Hybrids on Steroids: SGX-based high performance BFT Behl et al., EuroSys’17
Byzantine fault tolerance (BFT) is the kind of fault-tolerance designed to withstand not just process crashes and network problems, but also active adversaries trying to break the system, as well as storage and memory corruptions and so on. We’ve taken a look at BFT on The Morning Paper before, in the form of Practical Byzantine Fault Tolerance, and the more recent XFT: Practical fault-tolerance beyond crashes (which might just as easily have been titled ‘Pragmatic Byzantine Fault Tolerance’). Today’s paper describes a system called Hybster, which advances the state-of-the-art in a line of systems known as hybrid BFT systems. They are termed hybrid because they rely on a small core of trusted subsystems, which can only fail by crashing (i.e., the traditional fault model), whereas outside of this trust base the full BFT model is assumed. The advantage of the hybrid model is that you can reduce the number of replicas that participate in the ordering of client requests from 

Depending on the particular approach, a trusted subsystem may include an entire virtualization layer, a multicast ordering service executed on a hardened Linux kernel, a centralized configuration service, or a trusted log, or may be as small as a trusted platform module, a smart card, or an FPGA.
(See section 7 in the paper for a multitude of references for the above).
Hybster is unique in using Intel SGX for its trust model. Another unique element of Hybster is its use of a parallelizable replication protocol, whereas all prior hybrid systems have required some kind of sequential processing.
Hybster is relaxed with regard to faulty replicas while remaining safe; it is parallelizable by embracing the consensus-oriented parallelization scheme and marrying it with trusted execution environments; it is formal, it is backed by a comprehensive specification that facilitates reasoning about it; and Hybster is simply fast, it achieves over 1 million operations per second in a setup with only four cores, excelling other published systems by more than an order of magnitude.
There’s an awful lot in this paper – EuroSys papers are long to start with (on the order of 15-16 pages), and in this case almost every single paragraph requires close reading. I’ll do my best to give you the overall sense but of necessity there’s a lot of detail I will need to leave out, so if this topic interests you, it’s definitely worth going on to study the original paper.
Three protocols and an ordering problem
A hybrid BFT based on state-machine replication looks a bit like this:
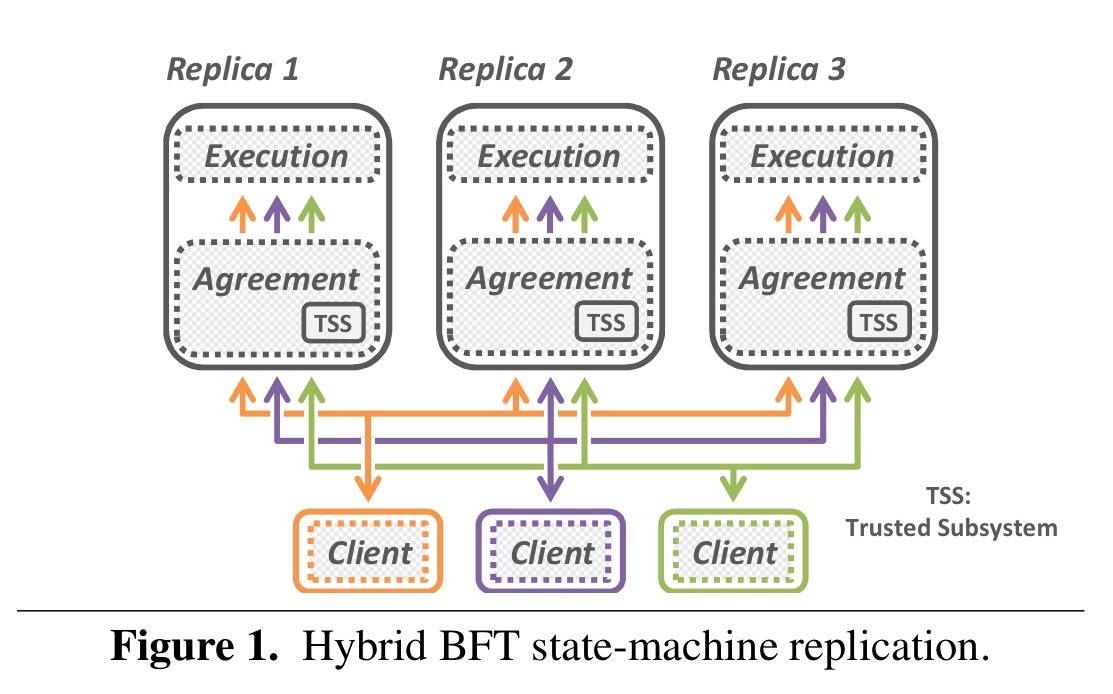
Each replica contains a trusted subsystem (TSS) which is kept small to minimise the TCB. Clients send requests to a replica group, and accept a reply once they have received 
- An ordering protocol establishes a global order for requests/commands. It assigns a unique number to each request and ensures sufficient correct replicas reach consensus on it.
- A checkpointing protocol periodically creates consistent snapshots of replica states and uses them to compile a proof of progress. (Without this, the system can never garbage collect).
- A view-change protocol ensures that the system makes progress despite faulty replicas. It enables a replica group to safely switch between configurations (views) even if up to
of the group members are arbitrarily faulty.
All known (by the authors) ordering protocols rely on sequential processing.
Not being able to parallelize the agreement, however, fundamentally restricts the performance of such systems on modern platforms. Unfortunately, sequential processing seems to be inherent to the hybrid fault model itself: from an abstract perspective, all hybrid systems prevent undetected equivocation by cryptographically binding sensitive outgoing messages to a unique monotonically increasing timestamp by means of the trusted subsystem.
(Equivocation here is used to mean a deliberately misleading message sent by a participant).
In Hybster each replica is given multiple TSS instances, which means we can support n virtual timelines per replica instead of just one.
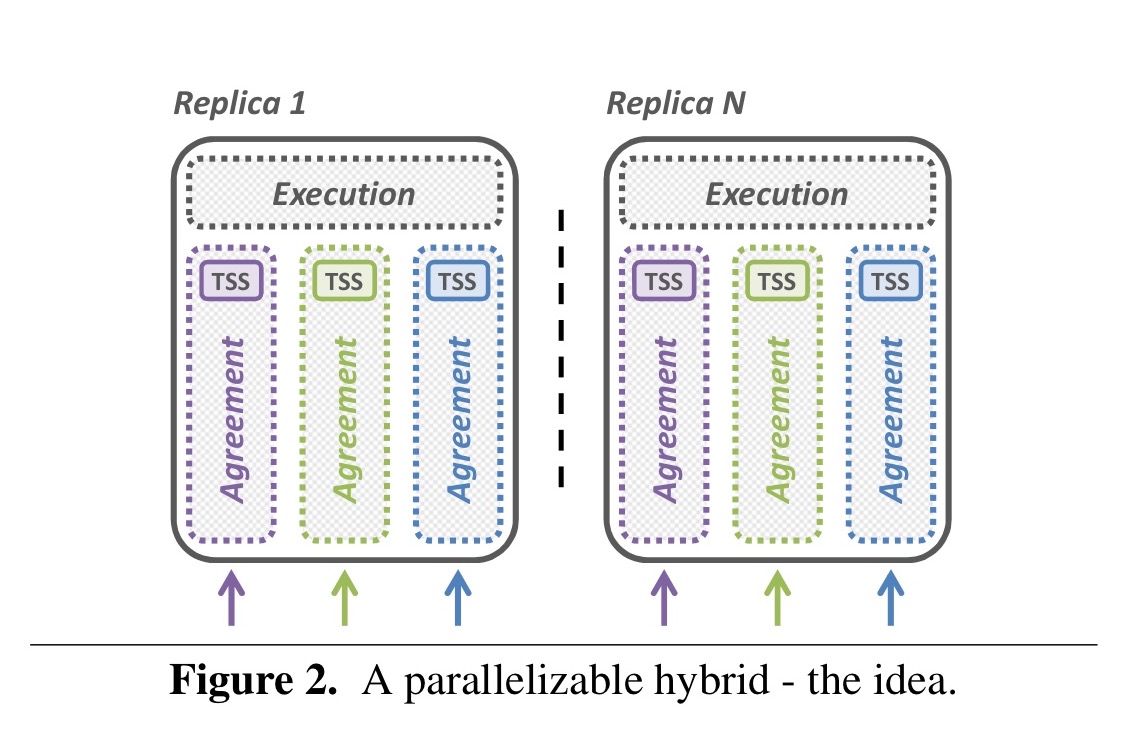
Instead of a single virtual timeline, each replica use multiple independent timelines; instead of a single trusted subsystem, each replica is equipped with as many subsystems as the targeted degree of parallelism requires. This is perfectly backed by the concept of consensus-oriented parallelization where equal processing units are responsible for a statically assigned subset of consensus instances, thereby preventing the opportunity for equivocation.
If you’re going to have multiple TSS instances per replica, then you need a TSS mechanism which easily supports that. The state-of-the-art FPGA-based CASH system would require adding as many extension cards as there are processor cores, which quickly becomes impractical. But if the trusted execution environment is created using Intel’s SGX, then it becomes perfectly feasible!
Design trade-offs
Section 4 of the paper contains a detailed analysis of the design decisions and trade-offs made by two existing hybrid-BFT systems: A2M-PBFT and MinBFT. It examines four key areas:
- The abstraction used for the trusted subystem. The preferred proposal here comes from a system called TrInc, which provides for a set of increasing counters and binds unique counter values to message digests by calculating a certificate over value and digest.
- How the system copes with equivocation (detection vs prevention). The preferred proposal here comes from A2M-PBFT which used predefined log slots for each protocol instance, making it impossible to generate two conflicting messages for the same protocol instance.
- How many phases to use in the ordering protocol. Two-phase ordering as used by MinBFT gives superior performance (to three-phase alternatives). However, it requires additional efforts to safely determine the system state in the case of errors.
- How to manage histories during view changes:
One of the main responsibilities of the view-change protocol is to ensure that all commands executed by some correct replicas in some view will be eventually executed by all correct replicas in this or any later view.
Histories are used to confirm both what did happen, and crucially what did not happen. The downside of histories is that they lead to an unknown upper bound on the memory demand of existing protocols.
Hybster
Following the analysis of existing systems, we propose a hybrid replication protocol that is designed around a two-phase ordering and a concept that prevents equivocation by means of multiple instances of a TrInc-based trusted subsystem realized using Intel SGX. (Emphasis mine).
Hybster’s design also allows faulty replicas to conceal their own messages so long as these are not critical to ensuring safety. Through this mechanism the complexity of the view-change protocol is reduced and we don’t need histories. As we saw previously, Hybster allows support performing multiple consensus instances in parallel. Hybster’s protocols are formally specified in a separate technical report. The informal description is contained in section 5 of the paper. Imagine a traditional replication protocol, but with lots of certifications added.
 (Click to enlarge)
(Click to enlarge)
To really study the protocols you need all of the detail contained within the paper (or a very much longer The Morning Paper post!), and I’m going to defer to the description in the paper for this reason.
The parallelized version of Hybster is described as an extension to the basic protocol.
Based on a consensus-oriented parallelization scheme, replicas are composed of equal processing units, called pillars, that do not share state, communicate via asynchronous in-memory message passing only, and operate mostly independently from each other. Concerning the ordering of requests, the latter is achieved by partitioning the space of order numbers; each pillar is responsible for executing the consensus instances for a predefined share of order numbers given by some calculation formula.
Hybster equips each pillar with its own instance of the trusted subsystem. Checkpointing is a shared responsibility amongst the pillars, and view-change messages are broken down by pillar (one partial message for each pillar).
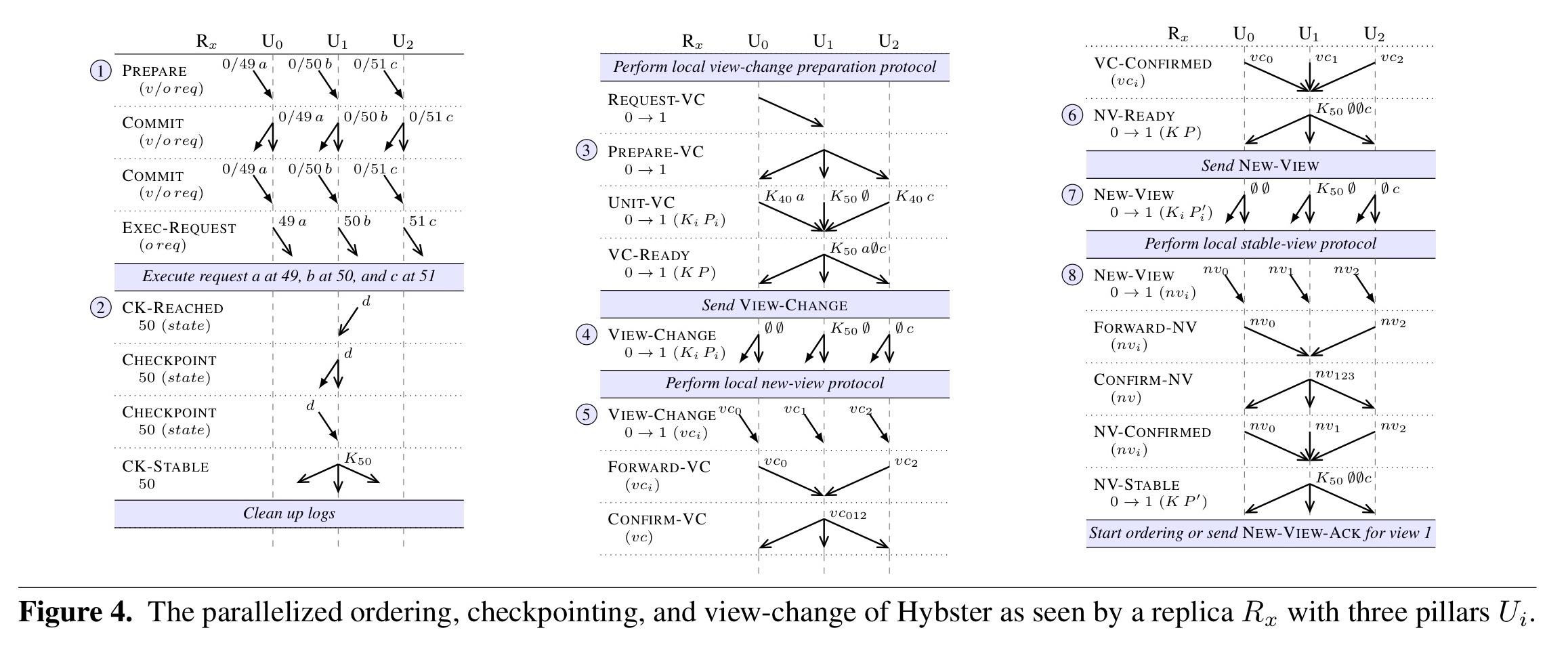 (Click to enlarge)
(Click to enlarge)
Evaluation
Hybster is prototyped mostly in Java, with the trusted subsystem based on Intel SGX written in C/C++ and JNI used to communicate between them. The evaluation compares two different variants of Hybster: HybsterS uses just a single instance of the TSS (called TrInX) and effectively measure the sequential basic protocol of Hybster. HybsterX uses the parallel version with one instance of TrInX per processor core. In addition, we get a comparision with PBFT (Practical Byzantine Fault Tolerance) implemented following the consensus-oriented parallelizaton scheme on the same code base (PBFTcop), as well as a version of this which uses the TrInIX TSS (HybridPBFT).
The key results are contained in the following three charts:
 (Click to enlarge)
(Click to enlarge)
(a) shows average response times with zero-byte payloads, and (b) shows 1KB requests as well as replies. HybsterX saturates at 900,000 operations/second bottlenecking on the CPU without payloads. We see a similar shape but lower throughput (bottlenecking on the network) with the 1KB payloads.
Graph (c) above shows a ZooKeeper-inspired coordination service.
HybsterX attains a 10 to 20% higher throughput than the hybrid PBFT configuration and 30 to 40% compared to the original PBFT protocol realized with a consensus-oriented parallelization scheme. Again, compared to its own sequential basic protocol, it is able to exhibit a speed-up of 2.5 to 3.0 and is only confined by the few number of cores provided by the test machines.

One thought on “Hybrids on Steroids: SGX-based high-performance BFT”
Comments are closed.