Software engineering for machine learning: a case study Amershi et al., ICSE’19
Previously on The Morning Paper we’ve looked at the spread of machine learning through Facebook and Google and some of the lessons learned together with processes and tools to address the challenges arising. Today it’s the turn of Microsoft. More specifically, we’ll be looking at the results of an internal study with over 500 participants designed to figure out how product development and software engineering is changing at Microsoft with the rise of AI and ML.
… integration of machine learning components is happening all over the company, not just on teams historically known for it.
A list of application areas includes search, advertising, machine translation, predicting customer purchases, voice recognition, image recognition, identifying customer leads, providing design advice for presentations and word processing documents, creating unique drawing features, healthcare, improving gameplay, sales forecasting, decision optimisation, incident reporting, bug analysis, fraud detection, and security monitoring.
As you might imagine, these are underpinned by a wide variety of different ML models. The teams doing the work are also varied in their make-up, some containing data scientists with many years of experience, and others just starting out. In a manner that’s very reminiscent of the online experimentation evolution model at Microsoft we looked at previously, data science moves from a bolt-on specialized skill to a deeply integrated capability over time:
Some software teams employ polymath data scientists, who “do it all,” but as data science needs to scale up, their roles specialize into domain experts who deeply understand the business problems, modelers who develop predictive models, and platform builders who create the cloud-based infrastructure.
To help spread these skills through the company a variety of tactics are used: a twice-yearly internal conference on machine learning and data science dedicates at least one day to the basics of technologies, algorithms, and best practices; internal talks are given year round on engineering details behind projects, and cutting-edge advances from academic conferences; several teams host weekly open forums on ML and deep learning; and there are mailing lists and online forums with thousands of participants.
A survey informed by conversations with 14 experienced ML leaders within Microsoft was sent to 4,195 members of those internal mailing lists, garnering 551 replies. Respondents were well spread across data and applied science (42%), software engineering (32%), program management (17%), research (7%) and other (1%). 21% of respondents were managers and the rest were individual contributors.
A general process
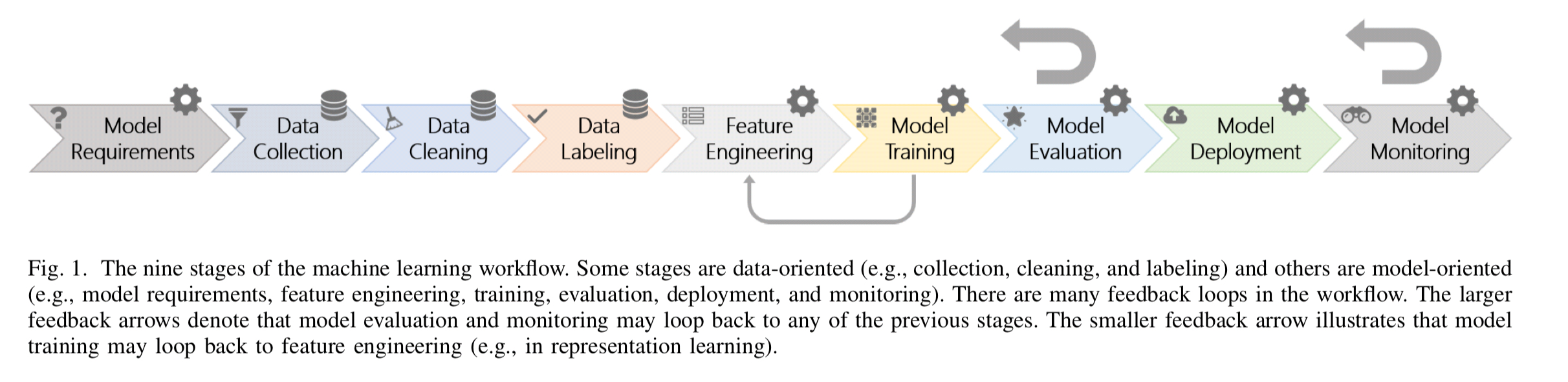
The generic machine learning process looks like this:
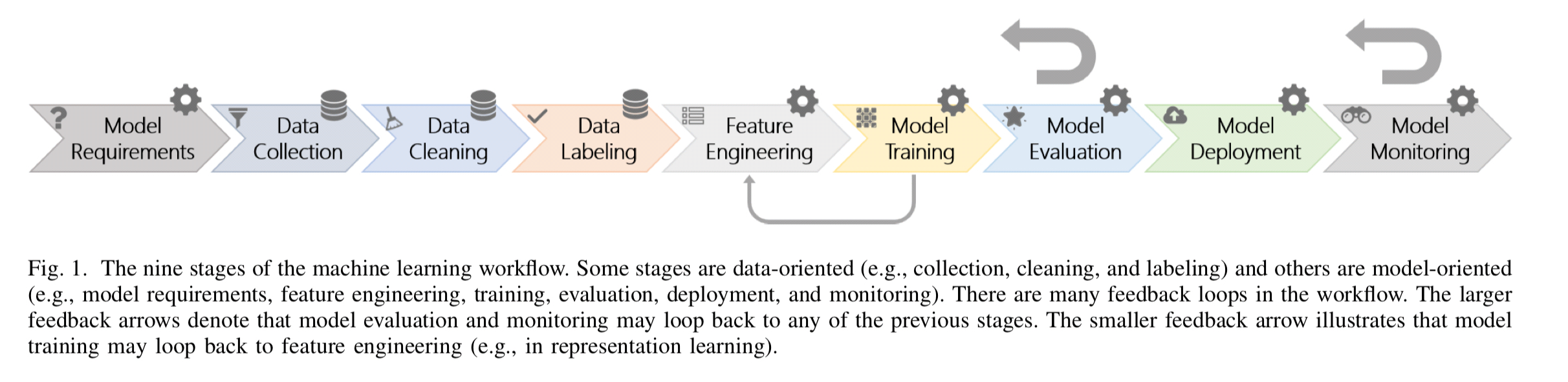
(Enlarge)
That diagram is hopefully pretty self-explanatory so I won’t spell out all of the individual stages.
For simplicity the view in Figure 1 is linear, however, machine learning workflows are highly non-linear and contain several feedback loops. For example, if engineers notice that there is a large distribution shift between the training data and the data in the real world, they might want to go back and collect more representative data and rerun the workflow… This workflow can become even more complex if the system is integrative, containing multiple ML components which interact together in complex and unexpected ways.
Learnings and emerging best practices
- Having a seamless development experience covering (possibly) all the different stages in the process outlined above is important to automation. But getting there is far from easy!
It is important to develop a “rock solid data pipeline, capable of continuously loading and massaging data, enabling engineers to try out many permutations of AI algorithms with different hyper-parameters without hassle.”
- IDEs with visual tools are useful when starting out with machine learning, but teams tend to grow out of them with experience.
- The success of ML-centric projects depends heavily on data availability, quality, and management.
In addition to availability, our respondents focus most heavily on supporting the following data attributes: “accessibility, accuracy, authoritativeness, freshness, latency, structuredness, ontological typing, connectedness, and semantic joinability.”
- Microsoft teams found a need to blend traditional data management tools with their ML frameworks and pipelines. Data sources are continuously changing and rigorous data versioning and sharing techniques are required. Models have a provenance tag explaining which data it has been trained on and which version of the model was used. Datasets are tagged with information about where they came from and the version of the code used to extract it.
- ML-centric software also sees frequent revisions initiated by model changes, parameter tuning, and data updates, the combination of which can have a significant impact on system performance. To address this, rigorous rollout processes are required.
… [teams] developed systematic processes by adopting combo-flighting techniques (i.e., flighting a combination of changes and updates), including multiple metrics in their experiment score cards, and performing human-driven evaluation for more sensitive data categories.
- Model building should be integrated with the rest of the software development process, including common code repositories and tightly coupled sprints and stand-ups.
-
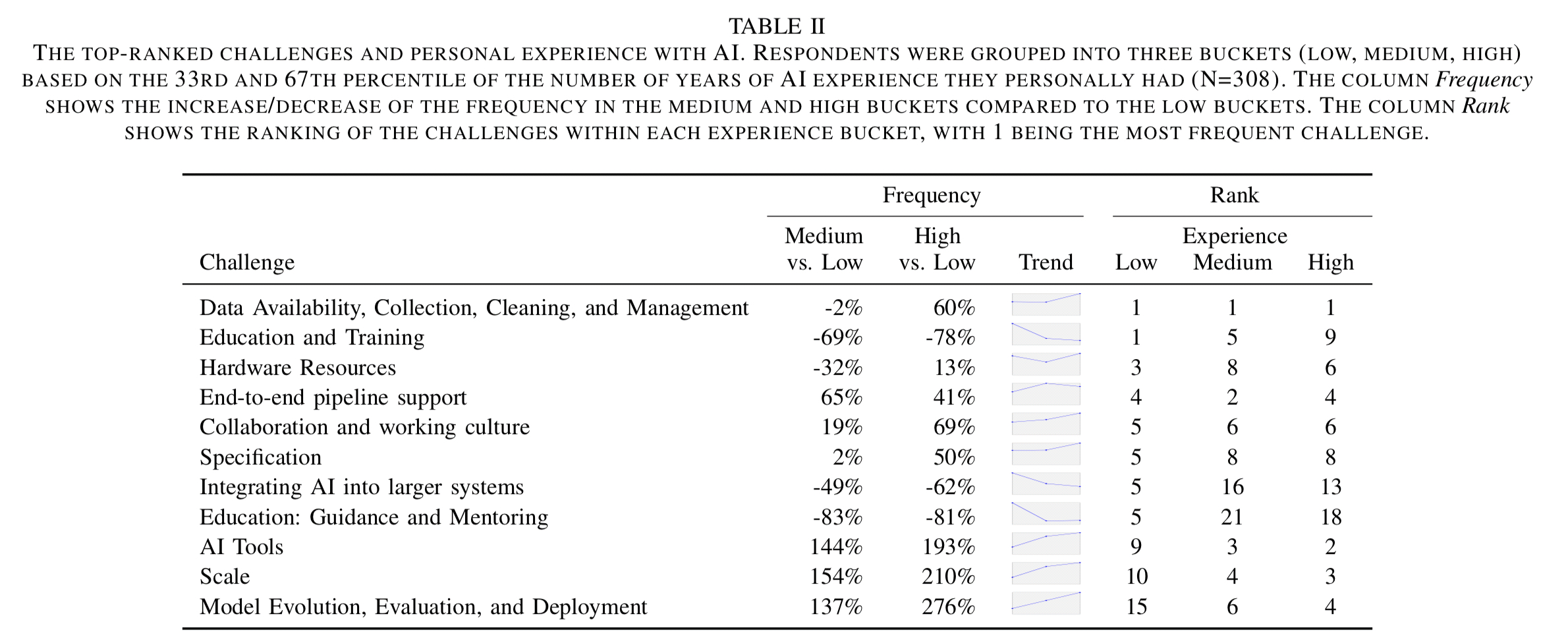
The support a team requires changes according to their level of experience with ML, but regardless of experience levels, data availability, collection, cleaning, and management remains the number one concern!
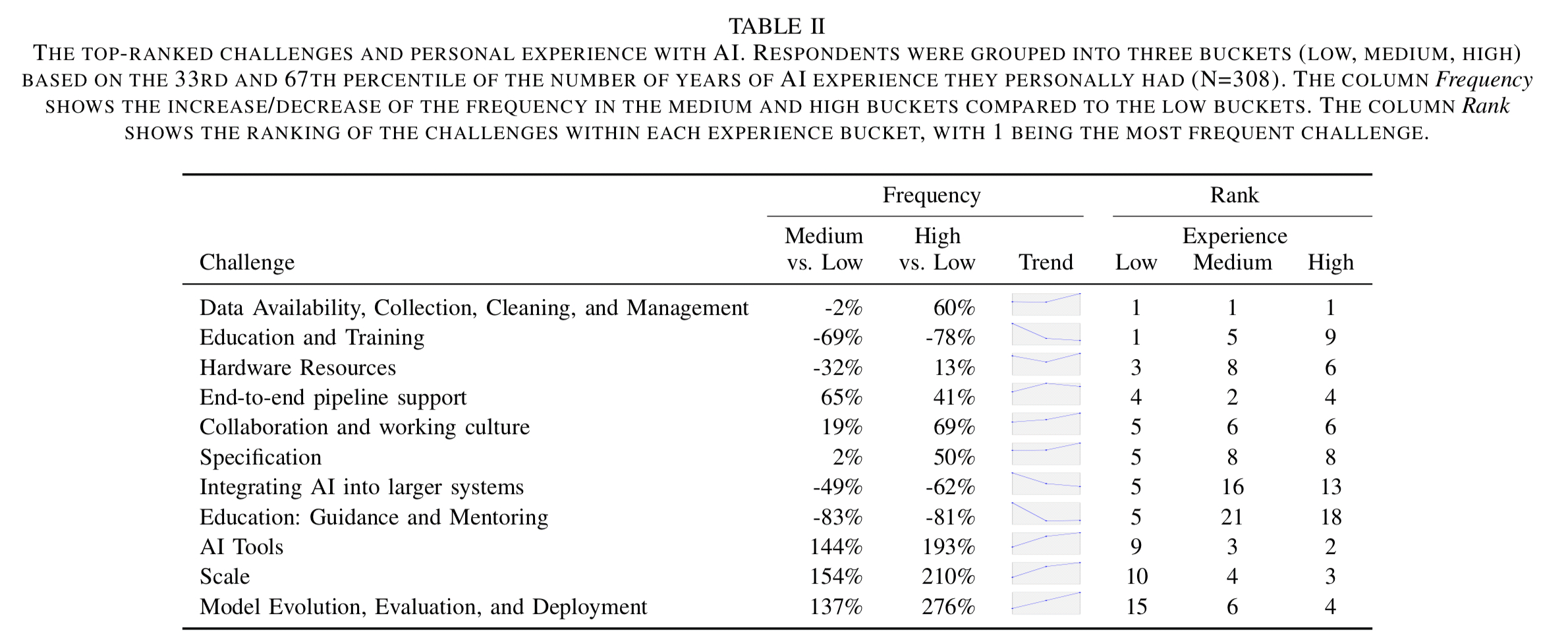
(Enlarge)
The big three
We identified three aspects of the AI domain that make it fundamentally different than prior application domains. Their impact will require significant research efforts to address in the future.
- Discovering, managing, and versioning the data needed for machine learning applications is much more complex and difficult than other types of software engineering. “While there are very well-designed technologies to version code, the same is not true for data…“
- Model customisation and model reuse require very different skills than those typically found in software teams (“you can’t simply change parameters with a text editor” !!).
- AI components are more difficult to handle as distinct modules than traditional software components — models may be “entangled” in complex ways and experience non-monotonic error behaviour.
While the first two points are hopefully pretty self-explanatory, the third warrants a little more unpacking.
Maintaining strict module boundaries between machine learned models is difficult for two reasons. First, models are not easily extensible. For example, one cannot (yet) take an NLP model of English and add a separate NLP model for ordering pizza and expect them to work properly together… Second, models interact in non-obvious ways. In large scale systems with more than a single model, each model’s results will affect one another’s training and tuning processes.
Under these conditions, even with separated code, one model’s effectiveness can change as a result of changes in another model. This phenomenon is sometimes known as component entanglement and can lead to non-monotonic error propagation: improvements in one part of the system may actually decreases the overall system quality.

{kind=link}
{kind=link}
I was wondering if I could republish this article in ACM SIGSOFT Software Engineering Notes?
I think it would be of interest to our readers
Thank you.
You are very welcome to, so long as a prominent link to the original ICSE paper I’m discussing is also included (i.e., the very first thing in my post, https://www.microsoft.com/en-us/research/publication/software-engineering-for-machine-learning-a-case-study/). Thanks, Adrian.
Sprints have no place in ML. They’re for routine boring software programming only, or maybe not even for it. Essentially, creative work demands experimentation and room to think which is not afforded by sprints.
thanks for sharing your information about performance management software but more efficient software is
Performance Management Software in Qatar
Performance Management Software in Qatar
Performance Management Software in Qatar
Machine learning is a wonderful career option for students. Software engineering can be a plus point in the field of machine learning. Thank you very much for sharing this information here. There are a lot of students that adopt machine learning and get good career opportunities.
Azure machine learning