Snorkel: rapid training data creation with weak supervision Ratner et al., VLDB’18
Earlier this week we looked at Sparser, which comes from the Stanford Dawn project, “a five-year research project to democratize AI by making it dramatically easier to build AI-powered applications.” Today’s paper choice, Snorkel, is from the same stable. It tackles one of central questions in supervised machine learning: how do you get a large enough set of training data to power modern deep models?
…deep learning has a major upfront cost: these methods need massive training sets of labeled examples to learn from – often tens of thousands to millions to reach peak predictive performance. Such training sets are enormously expensive to create…
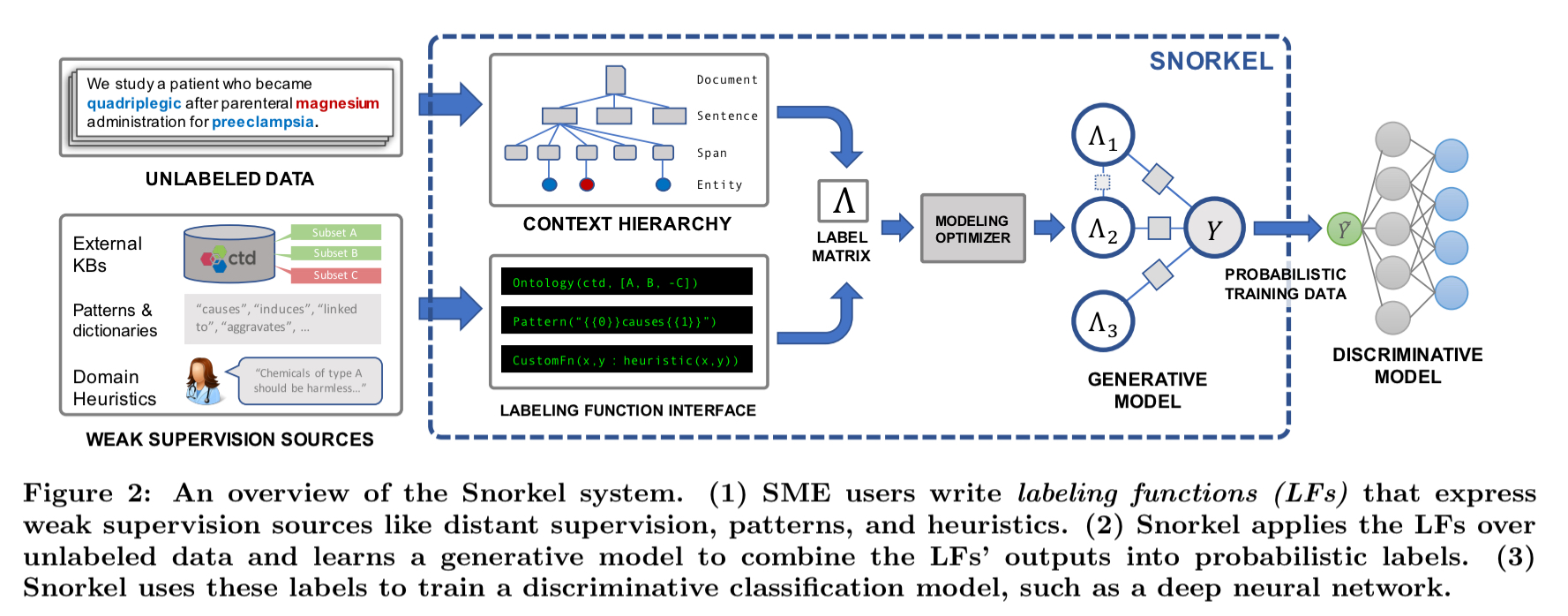
Snorkel lets you throw everything you’ve got at the problem. Heuristics, external knowledge bases, crowd-sourced workers, you name it. These are known as weak supervision sources because they may be limited in accuracy and coverage. All of these get combined in a principled manner to produce a set of probability-weighted labels. The authors call this process ‘data programming’. The end model is then trained on the generated labels.
Snorkel is the first system to implement our recent work on data programming… While programming weak supervision seems superficially similar to feature engineering, we observe that users approach the two processes very differently. Our vision – weak supervision as the sole port of interaction for machine learning – implies radically different workflows…
The big picture
There are three main stages in the Snorkel workflow:
- Instead of hand-labelling large quantities of training data, users write labelling functions which capture patterns and heuristics, connect with external knowledge bases (distant supervision), and so on. A labelling function is a Python method which given an input can either output a label or abstain. Snorkel also includes a number of declarative labelling functions that can be used out of the box.
- Snorkel learns a generative model over all of the labelling functions, so that it can estimated their accuracies and correlations. “This step uses no ground-truth data, learning instead from the agreements and disagreements of the labeling functions.”
- Snorkel outputs a set of probabilistic labels which can then be used to train a wide variety of machine learning models.
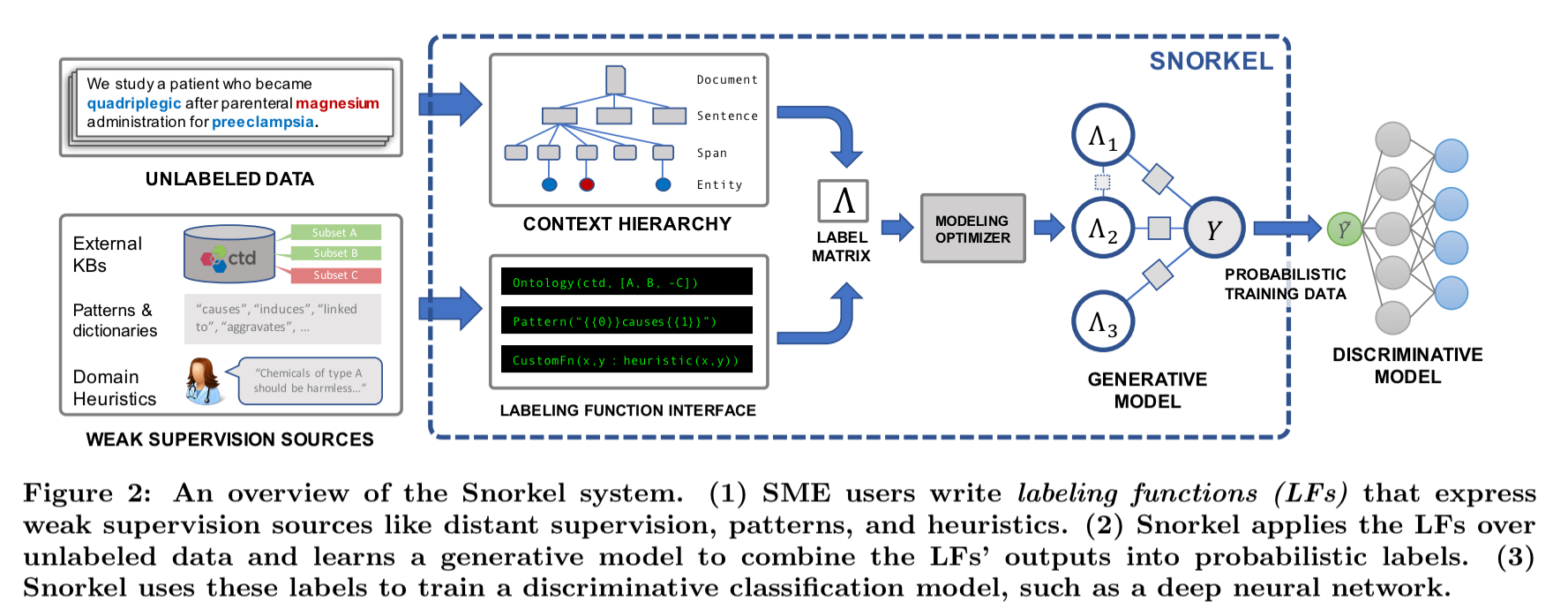
(Enlarge)
While the generative model is essentially a re-weighted combination of the user-provided labeling functions – which tend to be precise but low coverage – modern discriminative models can retain this precision while learning to generalize beyond the labelling functions, increasing coverage and robustness on unseen data.
Labelling functions
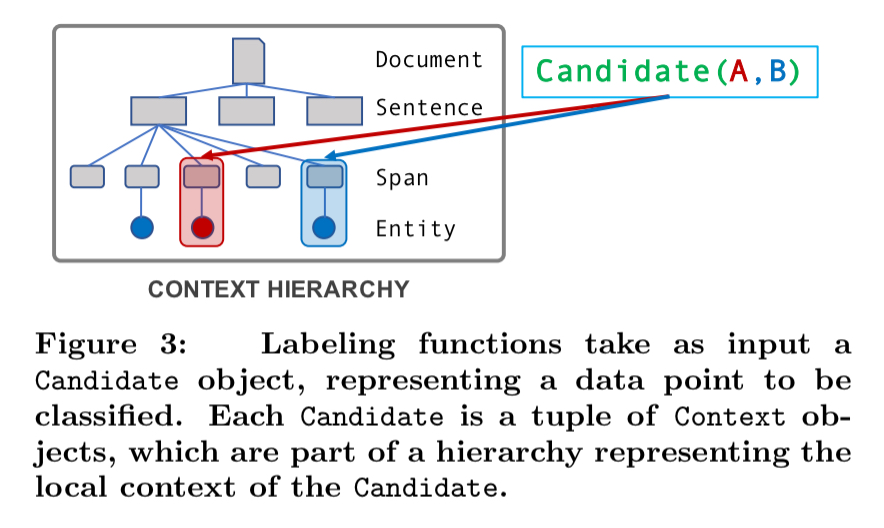
Say we’re interested in a binary classifier text-relation extraction task, in which a (chemical, disease) input tuple maps to true iff the chemical causes the disease. Snorkel breaks input documents (PubMed abstracts) down into a context hierarchy made up of context types. The set of context types that make sense will be data dependent. Here we might extract documents, sentences, spans, and entities. Tuples of relevant entities are then passed to labelling functions as candidates.
Writing in Python, a labelling function encoding the heuristic that the word ‘causes’ in-between a chemical and a disease indicates a causal relationship would look like this:

For simple cases, there are built-in declarative labelling functions. In this case, we could have used a pattern-based function instead of writing our own:
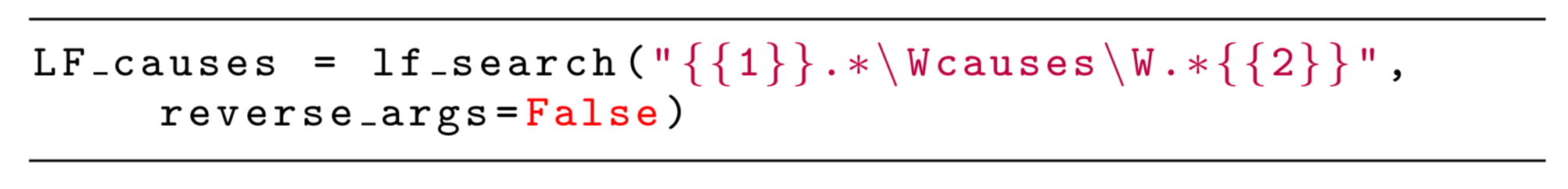
Labeling function generators create multiple labelling functions from a single resource. We could use the Comparative Toxicogenomics Database as a distant supervision source for example, and label candidates as ‘true’ if they appear in the “Causes” subset, and ‘false’ if they appear in the “Treats” subset.

One neat example in the evaluation is using a set of crowdworkers to crowdsource annotations, and then representing each crowdworker as a distinct labelling function. Snorkel will automatically learn to adapt to the different skill levels and accuracy of the workers.
The generative model
Once we have a collection of labelling functions, an obvious thing to do would be to ask each function to label a candidate and use majority voting to determine the resulting label. In fact, in situations where we don’t have many votes on an input (e.g., most of the labelling functions abstain), and in situations where we have lots of votes, then majority voting works really well. But in-between these two extremes, taking a weighted vote based on modelling labelling function accuracy works better.
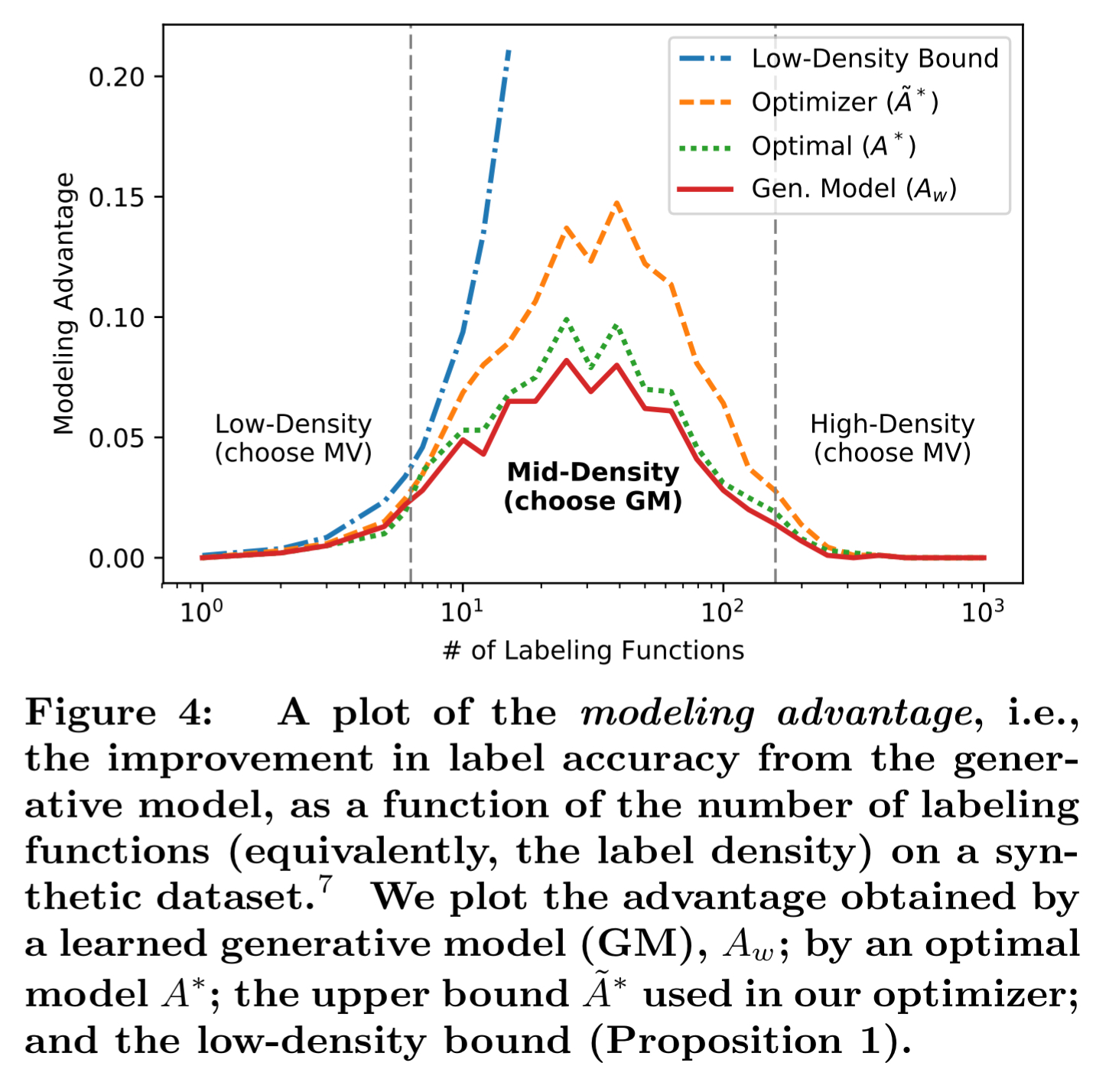
Snorkel uses a heuristic based on the ratio of positive to negative labels for each data point to decide whether to use majority voting or to build a generative model of function accuracy in order to perform weighted voting.
Essentially, we are taking the expected counts of instances in which a weighted majority vote could possibly flip the incorrect predictions of unweighted majority vote under best case conditions, which is an upper bound for the expected advantage.
When a generative model is called for it is built as a factor graph, applying all labelling functions to the unlabelled data points and capturing the labelling propensity, accuracy, and pairwise correlations of the functions. The details of learning the model are given in an earlier paper, ‘Learning the structure of generative models without labeled data.’
Dealing with correlated labels
Often the provided labelling functions are not independent. For example functions could be simple variations of each other, or they could depend on a common source of distant supervision. If we don’t account for the dependencies between labelling functions, we can get into all sorts of trouble:

Getting users to somehow indicate dependencies by hand is difficult and error-prone.
We therefore turn to our method for automatically selecting which dependencies to model without access to ground truth (See ‘Learning the structure of generative models without labeled data.’ It uses a pseudo-likelihood estimator, which does not require any sampling or other approximations to compute the objective gradient exactly. It is much faster than maximum likelihood estimation, taking 15 seconds to select pairwise correlations to be modeled among 100 labeling functions with 10,000 data points.
The estimator does rely on a hyperparameter 
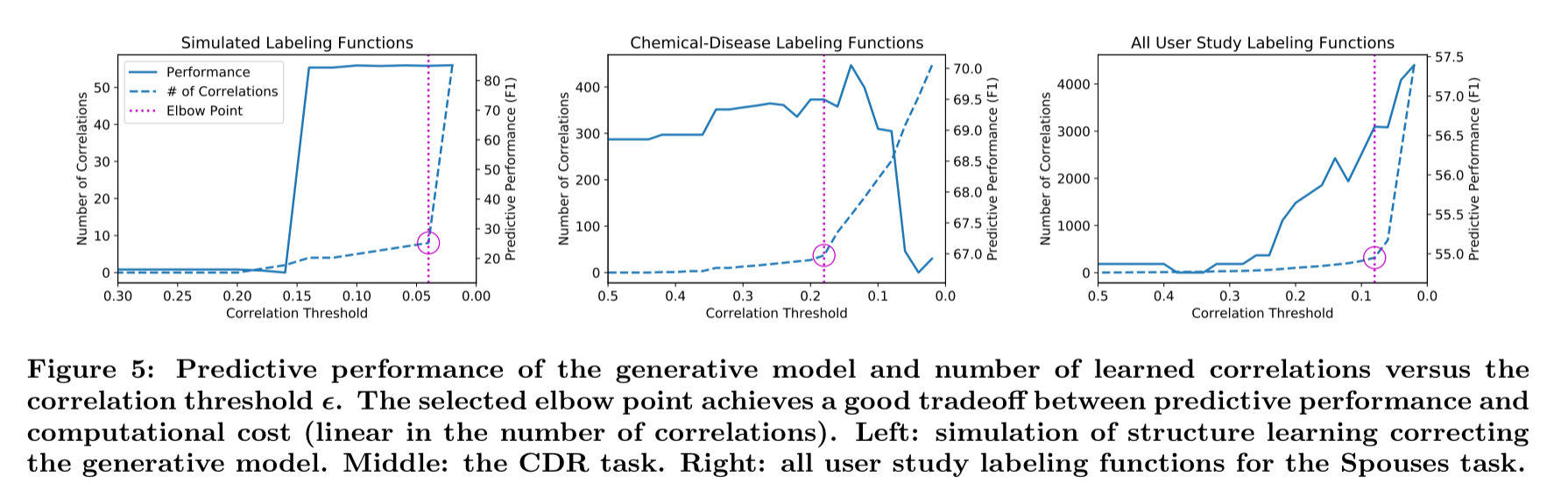
Generally, the number of correlations grows slowly at first, then hits an “elbow point” beyond which the number explodes… setting
Snorkel in action
Snorkel is evaluated across six different applications and in a user study to determine how quickly subject-matter experts could learn to write labelling functions.
In the user study, participants were given 4.5 hours of instruction on how to use and evaluate models developed using Snorkel, and then had 2.5 hours to write labelling functions, for a total time invested of 7 hours. (Workshop materials are available at https://github.com/HazyResearch/snorkel/tree/master/tutorials/workshop). Models trained with Snorkel using these labelling functions are compared to models based on seven hours of hand-labelling.
Our key finding is that labeling functions written in Snorkel, even by SME users, can match or exceed a traditional hand-labeling approach. The majority (8) of subjects matched or outperformed these hand-labeled data models. The average Snorkel user’s score was 30.4 F1, and the average hand-supervision score was 20.9 F1.
(It’s a slim majority though – there were 15 participants in the study!).
Outside of the user study, the six tasks used by the authors to evaluate Snorkel are summarised in the table below:
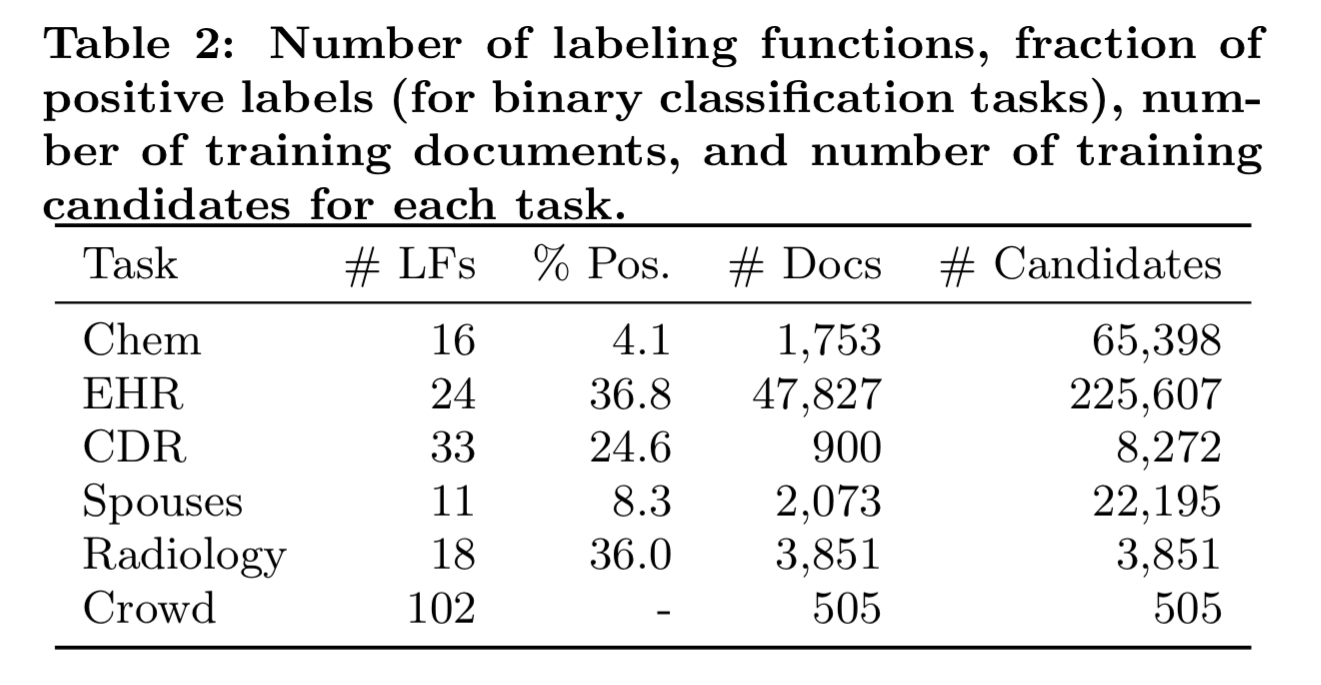
The findings show that Snorkel outperforms distant supervision baselines (by an average of 132%), and approaches hand supervision levels of accuracy with tens of labelling functions — even when the hand-labeled data has taken weeks or months to assemble. The authors also show that the discriminative models generalises beyond the heuristics encoded in the labeling functions.
Snorkel’s deployments in industry, research labs, and government agencies show that it has real-world impact, offering developers and improved way to build models.
You can read more about Snorkel, including links to the code, on the Snorkel project page.

{kind=link}
7 thoughts on “Snorkel: rapid training data creation with weak supervision”
Comments are closed.