The evolution of continuous experimentation in software product development Fabijan et al., ICSE’17 (Author personal version here)
If you’ve been following along with the A/B testing related papers this week and thinking “we should probably do more of that in my company,” then today’s paper choice is for you. Anchored in experiences at Microsoft, the authors describe a tried and tested roadmap for gradually introducing a more data-driven culture in an organisation.
… despite having data, the number of companies that successfully transform into data-driven organizations stays low and how this transformation is done in practice is little studied.
If you can get there though, as we’ve seen earlier this week, the benefits can be large. “The impact of scaling out the experimentation platform across Microsoft is in hundreds of millions of dollars of additional revenue annually.” (Though to put this in context, in 2016 Microsoft generated $85.3B in revenue).
It’s interesting to see the perspective of the authors of continuous experimentation being the next logical step in the evolution of software product development practices. I’m reminded of Martin Fowler’s “You need to be this tall to use microservices.”
At first [companies] inherit the Agile principles within the development part of the organization and expand them to other departments. Next, companies focus on various lean concepts such as eliminating waste, removing constraints in the development pipeline, and advancing towards continuous integration and continuous deployment… Continuous deployment is characterized by a bidirectional channel that enables companies not only to send data to their customers to rapidly prototype with them, but also to receive feedback data from products in the field.
It’s a great observation that CD facilitates this two-way flow of information. Once you get to CD though, the journey is not over, in fact in a sense it’s only just beginning:
Controlled experimentation is becoming the norm in advanced software companies for reliably evaluating ideas with customers in order to correctly prioritize product development activities.
As we’ll soon see, when you reach the upper levels of controlled experimentation maturity, you’re essentially doing Continuous Experimentation (which I’m going to christen ‘CE,’ so that we can go on a journey from CI -> CD -> CE!).
The Experimentation Evolution Model
The paper contains some background information on how the experimentation roadmap (“Experimentation Evolution Model”) was arrived at. It combines historical data points collected over a period of two years, a series of semi-structured interviews, and most importantly, “an internal model used at [the Analysis and Experimentation team at Microsoft] which is used to illustrate and compare progress of different product teams on their path towards data-driven development at scale.” Even though it’s based primarily in experiences at Microsoft (some of the expert participants also had experiences elsewhere), the authors believe it should have more general applicability, and that certainly seems credible to me. You can use it to benchmark your own company’s sophistication, and plan the next steps on your improvement journey.
… we present the transition process model of moving from a situation with ad-hoc data analysis towards continuous controlled experimentation at scale. We name this process the “Experimentation Evolution Model.”
Most of what you need to know is encapsulated in this handy chart, which shows maturity levels crawl, walk, run, and fly across three dimensions: technical, organisational, and business.
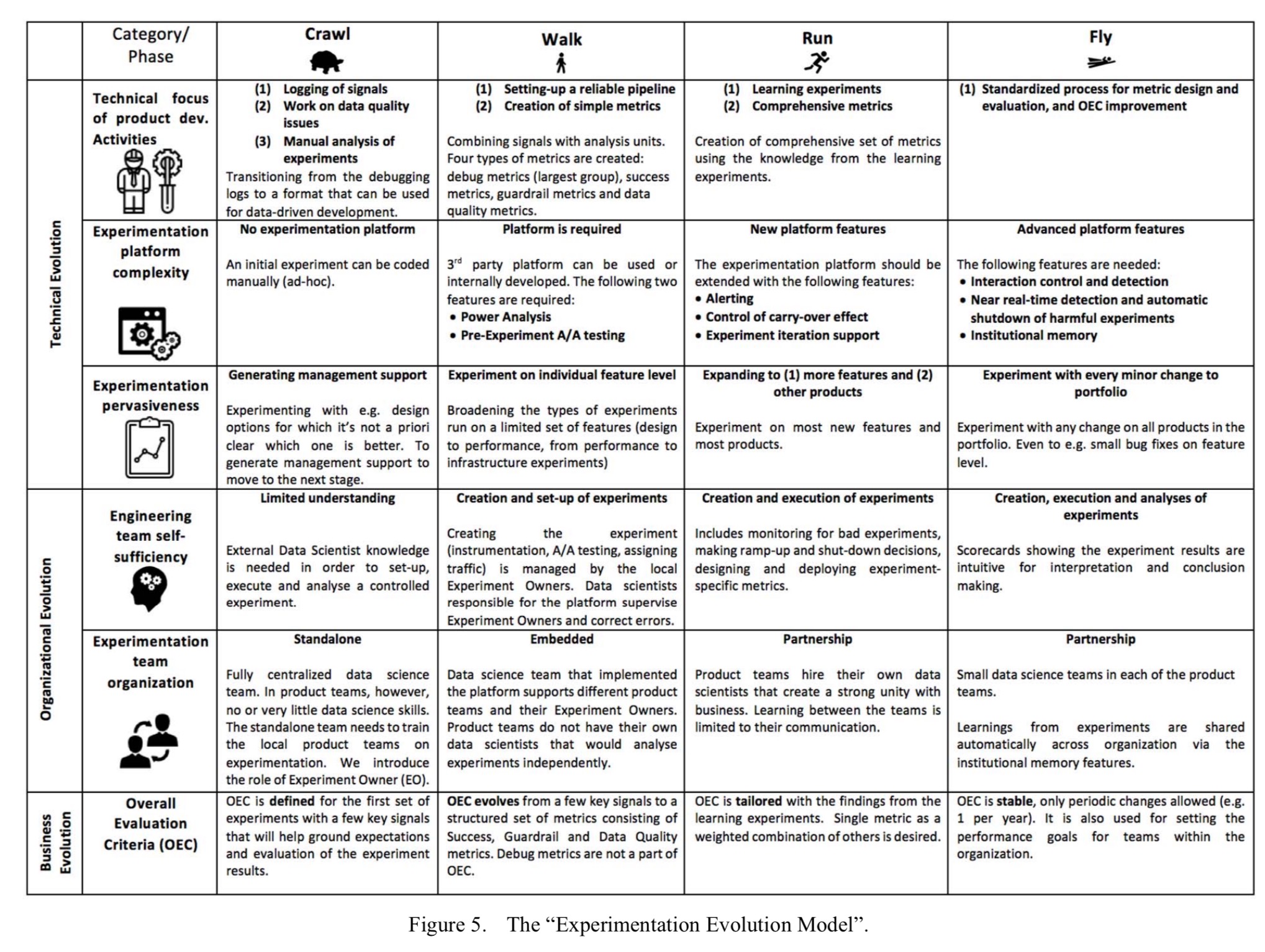
(Enlarge).
Before you get started: pre-requisites
Most of what you need to learn you can pick up as you grow in experience, but there are two foundations you need in place right at the very beginning: a base level of statistical understanding, and the ability to access product instrumentation data.
To evaluate the product statistics, skills that are typically possessed by data scientists are required within the company. Here, we specifically emphasize the understanding of hypothesis testing, randomization, sample size determination, and confidence interval calculation with multiple testing.
The Hypothesis Kit can guide you through some of the basics here.
Regarding instrumentation data, you can add the necessary instrumentation as you go along, but the thing you really need to consider up-front are the policies that allow experimenters access to the data.
In some domains, this is a serious concern and needs to be addressed both on legal and technical levels.
Crawl
Welcome to your first experiment. With a policy in place, you’re going to need some data to work with. Time to start thinking a little differently about your logging system!
In non-data driven companies, logging exists for the purpose of debugging product features. This is usually very limited and not useful for analyzing how users interact with the products. Logging procedures in the organization need to be updated by creating a centralized catalog of events in the form of class and enumeration, and implemented in the product telemetry.
At Microsoft, the raw data collected or sent from a product or feature are called signals (clicks, swipes, time spent loading a feature, and so on). From the signals, an analyst should be able to reconstruct the interactions a user had with the product.
You don’t need an experimentation platform to run your first experiment, just split your users between two version of the same product and measure how the signals differ between the versions. For guidance on calculating the statistics behind a controlled experiment the authors recommend “Controlled experiments on the web: survey and practical guide.”
Since product teams may not have the necessary expertise, they’ll require training and help from a standalone data scientist team. (MVP: a data scientist).
The main purpose of the first experiments is to gain traction and evangelize the results to obtain the necessary funding needed to develop an experimentation platform and culture within the company.
In the crawl phase, you’ll also define the first version of your Overall Evaluation Criteria. Teams should be informed that this will develop over time.
Walk
In the crawl phase you had basic signals. But in the walk phase we now define metrics based on those signals:
Metrics are functions that take signals as an input and output a number per unit… Microsoft recognizes three classes of signals for their products: action signals (e.g., clicks, page views, visits etc.), time signals (minutes per session, total time on site, page load time etc.), and value signals (revenue, units purchased, ads clicked, etc.).
Units of analysis vary depending on context, but could be for example per user, per session, per user-day, and per experiment.
A popular research contribution from Google provides practical guidance on the creation of these metrics for measuring user experience on a large scale: “Measuring the user experience on a large scale: user-centered metrics for web applications.”
At the same time as introducing metrics, you’ll want to start working with a basic experimentation platform. You can develop your own, or use a commercial offering.
Regardless of the decision, the experimentation platform should have two essential features integrated in this phase: (1) Power analysis, and (2) Pre-experiment A/A testing.
Power analysis lets you determine the minimal sample size, and A/A testing gives you confidence the basic setup is working.
Experiment ownership moves the the product manager, but execution, monitoring, and analysis is still done by data scientists. These data scientists may be embedded within the product teams, and they communicate and work with a central data science team responsible for the platform. (I guess a lighter-weight version if you’re using a commercial experimentation platform would be to form a guild).
In contrast to the “crawl” phase, the OEC will evolve from a few key signals to a structured set of metrics consisting of success metrics, guardrail metrics, and data quality metrics.
(We looked at these different metric types earlier this week).
Run
In the run phase, the number of experiments starts to really ramp up, let’s say 100 or so experiments a year. Metrics become more sophisticated, evolving from counting signals to more abstract concepts such as ‘loyalty’ and ‘success.’
To evaluate the metrics product teams should start running learning experiments where a small degradation in user experience is intentionally introduced for learning purposes (e.g., degradation of results, slowdown of a feature). With such learning experiments, teams will have a better understanding of the importance of certain features and the effect that changes have on the metrics.
To support all this activity, the experimentation platform also needs to evolve. At this stage, you probably want to add alerting, control of carry-over effects, and experiment iteration support.
Alerting enables you to divert traffic to the control if an emergency situation occurs. “The naive approach to alerting on any statistically significant negative metric changes will lead to an unacceptable number of false alerts.” We looked at the reason for this yesterday – it’s just the other side of the coin of the early stopping problem. Guidance on avoiding this situation and developing useful alerting can be found in ‘Online controlled experiments at large scale‘ (section 4.3).
Carry-over effects are when results from a prior experiment may colour a future one. A feature that re-randomizes the population between experiments can address this. Experiment iteration support allows experiments to start on a small percentage of traffic and be gradually expanded.
Initially, experiments in this phase should start on a small percentage of traffic (e.g. 0.5% of users)… over time the percentage should automatically increase if on alerts on guardrail metrics were triggered beforehand.
This helps to minimise the risk of user harm from experiments that have a negative impact.
At the run phase, experimentation is simply “what you do.”
Product teams should be experimenting with every increment to their products (e.g., introduction of new features, algorithm changes, etc.). Experimenting should be the norm for identifying the value of new features as well as for identifying the impact of smaller changes to existing features.
Data scientists are now employed directly by the product teams, and are trained by the central platform data science team to become local operational data scientists.
Fly
In the fly phase you can’t move without running an experiment it seems! “Controlled experiments are the norm for every change to any product in the company’s portfolio.”
… every small change to any product in the portfolio (e.g., a minor bug fix) should be supported by data from a controlled experiment.
(Minor bug fixes? Really? I guess the notion here is that any change, even a bug fix, could unintentionally impact metrics. For example, suppose the fix introduces a small performance delay…).
At this stage the OEC is stable and well-defined, and product teams invest in standardizing metric design and evaluation practices, and scheduling activities to update the existing OEC when needed.
With thousands of experiments simultaneously active, you’ll need a bit more sophistication in your platform too:
- Interaction control and detection, to figure out when experiments with conflicting outcomes are run on the same set of users.
- The alerting on guardrail metrics that happened based on periodic evaluation in the run phase needs to become near real-time, and the emergency shutdown functionality is automatic.
- You should introduce some way of capturing experiments that have been run and their results, as an institutional memory.
Where does your company fit on the experimentation evolution model?

{kind=link}
If you have 100 million daily users, then a minor bugfix with a 0.01% failure rate will break 10,000 users. At that level of scale, A/B testing and controlled rollout is required just for safety’s sake.
(Full disclosure: I am a Microsoft employee.)
Reblogged this on #ai #ml #big #better #data #retail #sales #marketing #innovation #newfutureishere plz use me ref: for +GrowByData vacancies: Email: inquiries@growbydata.com For more details visit: http://www.growbydata.com/career-overview.php and commented:
The evolution of continuous experimentation in software product development
The evolution of continuous experimentation in software product development
One of the authors – Aleksander here: Thank you for this extensive summary of our paper – I was surprised to learn how much impact this paper had in the Experimentation Community.
I wish to add that we recently created a web service to enable companies to anonymously and consistently evaluate their experimentation maturity based on this model. It is available over here: http://www.exp-growth.com/ and if you are growing your experimentation you are welcome to give it a try and learn how mature they are.