Training classifiers with natural language explanations Hancock et al., ACL’18
We looked at Snorkel earlier this week, which demonstrates that maybe AI isn’t going to take over all of our programming jobs. Instead, we’ll be writing labelling functions to feed the machine! Perhaps we could call this task label engineering. To me, it feels a bit like programming a quick-and-dirty expert system, where the downstream generative model deals with all the inaccuracies and inconsistencies so that we don’t have to be perfect, just useful. Given the success of the approach, a natural question to ask is how we can enable end users to more easily create useful labelling functions in their domain. This is where BabbleLabble comes in!
In this work, we propose BabbleLabble, a framework for training classifiers in which an annotator provides a natural language explanation for each labeling decision. A semantic parser converts these explanations into programmatic labeling functions that generate noisy labels for an arbitrary amount of unlabeled data, which is used to train a classifier.
So much for those programming jobs ! ;)
Working with BabbleLabble, it takes users about twice as long per example to provide a label plus an explanation as it does just to label an example. (The user has to do the work of figuring out the rationale in both cases). By automatically distilling a set of labelling functions from the explanations though (we’ll get to how that bit works shortly), the end result is that on three tasks users were able to train classifiers with comparable F1 scores from 5-100x faster.
If you combine BabbleLabble with Snorkel and the advances in machine learning models, you can start to see a new end-to-end approach for the rapid creation of intelligent systems. It starts with domain knowledge capture systems, of which simply labelling an example by hand is the simplest example. Snorkel and BabbleLabble show us that we can do so much more here to capture and exploit available domain knowledge. Domain knowledge capture systems assist in the task of label engineering, and their output is a set of labelling functions. A probabilistic label generator intelligently combines the labelling functions to create a set of probabilistic labels (data programming), and finally we bolt on the end the supervised machine learning model of our choice and train it using the generated labels.
What ties all this together is that via the wonders of data programming, the labelling functions don’t have to be perfect. It’s a much lower bar to write/generate a useful labelling function than it is to create one with very high accuracy and coverage.
Don’t lose the rationale
When we ask a human annotator to provide a label for an example, we up with limited information (one bit, in the case of binary classification).
This invites the question: how can we get more information per example, given that the annotator has already spent the effort reading and understanding an example? … In this work, we tap into the power of natural language and allow annotators to provide supervision to a classifier via natural language explanations.
For example:

The captured explanations are turned into candidate labeling functions, which go through a filtering process to produce a final set of labeling functions used to drive Snorkel.

(Enlarge)
What’s very neat is that the semantic parser used to turn explanations into candidate labeling functions is generic – i.e., it the same parser can be used across different tasks without any task-specific training.
One of our major findings is that in our setting, even a simple rule-based parser suffices…
This works because the filtering stage removes inconsistent and unhelpful (e.g., assigning the same label to every example) labelling functions, and Snorkel’s data programming copes with inconsistencies and inaccuracies in those that remain. Another very interesting finding is that labelling functions that are near to the perfect logical capture of the explanation often perform better than a perfect capture. In the evaluation, this is explained thus:
In other words, when users provide explanations, the signals they describe provide good starting points, but they are actually unlikely to be optimal.
Generating labeling functions
The first step in the process is the use of a semantic parser to parse explanations and generate candidate labelling functions. Explanations follow a loose grammar (see example predicates in appendix A of the paper), and the parser iterates over input subspans looking for rule matches:
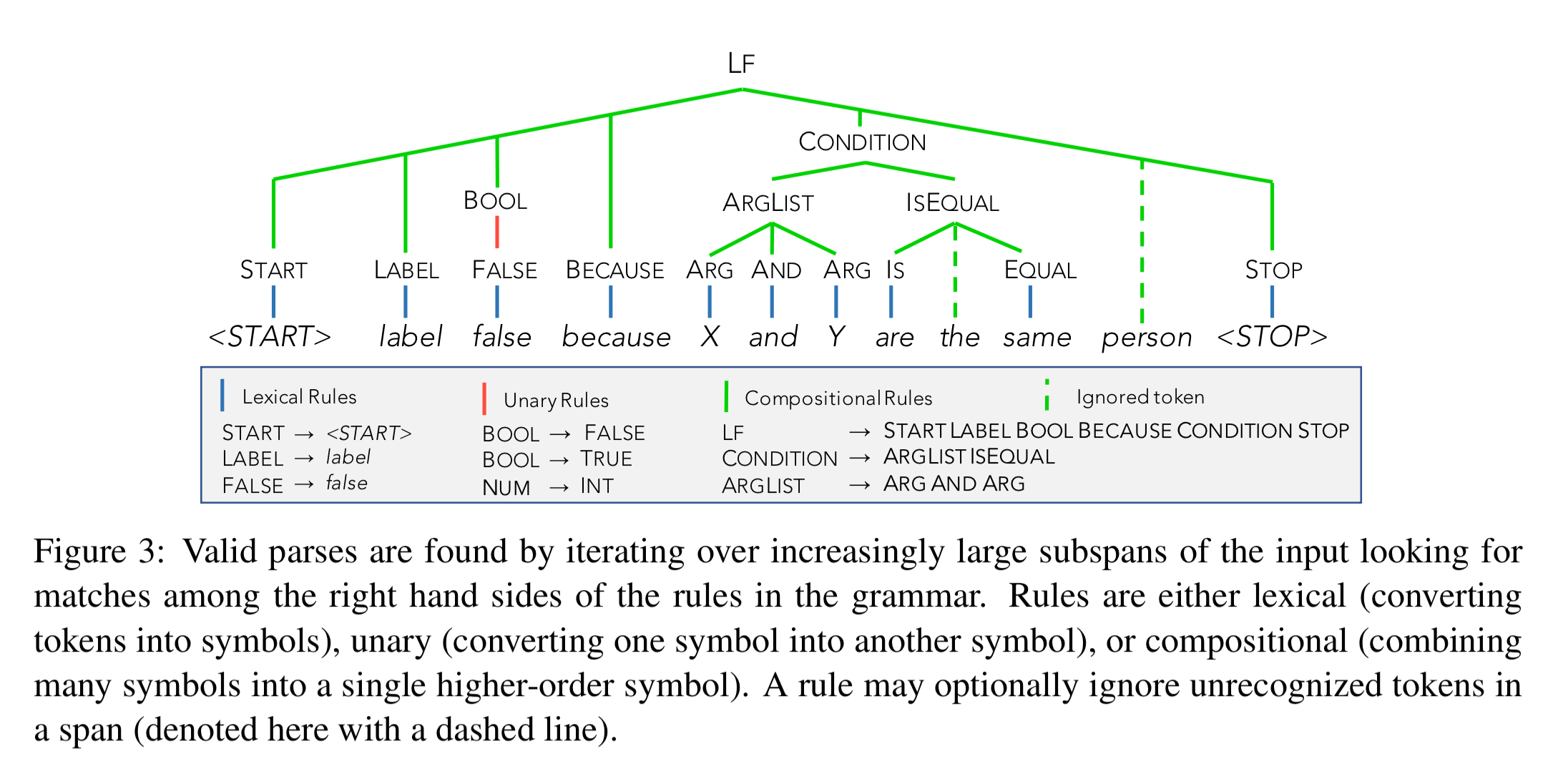
We emphasize that the goal of this semantic parser is not to generate the single correct parse, but rather to have coverage over many potentially useful LFs.
Users of the system are provided with minimal examples of all of the predicates in the grammar in use. The construction of the grammar was guided by analysing 500 free-form user-provided explanations on a spouse task. The resulting predicates are summarised in the table below. There are 200 rule templates in total.

Distilling labeling functions
The set of candidate labelling functions (LFs) produced by parsing an explanation are then filtered. A semantic filter checks that a candidate LF is actually consistent with its own example.
For example, given an explanation “True, because the words ‘his wife’ are right before person 2”, there are two possible interpretations of ‘right’. It could be ‘right before’ or ‘to the right of’. A candidate LF generated from the latter interpretation can be excluded when the example in question is “Tom Brady and his wife Gisele Bundchen were spotted in New York City on Monday amid rumors…”. (Because the words ‘his wife’ are actually to the left of person 2).
A set of pragmatic filters remove LFs that are constant (label every example the same), redundant (labels the training set identically to some other LF), or correlated.
Finally, out of all LFs from the same explanation that pass all the other filters, we keep only the most specific (lowest coverage) LF. This prevents multiple correlated LFs from a single example dominating.
Over the three tasks in the evaluation, the filter bank removes over 95% of incorrect parses, and the incorrect ones that remain have average end-task accuracy within 2.5 points of the corresponding correct parses.
Experimental results
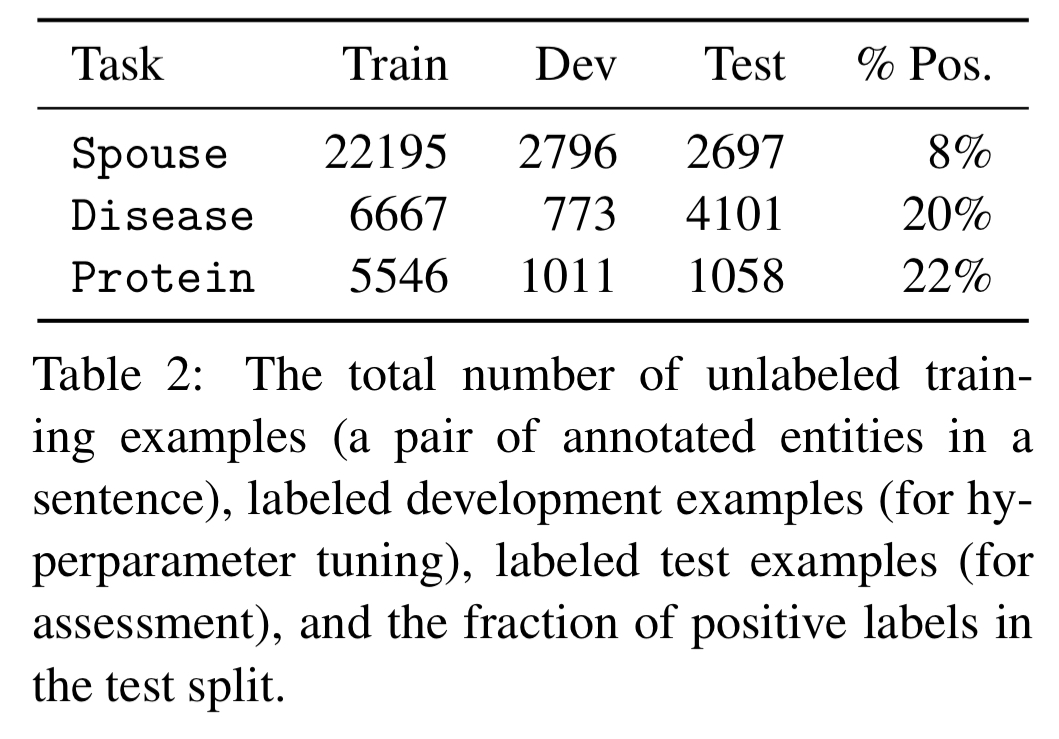
We already know from Snorkel what happens downstream of the labelling function selection process, so let’s jump straight to the evaluation section of the paper. BabbleLabble is used on three tasks, Spouse, Disease, and Protein.
In the spouse task annotators see a sentence with two highlighted names and are asked to label whether the two people are spouses (sentences taken from the Signal Media news articles dataset).
In the disease task annotators are shown a sentence with highlighted names of a chemical and a disease, and asked whether the sentences suggests the chemical causes the disease. Because the necessary domain expertise was not readily available, explanation sentences in this case were created by having someone unfamiliar with BabbleLabble translate from the labelling functions generated as part of the Snorkel publication evaluation.
The protein task was completed in conjunction with a neuroscience company called OccamzRazor. Annotators were shown a sentence from biomedical literature with highlighted names of a protein and kinase, and asked to label whether or not the kinase influences the protein in terms of a physical interaction or phosphorylation.
Example sentences and explanations from each of the three tasks are shown in the figure below.

(Enlarge)
On an F1 score basis, the a classifier trained with BabbleLabble achieves the same accuracy as a classifier trained with just end labels, using between 5x to 100x fewer examples. On the spouse task, 30 explanations are worth somewhere around 5,000 labels, on the disease task 30 explanations are worth around 1,500 labels, and on the protein task 30 explanations are worth around 175 labels.
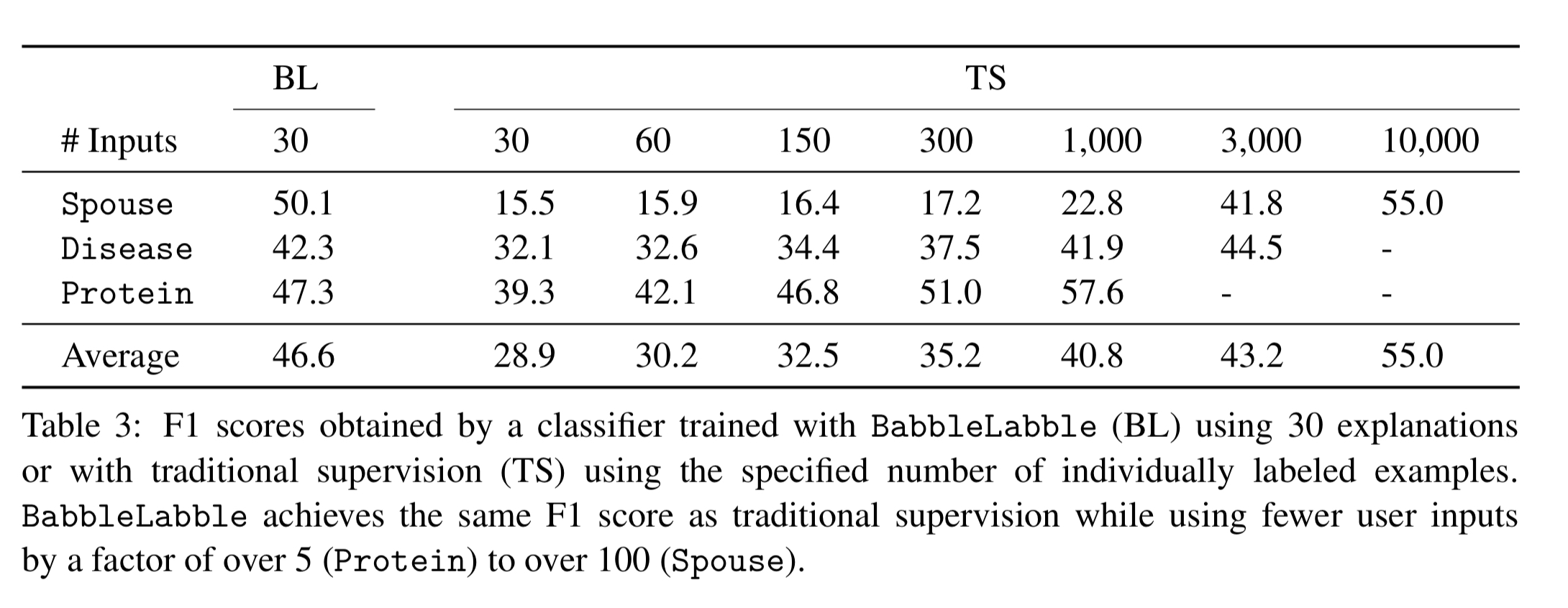
Once the number of labeled examples is sufficiently large, traditional supervision once again dominates, since ground truth labels are preferable to noisy ones generated by labeling functions. However, in domains where there is much more unlabeled data available than labeled data (which in our experience is most domains), we can gain in supervision efficiency from using BabbleLabble.
The team compared the accuracy of BabbleLabble without the LF filtering process (i.e., using all candidate LFs), BabbleLabble a as is, and BabbleLabble using ‘perfect’ parsers generated by hand to accurately translate the explanation sentences. The results show that the simple rule-based semantic parser and the perfect parser have nearly identical average F1 scores.
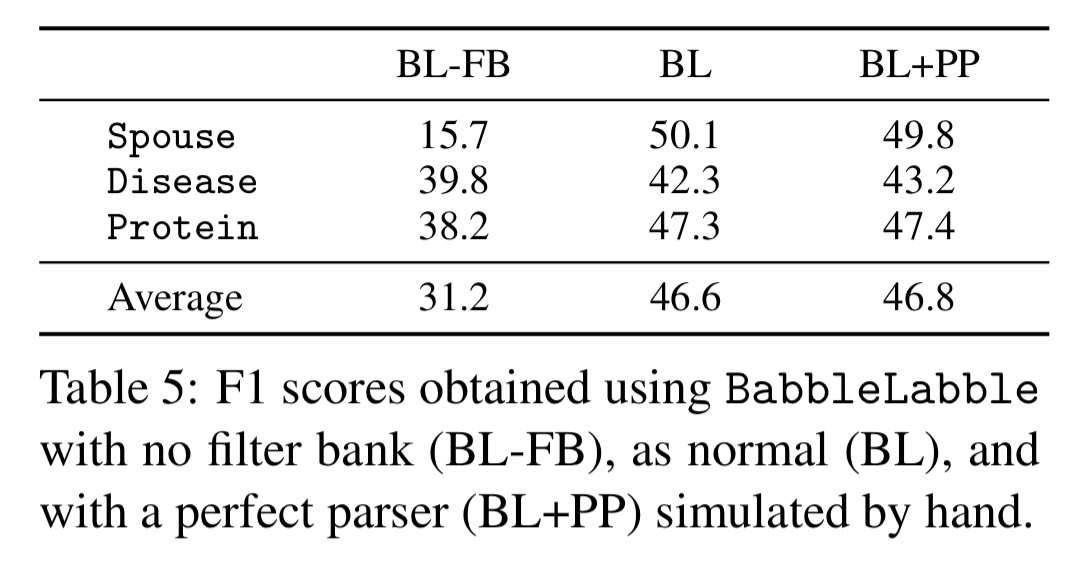
Incorrect LFs still often provide useful signal.

(Enlarge)
Learn more
- Babble Labble blog post from the authors
- Code, data, and experiments from this paper

{kind=link}
{kind=link}
{kind=link}
7 thoughts on “Training classifiers with natural language explanations”
Comments are closed.