Google Vizier: a service for black-box optimization Golovin et al., KDD’17
We finished up last week by looking at the role of an internal (or external) experimentation platform. In today’s paper Google remind us that such experimentation is just one form of optimisation. Google Vizier is an internal Google service for optimising pretty much anything. And if you use for example Google’s public HyperTune system (part of the Google Cloud Machine Learning Engine service), then you’re using Vizier under the covers.
The very opening sentences of the abstract are worth dwelling on for a moment here:
Any sufficiently complex system acts as a black box when it becomes easier to experiment with than to understand. Hence, black-box optimization has become increasingly important as systems become more complex.
This is recognising something important happening all around us: we’ve made systems of sufficient emergent complexity that we don’t truly understand them anymore. Or perhaps we could understand them with enough effort, but that barrier is so high that it’s easier just to ‘try a few things and see what happens.’
At the tail end of the paper we find something else very much of our times, and so very Google. If you ever find yourself in the Google cafeteria, try the cookies. The recipe for those cookies was optimised by Vizier, with trials sent to chefs to bake, and feedback on the trials obtained by Googler’s eating the results.
Vizier is a scalable, state-of-the-art internal service for black-box optimization within Google.
It has already proven to be a valuable platform for research and development, and we expect it will only grow more so as the area of black-box optimization grows in importance. Also, it designs excellent cookies, which is a very rare capability among computational systems.
Black-box optimisation
The delightful thing about black-box optimisation and Vizier, is that on the outside, it’s so simple.
Black-box optimization is the task of optimizing an objective function
with a limited budget for evaluations. The adjective “black-box” means that while we can evaluate
for any
, we have no access to any other information about
, such as gradients or the Hessian.
There’s a certain cost to performing each evaluation, so we want to be smart about how we explore the space, with the overall goal of finding the best operating parameters 

- A trial is a list of parameter values,
, but I’ll stick with the notation in the paper) that will lead to a single evaluation of
- A study is a single optimisation run over a feasible space. You describe the space when setting up the study. It is assumed that
- A worker is a process responsible for evaluating a pending trial and calculating its objective value.
There are lots of different approaches to optimisation (we’ve looked at several in previous editions of The Morning Paper), including Bayesian Optimisation, Derivative-free optimisation, Sequential Experimental Design, and variations on multi-armed bandits. Vizier supports multiple different algorithms under the cover, with a default of ‘Batched Gaussian Process Bandits’.
Example use cases at Google
- Hyperparameter tuning of machine learning models. “Our implementation scales to service the entire hyperparameter tuning workload across Alphabet, which is extensive.” (No kidding!) In fact, the authors estimate that over a billion people have benefited from better user experiences via improvements to production models made by Vizier.
- Automated A/B testing of Google web properties: tuning user-interface parameters as well as traffic serving parameters (e.g. “How should the search results returned from Google Maps trade off search-relevance for distance from the user?”)
- Physical design and logistical problems. Details of the cookie optimisation are in section 5.3, and bring out a few interesting details such as the ability to mark a given trial as infeasible.
Vizier design goals and user interface
Vizier is designed to operate at large scale (it’s Google!) and to be easy to use, requiring minimal user configuration and setup. It operates as a service with a minimal RPC interface (there are dashboards etc., too of course).
Users provide a study configuration which specifies the set of parameters in the search space, along with the feasible sets for each. Parameter types can be doubles, integers, discrete, or categorical. Vizier takes care of normalisation behind the scenes. With that, you’re off to the races. A typical usage of Vizier looks like this:

The most important operations in the Vizier interface are:
- CreateStudy, which which we’ve just seen.
- SuggestTrials, which kicks off a background process to generate a set of suggested trials to be run.
- AddMeasurementToTrial, which allows clients to provide intermediate metrics during the evaluation of a trial (used by automated stopping rules)
- CompleteTrial, which changes a trial’s status to completed and provides the objective value
- ShouldTrialStop – kicks off a background process to figure out whether a trial should be stopped early.
Sophisticated end users can plug in their own algorithms via the Vizier “playground.”
The web dashboard can be used to monitor and interact with Vizier studies. Common use cases are tracking progress, interactive visualisations, study management (CRUD), requesting new suggestions, early stopping and so on.
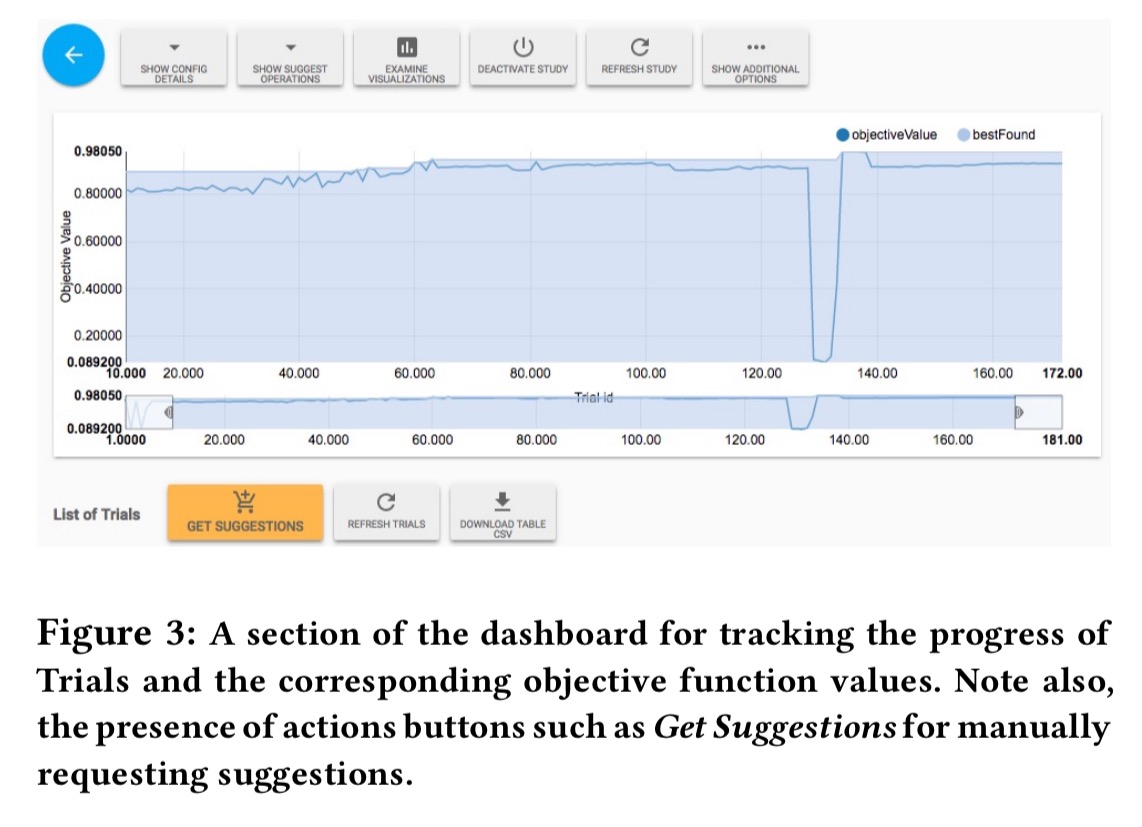
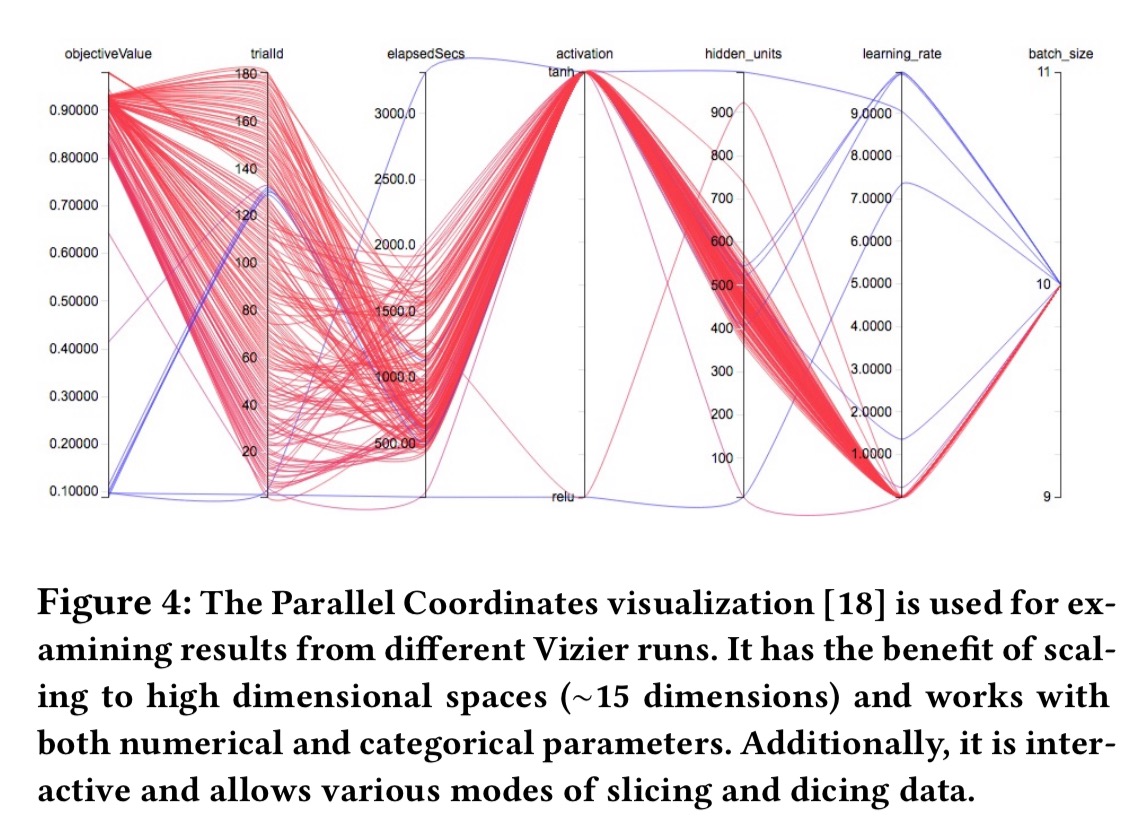
The interactive visualisations are based on the Parallel coordinates visualisation technique.
Vizier on the inside
The Vizier suggestion service is partitioned across multiple Google datacenters.
Each instance of the suggestion service potentially can generate suggestions for several Studies in parallel, giving us a massively scalable suggestion infrastructure.
For studies under 1000 trials, Vizier defaults to using Batched Gaussian Process Bandits. For studies with tens of thousands of trials or more RandomSearch and GridSearch are support as first-class choices, and many other published algorithms can be used through the playground. Data normalisation is handled before trials are presented to the trial suggestion algorithms, and its suggestions are transparently mapped back to the user-specified scaling.
In some important applications of black–box optimization, information related to the performance of a trial may become available during trial evaluation. Perhaps the best example of such a performance curve occurs when tuning machine learning hyperparameters for models trained progressively (e.g., via some version of stochastic gradient descent). In this case, the model typically becomes more accurate as it trains on more data, and the accuracy of the model is available at the end of each training epoch.
In these cases, Vizier supports automated early stopping using one of two rules: a performance curve stopping rule, and a median stopping rule. (The paper makes no mention of guidance given to users or suitability of early stopping in the A/B test use case). The performance curve stopping rule uses regression on performance curves to make a prediction of the final objective value of a trial. The median stopping rules stops a pending trial if its best objective value is strictly worse than the median value of the running averages of all completed trials’ objectives.
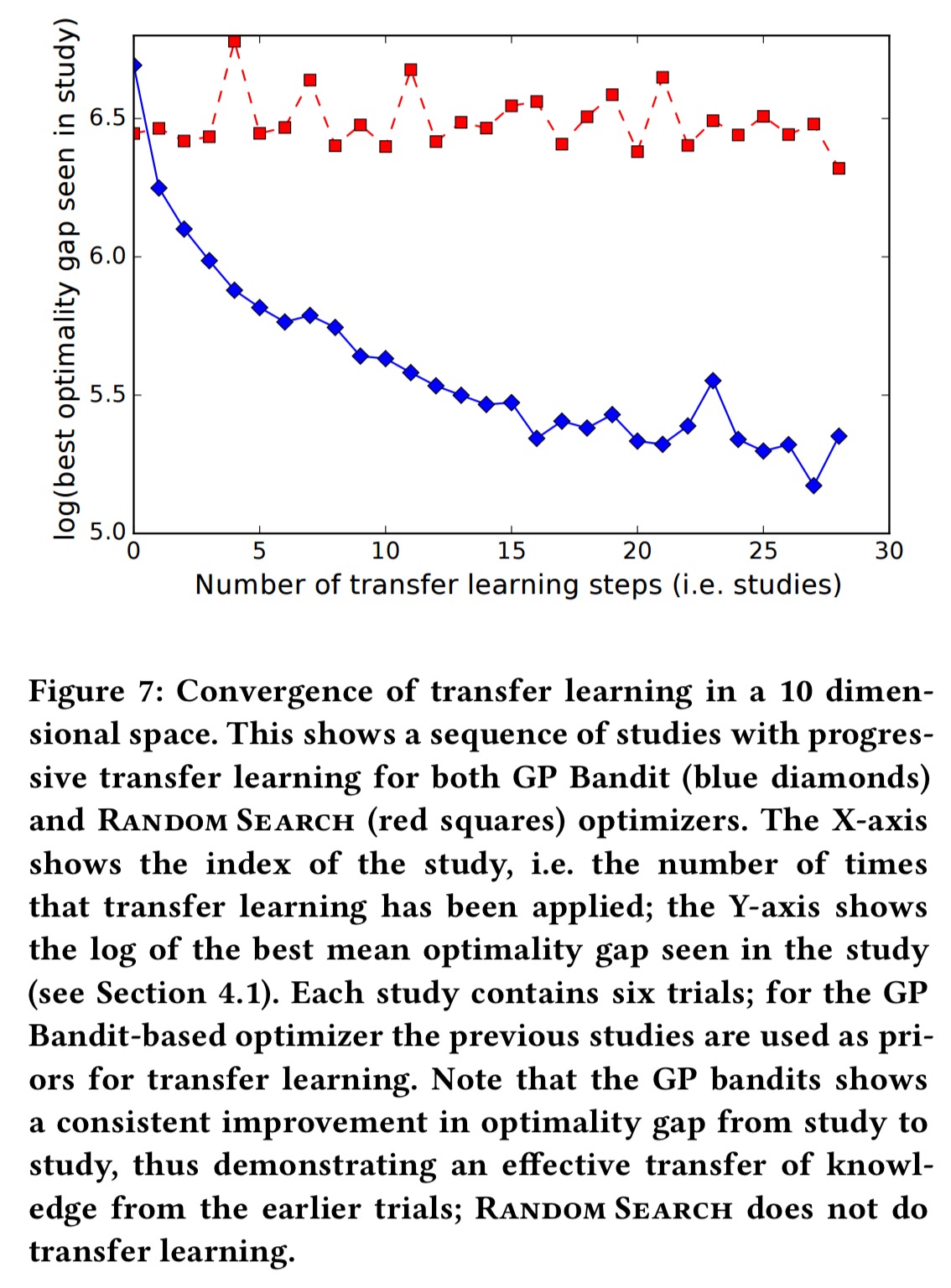
Vizier also supports transfer learning, using outcomes of previous optimisations to inform future ones:
… our strategy is to build a stack of Gaussian Process regressors, where each regressor is associated with a study, and where each level is trained on the residuals relative to the regressor below it. Our model is that the studies were performed in a linear sequence, each study using the studies before it as priors.
Consider as an example a production machine learning system that is expensive to train, so the number of trials that can be run for hyperparameter tuning is limited. However, the system may be worked on year after year:
Over time, the total number of trials spanning several small hyperparameter tuning runs can be quite informative. Our transfer learning scheme is particularly well-suited to this case.
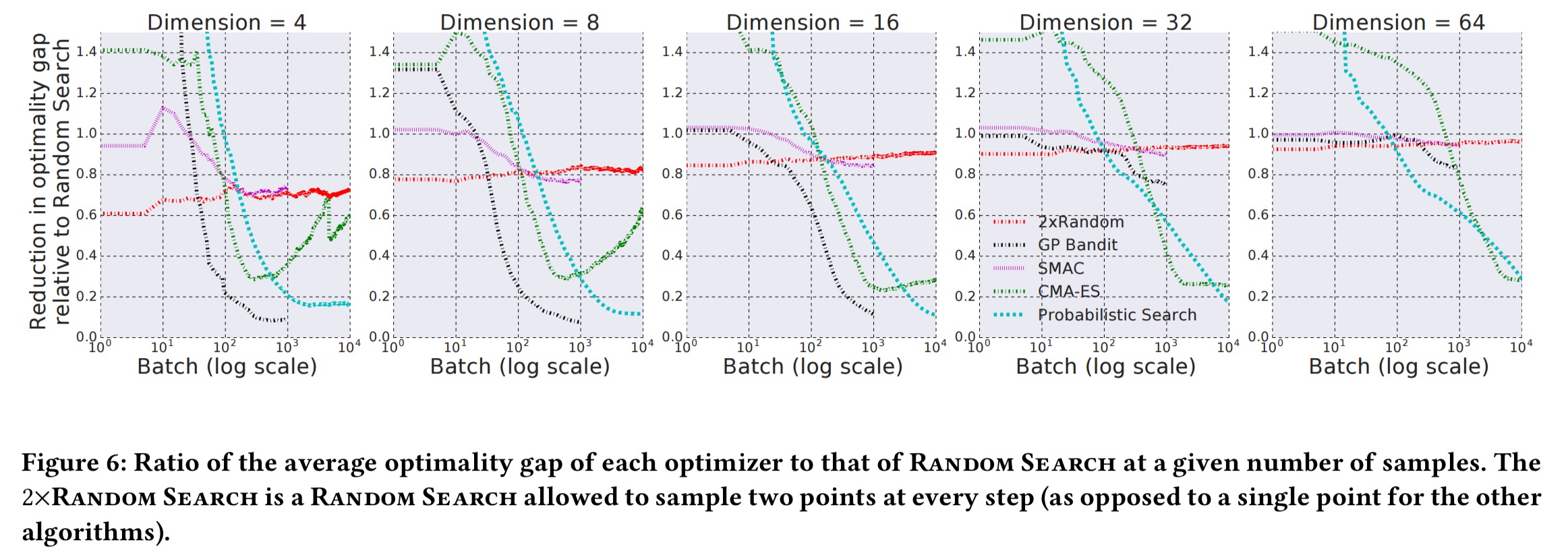
How well does Vizier work?
Section 4 in the paper provides brief evaluation details. Here we can see the effectiveness of the default GP Bandit algorithm compared against a baseline of random search and a number of other search algorithms:
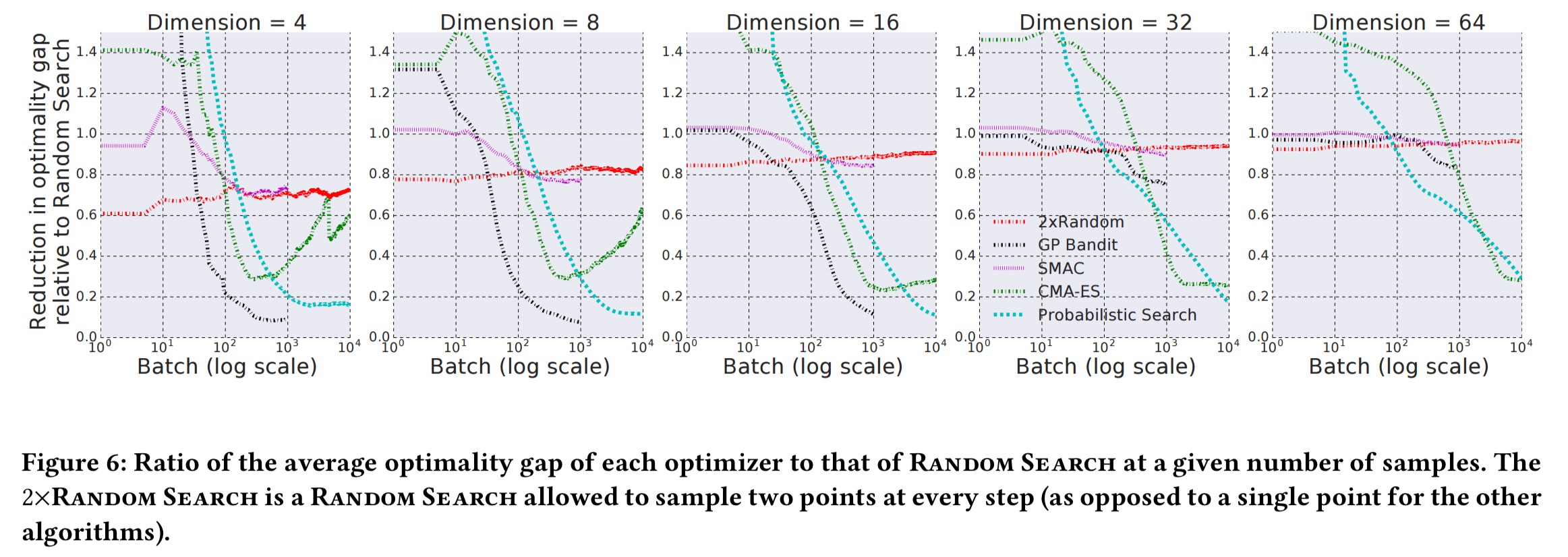 (Enlarge).
(Enlarge).
And here we see the benefits of transfer learning over time:

{kind=link}
Reblogged this on #ai #ml #big #better #data #retail #sales #marketing #innovation #newfutureishere plz use me ref: for +GrowByData vacancies: Email: inquiries@growbydata.com For more details visit: http://www.growbydata.com/career-overview.php and commented:
Black-box optimization is the task of optimizing an objective function f : X \rightarrow \mathbb{R} with a limited budget for evaluations. The adjective “black-box” means that while we can evaluate f(x) for any x \in X, we have no access to any other information about f, such as gradients or the Hessian.