebuild all data. This can also lead to data loss in a similar way.
Surprisingly, administrators often use this approach hoping that the faulty node will be “simply fixed” by fetching the data from other nodes.
Some protocol aware strategies include mark non-voting as used by a Paxos-based system at Google (a faulty node deletes all data on fault detection, and marks itself as a non-voting member). This can lead to safety violations when a corrupted node deletes promises given to leaders. Reconfiguring involves removing the faulty node and adding a new one but again can harm availability if a majority are alive but one node’s data is corrupted. BFT should theoretically tolerate storage faults, but is expensive.
In short, when we consider the simple set of sample scenarios shows below, it turns out that none of the existing approaches exhibit correct behaviour in all of them.
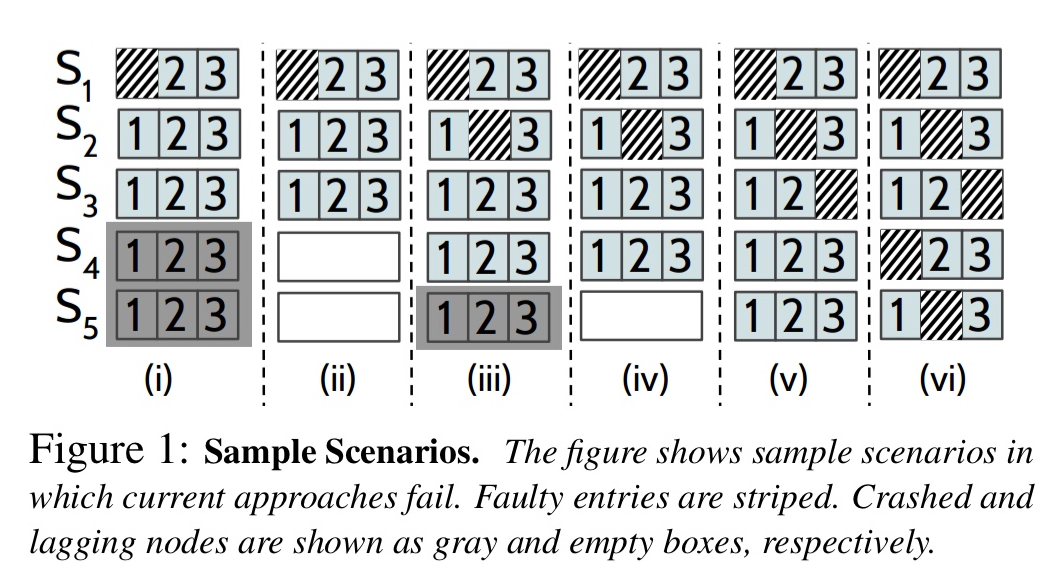
Only CTRL is able to ensure safety and high availability under all six of these scenarios:
Corruption-tolerant replication
CTRL extends the standard RSM fault model for crash tolerant systems with a storage fault model including faults both in user data and in file-system metadata blocks.
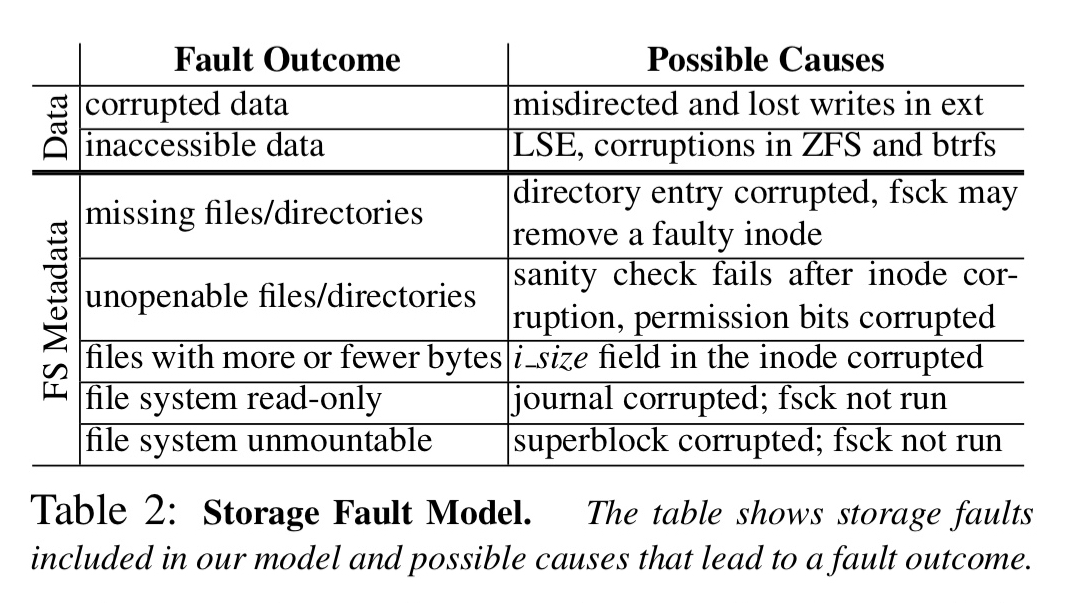
CTRL guarantees that if there exists at least one correct copy of a committed data item, it will be recovered or the system will wait for that item to be fixed; committed data will never be lost.
It’s the job of the local storage layer (CLStore) to reliably detect faulty data on a node. CLStore also needs to be able to distinguish between crashes and corruptions as otherwise safety may be violated.
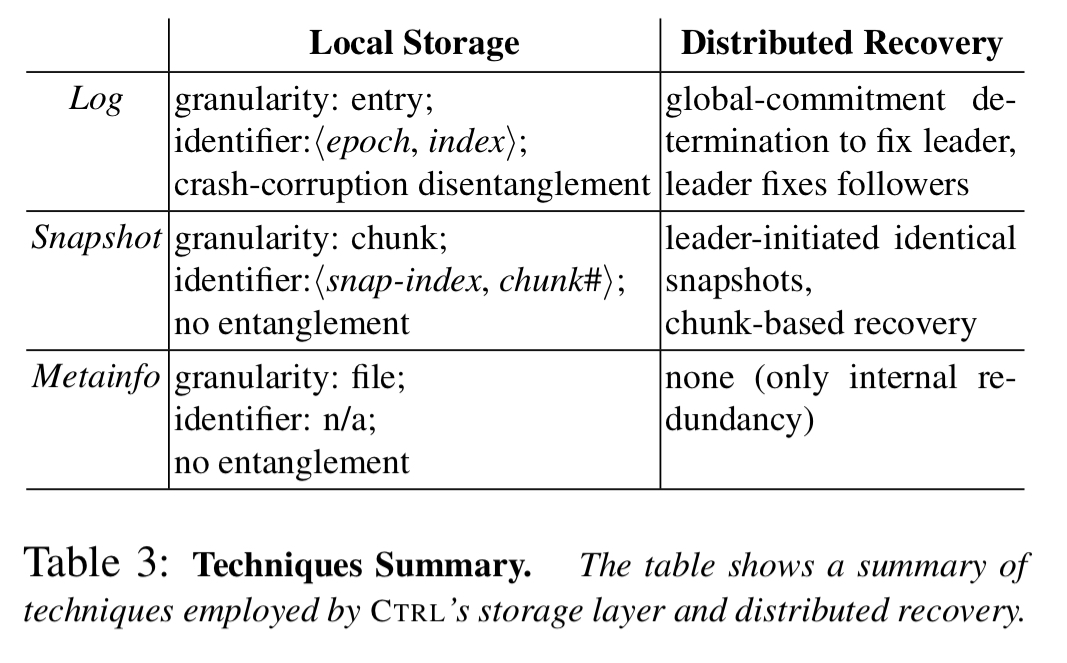
For logs, CLStore uses a modified log format which includes persistence records written in a different part of the media to the main entries. On a checksum mismatch, if a persistence record is not present, then we can conclude that the system crashed during an update. One special case is when the corrupted entry is the very last one in the log. In this case CLStore cannot disambiguate, and marks the record as corrupted leaving it to distributed recovery to fix or discard the entry based on global commitment.
For snapshots, CLStore splits them into chunks so that a faulty snapshot can be recovered at the granularity of individual chunks.
For metainfo (which is special in that it cannot be recovered from other nodes), CLStore simply maintains two local copies. Since metainfo is small and updated infrequently this does not incur significant overhead.
To ensure that a faulty item, once detected, can be reliably identified (what if the identifier in an entry is corrupt?) CLStore also redundantly stores the identifier of an item apart from the item itself. Faulty data items and their identifiers are passed to the distributed recovery layer for recovery using RSM-specific knowledge.
Since metainfo files are recovered locally, the distributed recovery layer is responsible for recovering log entries and snapshots.
Recovering log entries
If a leader has no faulty entries, then fixing a follower is straightforward – the leader can supply them to the follower. Things get more interesting when the leader itself discovers a fault. Now we could run a leader election with the constraint that a node cannot be elected leader if its log contains a faulty entry. However, in scenarios such as those shown in (b) below, this will lead to otherwise avoidable unavailability.

So we relax the constraint, and allow a node to be elected leader even if it has faulty entries. However, the leader must fix its faulty entries before accepting new commands.
The crucial part of the recovery to ensure safety is to fix the leader’s log using the redundant copies on the followers… However, in several scenarios, the leader cannot immediately recovery its faulty entries; for example, none of the reachable followers might have any knowledge of the entry to be recovered or the entry to be recovered might also be faulty on the followers.
Known uncommitted entries (determined for example by checking that a majority of followers do not have the entry) can be safely discarded. A known committed entry (because one of the followers has a commit record) can be recovered from the follower with the record. When commitment can’t be quickly determined (nodes down or slow), then the leader must wait for a response.
In the unfortunate and unlikely case where all copies of an entry are faulty, the system will remain unavailable.
Recovering snapshots
Current systems including ZooKeeper and LogCabin do not handle faulty snapshots correctly: they either crash or load corrupted snapshots obliviously. CTRL aims to recover faulty snapshots from redundant copies.
In current systems, every node runs the snapshot process independently, taking snapshots at different log indices. This makes recovery complex. CTRL ensures that nodes take snapshots at the same index — identical snapshots enable chunk-based recovery. The leader announces a snapshot index, and once a majority agree on it, all nodes independently take a snapshot at that index. Once the leader learns that a majority (including itself) of nodes have committed a snapshot at an index i, it garbage collects its log up to i, and instructs the followers to do the same.
A leader recovers its faulty chunks (if any) from followers, and then fixes faulty snapshots on followers.
Recovery technique summary
The following table summarise the techniques used by CTRL for storage fault recovery.
Evaluation
I’m running out of space for today’s post, so will have to give the briefest of treatments to the evaluation. If you’re in any doubt about the need for a system like CTRL though, it’s well worth digging into.
The following table shows the results for targeted corruption testing using LogCabin and ZooKeeper — both in their original form, and retrofitted with CTRL.
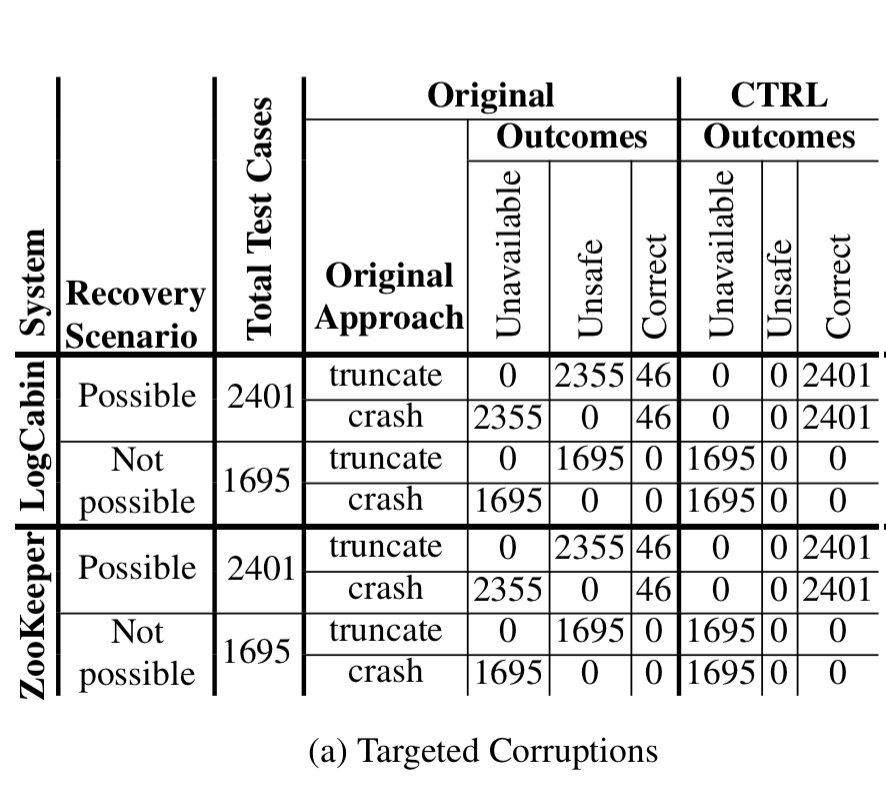
Whereas recovery is theoretically possible in 2401 cases, the original systems are either unsafe or unavailable in 2355 of these. CTRL correctly recovers in all 2401 cases.
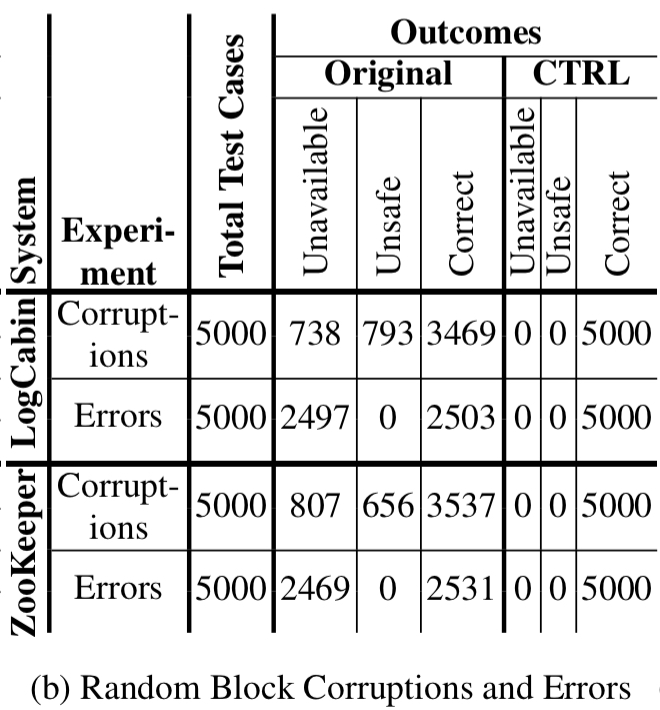
With block corruptions the original LogCabin and ZooKeeper are unsafe in about 30% of cases. With block errors, they are unavailable in about 50% of cases. CTRL correctly recovers in all cases:
With snapshot faults CTRL correctly recovers from all cases. Original ZooKeeper always crashes the node leading to unavailability and potential loss of safety. LogCabin is incorrect in about half of all cases.
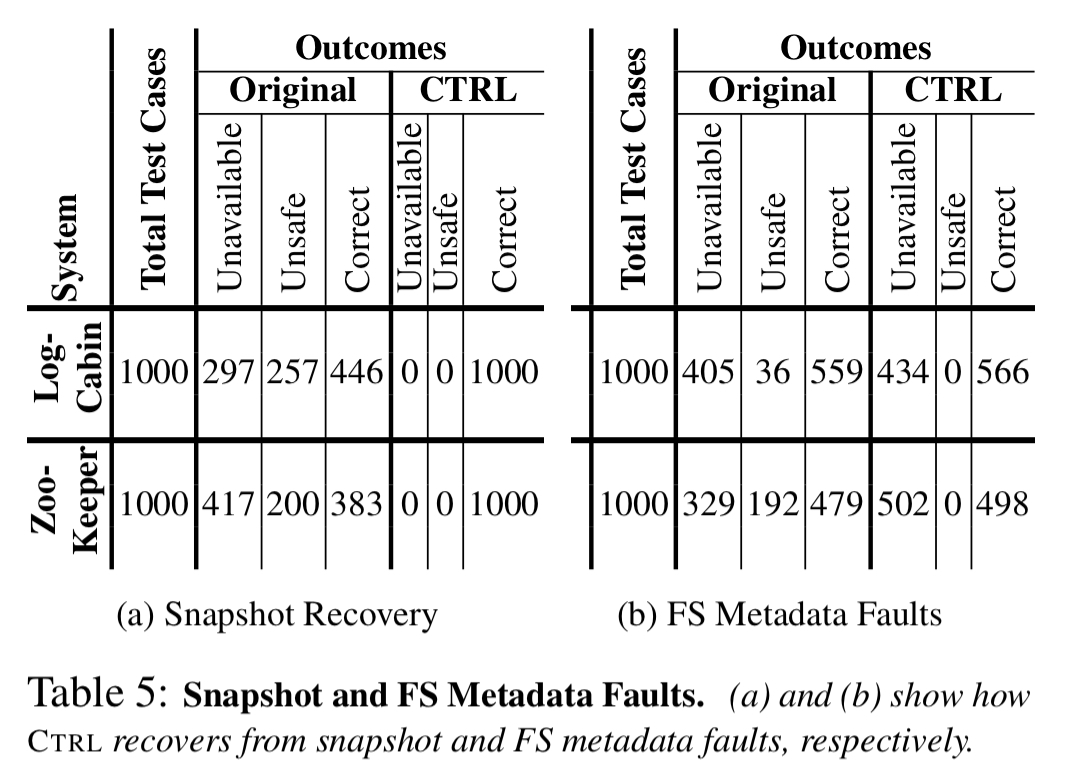
In the face of file system metadata faults (e.g., corrupt inodes and directory blocks) CTRL will reliable crash the node, preserving safety.
When using SSDs, the throughput overhead of CTRL is 4% in the worst case.
The last word
Our work is only a first step in hardening distributed systems to storage faults: while we have successfully applied the PAR approach to RSM systems, other classes of systems (e.g. primary-backup, Dynamo-style quorums) still remain to be analyzed. We believe the PAR approach can be applied to such classes as well. We hope our work will lead to more work on building reliable distributed storage systems that are robust to storage faults.

3 thoughts on “Protocol aware recovery for consensus-based storage”
Comments are closed.