Practical Byzantine Fault Tolerance – Castro & Liskov 1999
Oh Byzantine, you conflict me. On the one hand, we know that the old model of a security perimeter around an undefended centre is hopelessly broken (witness Google moves its Corporate Applications to the Internet)- so Byzantine models, which allow for any deviation from expected behaviour and can therefore also offer defences against malicious attackers with inside access sound like a good direction. On the other hand, the price to pay is steep, and it feels a bit like putting extra security on your front door while still leaving all your windows wide open. Once an adversary is on your network and has compromised hosts running one of your core distributed services, is subverting your coordination protocols really their next likely move? Or might such an adversary simply attempt a much more direct exfiltration and possible destruction of key data? If security is only as good as your weakest link, then the coordination protocols don’t feel like they would often be the weakest link to me. Still, work on Byzantine systems sheds useful light on what changes when you need to defend against adversaries in your own systems.
Today’s choice is optimistically entitled ‘Practical Byzantine Fault Tolerance’ – and indeed, the runtime overhead that Castro and Liskov are able to demonstrate (about 3% slower) is impressive. In many distributed systems papers you’ll find a discussion on ‘system model’ that begins with something like “We assume the standard non-Byzantine, fail-stop process model…” What are the assumptions for a Byzantine model?
We use a Byzantine failure model, i.e., faulty nodes may behave arbitrarily, subject only to the restriction mentioned below. We assume independent node failures. For this assumption to be true in the presence of malicious attacks, some steps need to be taken, e.g., each node should run different implementations of the service code and operating system and should have a different root password and a different administrator. It is possible to obtain different implementations from the same code base and for low degrees of replication one can buy operating systems from different vendors. N-version programming, i.e., different teams of programmers produce different implementations, is another option for some services.
Which, let’s be honest, doesn’t sound very practical at all! It’s hard enough getting one implementation on one OS to be bug free, stable, and have good performance. The algorithm itself though, we could consider practical…
This paper presents a new, practical algorithm for state machine replication that tolerates Byzantine faults. The algorithm offers both liveness and safety provided at most (n-1)/3 out of a total of n replicas are simultaneously faulty. This means that clients eventually receive replies to their requests and those replies are correct according to linearizability. The algorithm works in asynchronous systems like the Internet and it incorporates important optimizations that enable it to perform efficiently.
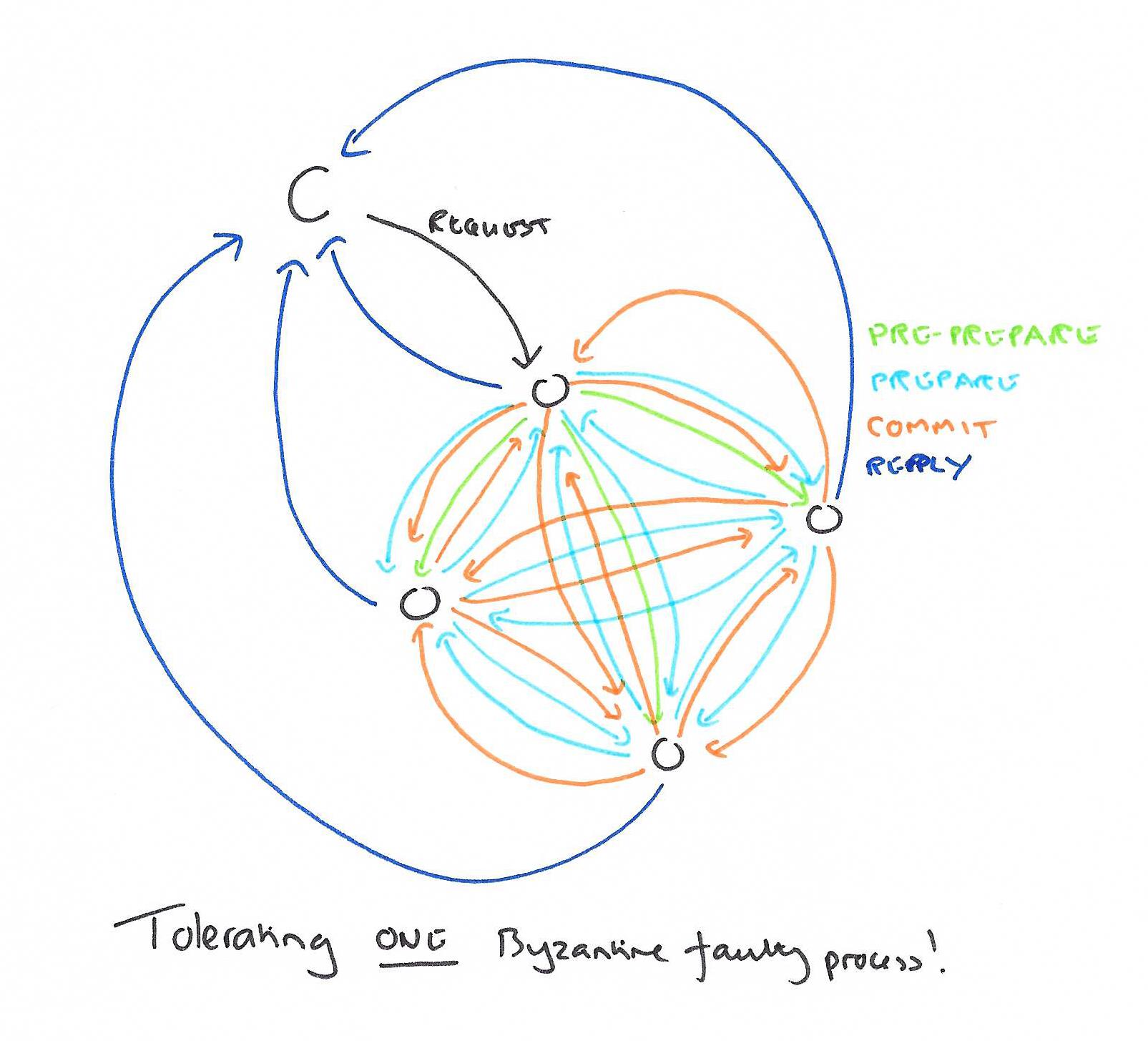
The first thing we’re going to need is more replicas. Non-Byzantine consensus models work around a majority of processes agreeing on a decision – to cope with f failures, you need 2f+1 processes. With the Byzantine model, we don’t just have failed processes to contend with though, we might have actively participating processess that are deliberately trying to mislead us! To cope with this, you need 3f+1 processes in order to tolerate f faulty processes. We’re also going to need agreement between at least f+1 processes at every step (since this guarantees at least one correct process contributed). Some steps need 2f+1. The basic algorithm is inspired by Viewstamped Replication and proceeds in four stages:
- A client sends a request to invoke a service operation to the primary
- The primary multicasts the operation to the backups
- Replicas execute the request and reply to the client
- The client waits for f+1 replies from different replicas with the same result, this is the result of the operation.
If the client does not receive replies soon enough, it broadcasts the request to all replicas. If the request has already been processed, the replicas simply re-send the reply; replicas remember the last reply message they sent to each client. Otherwise, if the replica is not the primary, it relays the request to the primary. If the primary does not multicast the request to the group, it will eventually be suspected to be faulty by enough replicas to cause a view change.
Message digests and signatures are used for all exchanges.
In the normal case, the primary runs a three-phase protocol to coordinate with the replicas.
The three phases are pre-prepare, prepare, and commit. The pre-prepare and prepare phases are used to totally order requests sent in the same view even when the primary, which proposes the ordering of requests, is faulty. The prepare and commit phases are used to ensure that requests that commit are totally ordered across views.
A backup accepts a pre-prepare message if the digest and signature are correct, it is for the correct view, and it hasn’t already accepted a pre-prepare message for the current view and sequence number with a different digest. It then enters a prepare phase by multicasting a prepare message to all other replicas. Once the replica has received 2f prepares from different backups that match the pre-prepare, it considers itself prepared and multicasts a commit message. Once a replica has received 2f+1 commit messages (including its own) that match the pre-prepare it consider the request locally committed and executes the operation. After executing the operation, the reply is sent to the client.
My intent here is just to give you a flavour of what’s involved. See the full paper for a discussion of why this general scheme achieves the desired safety and liveness goals, several additional details which I skipped over, and some optimisations which can help to reduce the communication overhead.
In their conclusion, Castro & Liskov offer us an additional reason to consider Byzantine fault tolerance beyond defence against deliberate attacks:
One reason why Byzantine-fault-tolerant algorithms will be important in the future is that they can allow systems to continue to work correctly even when there are software errors. Not all errors are survivable; our approach cannot mask a software error that occurs at all replicas. However, it can mask errors that occur independently at different replicas, including non-deterministic software errors, which are the most problematic and persistent errors since they are the hardest to detect. In fact, we encountered such a software bug while running our system, and our algorithm was able to continue running correctly in spite of it.

I believe this paper is the inspiration for the Tendermint cryptocurrency protocol. Tendermint is considered by many to be the best proof of stake alternative to the traditional proof of work consensus used by Bitcoin.
Actually, Tendermint was originally inspired by the DLS (1988) protocol for consensus under partial synchrony, but evolved to resemble PBFT much more closely. The main distinction is that Tendermint combines the “checkpoint” and “commit” steps from PBFT into a single “commit block” step, reducing the complexity of the protocol and allowing faster recovery from leader failure. The hash-linked list of blocks makes it a blockchain. Indeed, it is still arguably the best proof-of-stake alternative, but it is also arguably the best implementation of BFT on the market today!