Snuba: automating weak supervision to label training data Varma & Ré, VLDB 2019
This week we’re moving on from ICML to start looking at some of the papers from VLDB 2019. VLDB is a huge conference, and once again I have a problem because my shortlist of “that looks really interesting, I’d love to read it” papers runs to 54 long at the moment! As a special bonus for me, I’m actually going to be at VLDB this year, where no doubt I’ll learn about even more interesting things! By the time you get to read this, it should be the first (workshop) day of the conference…
The conference may have changed, but to bridge from ICML to VLDB I’m going to start with a paper on very much the same theme as we’ve been dipping into over the past couple of weeks: how to combine and learn from multiple noisy sources of data and labels. Snuba is from the same Stanford line as Snorkel which we looked at last year. It’s tackling the same fundamental problem: how to gather enough labeled data to train a model, and how to effectively use it in a weak supervision setting (supervised learning with noisy labels). In Snorkel human experts write (noisy) labelling functions, aka heuristics, but in Snuba the system itself generates its own heuristics!
Here’s the setup:
- We have a small labeled dataset, but not big enough to learn an accurate classifier
- We use the labeled dataset to learn classifiers that have good-enough accuracy over subsets of the data (features)
- We use the learned classifiers to predict labels for a much larger unlabelled dataset
- We train a final model on the now noisily labelled large dataset, and this model shows increased performance
It took me quite a while to get my head around this! We don’t have enough labeled data to learn a good classifier, but we end up learning a good classifier anyway. What magic is this? The secret is in the selection, application, and aggregation of those intermediate learned heuristics.
Snuba automatically generates heuristics that each labels the subset of the data it is accurate for, and iteratively repeats this process until the heuristics together label a large portion of the unlabeled data… Users from research labs, hospitals and industry helped us design Snuba such that it outperforms user-defined heuristics and crowdsourced labels by up to 9.74 F1 point and 13.80 F1 points in terms of end model performance.
Compared to Snorkel of course, “the key challenge in automating weak supervision lies in replacing the human reasoning that drives heuristic development.”
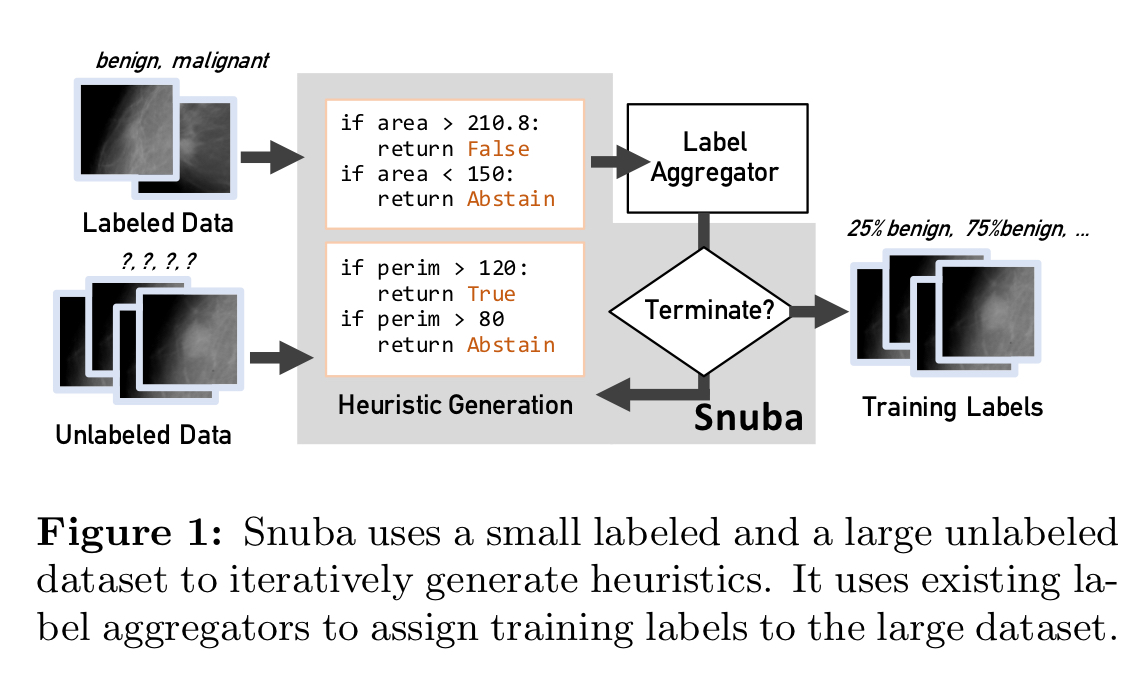
The big picture
Snuba has three main components: the synthesiser, the pruner, and the verifier. It maintains a committed set of heuristics which will be used in labelling, and in each iteration it synthesises new candidate heuristics, selects from among them to add to the committed set, and then verifies the results.
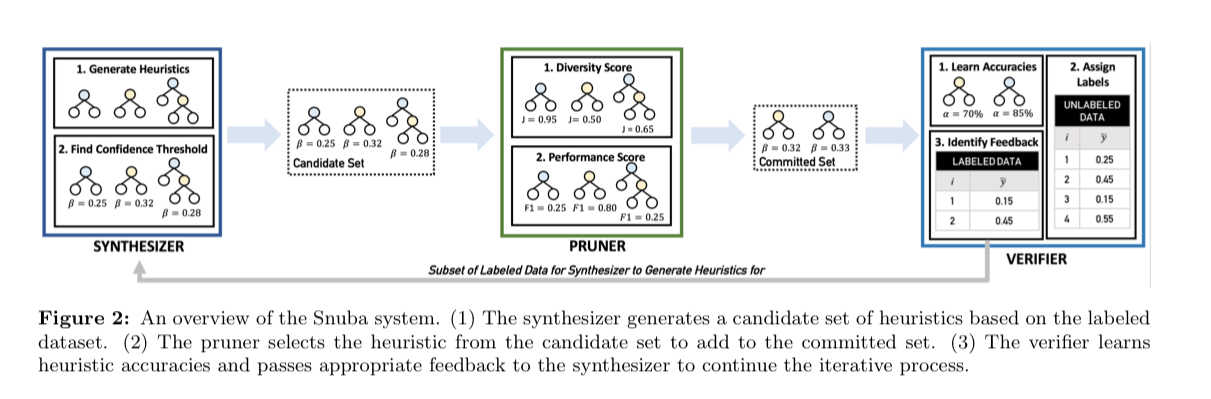
The synthesiser uses the small labelled dataset to generate new candidate heuristics. It associates each heuristic with a labelling pattern to assign labels only where the heuristic has high confidence. Allowing heuristics to abstain from labelling datapoints where they have low confidence is a key part of how Snuba achieves its final performance. Compared to noisily labelling everything the result is a smaller labelled dataset once the heuristic has been applied to the unlabelled data, but with higher confidence.
Not every candidate heuristic generated by the synthesiser ends up being used. It’s the job of the pruner to select a heuristic to add from among them.
We want the heuristics in the committed set to be diverse in terms of the datapoints in the unlabeled set they label, but also ensure that it performs well for the datapoints it labels in the labeled dataset. A diverse heuristic is defined as one that labels points that have never received a label from any other heuristics.
The pruner selects for diversity by measuring the Jaccard distance1 between the set of datapoints labelled by a candidate heuristic and the set of datapoints labelled so far.
The verifier uses a generative model to learn the accuracies of the heuristics in the committed set and produce a single probabilistic training label for each data point in the unlabeled dataset.
Generative models are a popular approach to learn and model the accuracies of different labeling sources like user-defined heuristics and knowledge bases when data is labeled by a variety of sources.
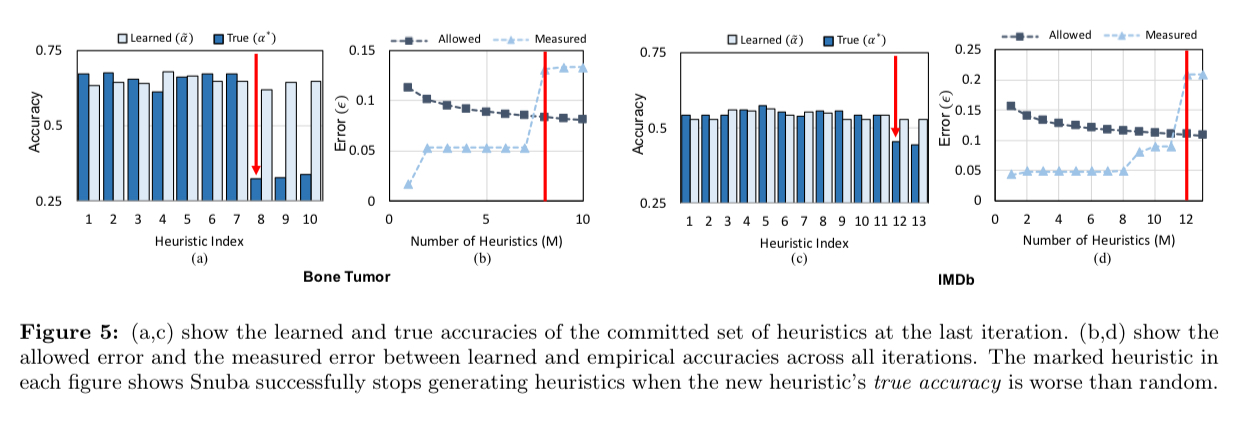
The generative model assumes that each heuristic performs better than random. For user-defined heuristics that’s a reasonable assumption, but with machine-generated heuristics that assumption could be violated. Snuba use the small labeled dataset to indirectly determine whether the generated heuristics are likely to be worse than random on the unlabeled dataset.
Snuba keeps iterating (adding new heuristics) until the estimate of the accuracy of the new heuristic suggests it performs worse than random.
Supported heuristic models
Users can plug in their own heuristic models for heuristic generation, all that’s required is that the model generates heuristics that output a probabilistic label over a subset of the data. Snuba comes with three different models out of the box:
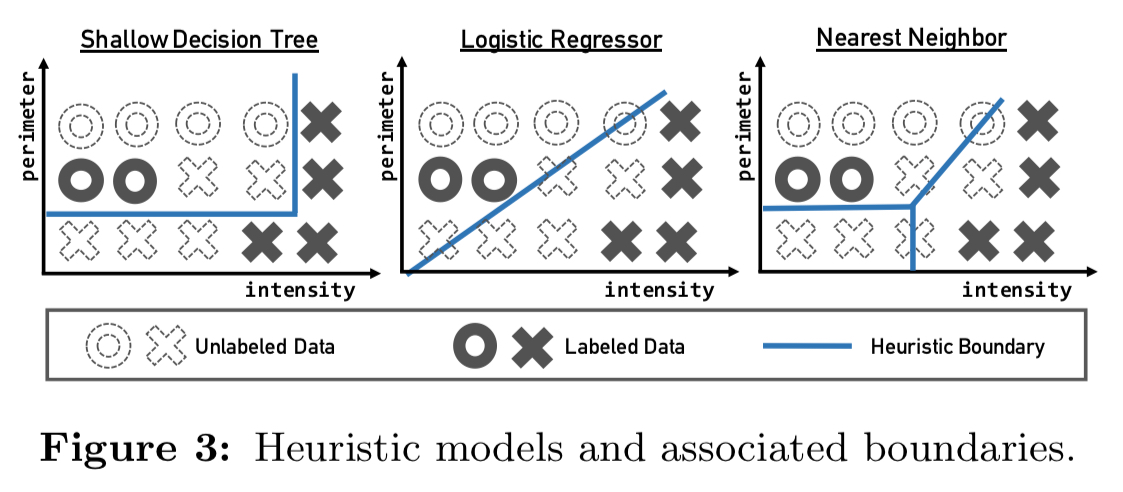
- Decision stumps are decision trees limited to a certain depth
- Logistic regressors learn a single linear decision boundary
- K-nearest neighbour relies on the distribution of the labeled datapoints to decide decision boundaries, with confidence based on the distance of an unlabelled point from a cluster.
Why does the end model performed better than a simple ensemble of the selected heuristics?
At the end of this process, we have an aggregation of heuristics that assign probabilistic labels to a large portion of the unlabelled dataset. Why not just use this aggregation as the final model??
One of the motivations for designing Snuba is to efficiently label enough training data for training powerful, downstream machine learning models like neural networks. Heuristics from Snuba are not used directly for the classification task at hand because (1) they may not label the entire dataset due to abstentions, and (2) they are based only on the user-defined primitives and fail to take advantage of the raw data representation.
For example, heuristics may be based on features such as measurements of a tumor (images), bag-of-words representations (text), or bounding box coordinates. An end model can operate over the entire raw image, sentence, or representation.
Evaluation
The evaluation demonstrates the following:
- Training labels from Snuba outperform labels from automated baseline methods by up to 14.35 F1 points, and to transfer learning from the small labelled dataset by up to 5.74 F1 points
- Training labels from Snuba outperform those from user-developed heuristics by up to 9.74 F1 points. The heuristics developed by users have very high precision, but Snuba claws back its advantage by improving recall through its diversity measures.
- Each component of Snuba plays its part in boosting overall system performance.
Experiments are conducted over a variety of different applications and datasets:
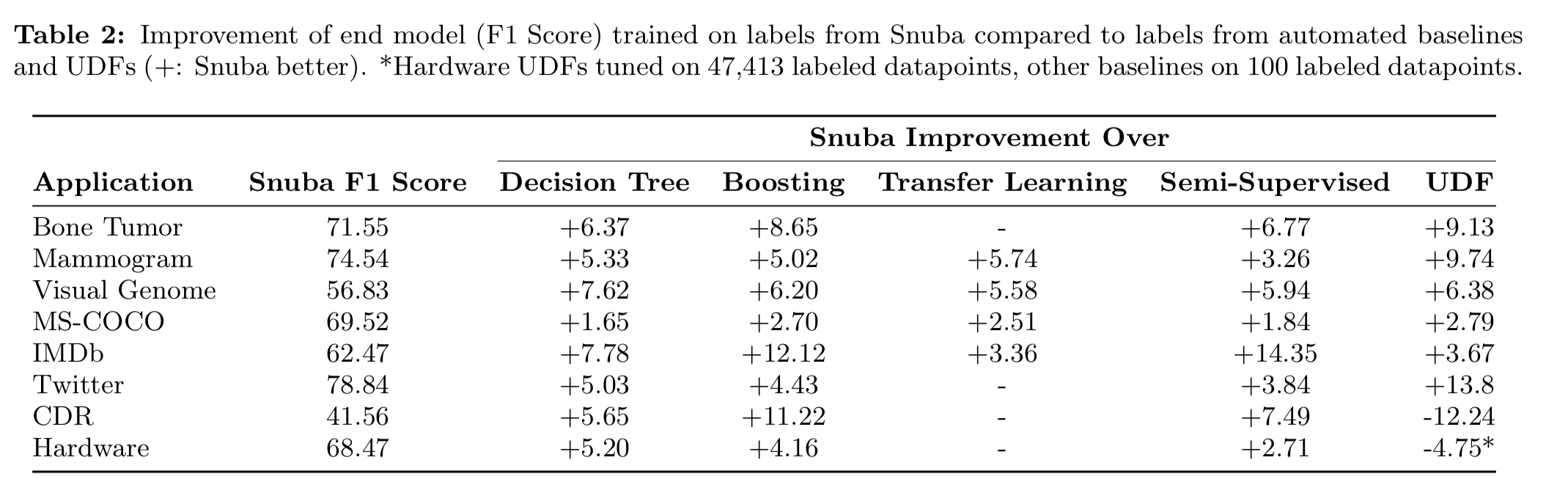
In image-based tasks Snuba generated heuristics that used at most 4 primitives, while for text-based tasks it generated heuristics that relied on only a single primitive.
Our work suggests that there is potential to use a small amount of labeled data to make the process of generating training labels much more efficient.
-
The Jaccard distance between two sets A and B is given by
. ↩

One thought on “Snuba: automating weak supervision to label training data”
Comments are closed.