Barrier-enabled IO stack for flash storage Won et al., FAST’18
The performance of Flash storage has benefited greatly from concurrency and parallelism – for example, multi-channel controllers, large caches, and deep command queues. At the same time, the time to program an individual Flash cell has stayed fairly static (and even become slightly worse in some cases). That’s ok until an application needs to guarantee ordering and/or durability of writes.
Enforcing a storage order is achieved by an extremely expensive approach: dispatching the following request only after the block associated with preceding request has been completely transferred to the storage device and made durable. We call this mechanism Transfer-and-Flush.
With transfer-and-flush, the parallelism and concurrency benefits are lost. As a consequence, on a single channel mobile storage SSD for smartphones, ordered writes offer only 20% of the performance (IOPS) of unordered writes. For a 32-channel Flash array, this ratio decreases to just 1%.
In today’s paper (which also won a best-paper award at FAST’18), the authors introduce a Barrier-enabled IO stack, which can enforce storage order between requests without the filesystem having to wait for a full transfer-and-flush. The headline performance gains certainly make you sit up and take notice:
SQLite performance increases by 270% and 75%, in server and in smartphone, respectively. In server storage BarrierFS brings performance gains of 43x and 73x in MySQL and SQLite respectively when compared to EXT4.
There’s some important fine-print in the headline numbers – the biggest gains come when ordering is preserved, but we don’t wait for durability. The baseline being compared against offers both.
Getting your ducks in order
The modern IO stack is said to be orderless…
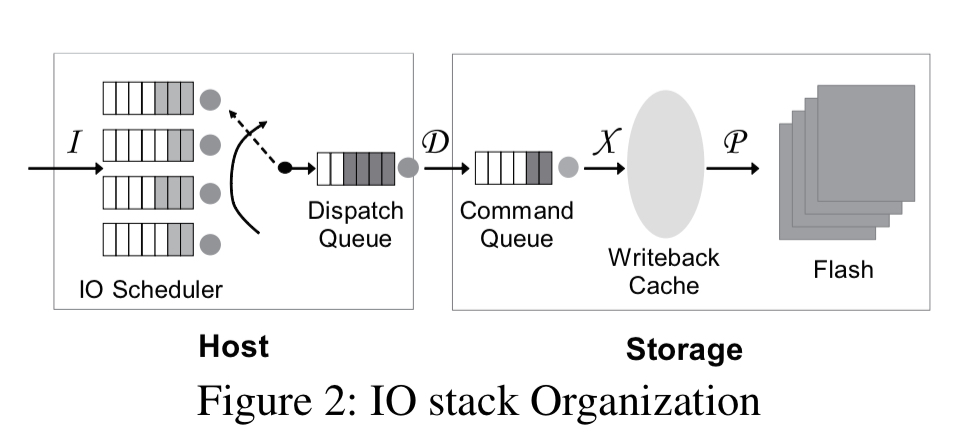
Consider a set of writes issued in some order (issue order) by a file system:
- The IO scheduler may reorder and coalesce IO requests according so some scheduling principle (e.g., CFQ), before placing them onto a dispatch queue to be dispatched to the storage device (dispatch order).
- The storage controller receives the incoming commands and places them in its command queue. It is free to schedule commands for transfer as it sees fit. Errors, time-outs, and retries further impact the eventual ordering (transfer completion order).
- The overall persistence order is governed not by the order in which data blocks are made durable, but by the order in which the associated mapping table entries are updated. The two may not coincide.
The long standing assumption (a holdover from the physical characteristics of rotating disks) is that the host cannot control the persistence order.
The constraint that the host cannot control the persist order is a fundamental limitation in modern IO stack design.
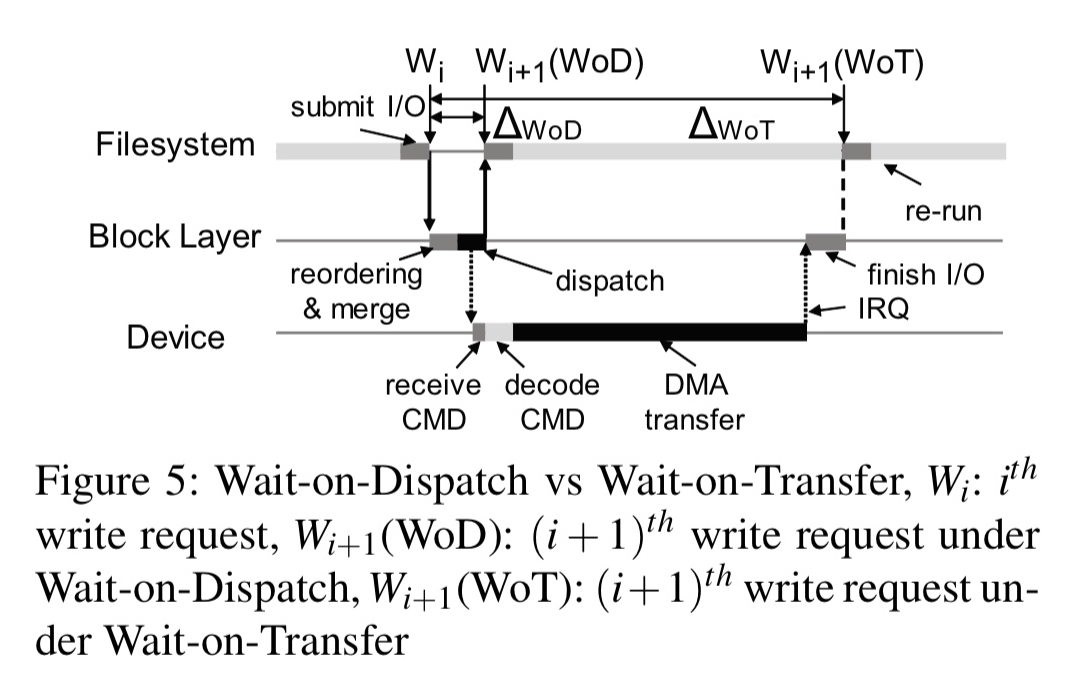
To guarantee ordering in the face of this, an expensive transfer-on-flush mechanism is used. If a needs to be ordered before b, then after dispatching a to the storage device, the caller needs to wait for a to be serviced (the DMA transfer to complete) — wait-on-transfer. Then the caller can issue a flush command and wait for its completion (wait-on-flush). Only once the flush has returned can the caller dispatch b.
When ext4 (in its default Ordered mode) commits a journal transaction it uses two write requests: one for writing a coalesced chunk of journal descriptor block and log blocks (JD), and one for writing the commit block (JC). JD needs to be made durable before JC. Across transactions, ext4 also has to ensure that transactions are made durable in order. If either of these two ordering constraints are violated, the file system may recover incorrectly in the case of an unexpected failure.
Order-preserving block devices with barriers
The ‘cache barrier,’ or ‘barrier’ for short, command is defined in the standard command set for mobile Flash storage. With the barrier command, the host can control the persist order without explicitly invoking cache flush. When the storage controller receives the barrier command, it guarantees that the data blocks transferred before the barrier command become durable after the ones that follow the barrier command do.
The authors implement the barrier command concept using a new attribute REQ_BARRIER that can be set on a regular request object (to avoid the overhead of dispatching a dedicated command). For crash recovery they use a simple LFS style scheme. The actual implementation of the barrier command is not the main focus of the paper, it’s how the barrier command is used and the benefits it brings that the authors focus on. (“Developing a barrier-enabled SSD controller is an engineering exercise…”).
With the barrier command in hand, it is possible to implement order-preserving dispatch:
Order-preserving dispatch is a fundamental innovation in this work. In order-preserving dispatch, the block device layer dispatches the following command immediately after it dispatches the preceding one and yet the host can ensure that that the two commands are serviced in order. We refer to this mechanism as wait-on-dispatch.
Wait-on-dispatch eliminates the wait-on-transfer overhead.
Using a barrier write request (i.e., a write request with both ORDERED and BARRIER attributes set), the existing command priority of the SCSI interface ensures that the barrier write is serviced only after the existing requests in the command queue are serviced and before any of the commands following the barrier write are serviced.
The ordered priority command has rarely been used in existing block device implementations. This is because when the host cannot control the persist order, enforcing a transfer order with an ordered priority command barely carries any meaning from the perspective of ensuring the storage order. With the emergence of the barrier write, the ordered priority plays an essential role in making the entire IO stack an order-preserving one.
Epoch-based scheduling (with epochs delineated by barrier writes) ensures that:
- the partial order between epochs is honoured
- within an epoch, requests can be freely scheduled
- orderless requests can be scheduled across epochs
Barrier-enabled filesystem (BFS)
The barrier-enabled IO stack adds two primitives, fbarrier() and fdatabarrier(), which synchronise the same set of blocks as fsync() and fdatasync() respectively, but return without ensuring the associated blocks become durable. I.e., they guarantee ordering but not durability. By interleaving write class with fdatabarrier an application can ensure that data blocks preceding the data barrier call are made durable ahead of data blocks that follow it. The authors modified ext4 to make it barrier enabled.
Exploiting the order-preserving nature of the underlying block device, we physically separate the control plane activity (dispatching the write requests) from the data plane activity (persisting the associated data blocks and journal transaction) of a journal commit operation. Further, we allocate separate threads to each task so that the two activities can proceed in parallel with minimum dependency. The two threads are known as the commit thread and the flush thread. We refer to this mechanism as Dual Mode Journaling.
Evaluation
Section 6 in the paper contains evaluations of the block device layer, and the filesystem layer, but I’m going to jump straight to the evaluation of what it means for applications running on top.
For server workloads, the authors test varmail, a metadata-intensive workload known for heavy fsync() traffic, and an OLTP-insert workload using MySQL. When guaranteeing full durability, BFS improves varmail performance by between 10% and 60% depending on the type of SSD used. When guaranteeing only ordering, BFS gives a 36x performance improvement over ext4. For the MySQL workload, BFS gives a 12% performance boost with full durability guarantees, or a 43x performance boost with ordering only.
With SQLite BFS gives a 75% performance boost on mobile storage with full durability, and 2.8x with just ordering. With higher powered server-side controllers employing higher degrees of parallelism the BFS advantage goes up to 73x.
The last word
It is time to design a new IO stack for Flash storage that is free from the unnecessary constraint inherited from the old legacy that a host cannot control the persistence order…. the “cache barrier” command is a necessity rather than a luxury. It should be supported in all Flash storage products ranging from mobile storage to high-performance Flash storage with supercap.

Dan Gerson did the exact same thing 30 years ago when he was at HP. It’s nice to see this work rediscovered; maybe it won’t be forgotten this time!