TFX: A TensorFlow-based production scale machine learning platform Baylor et al., KDD’17
What world-class looks like in online product and service development has been undergoing quite the revolution over the last few years. The series of papers we’ve been looking at recently can help you to understand where the bar is (it will have moved on again by the time most companies get there of course!).
- The new baseline: so far you’ve embraced automated testing, continuous integration, continuous delivery, perhaps continuous deployment, and you have the sophistication to rollout new changes in a gradual manner, monitor behaviour, and stop or rollback when a problem is detected.
- On top of this you’ve put in place a sophisticated metrics system and a continuous experimentation platform.
- Due to the increasing complexity of systems, you might also need to extend this to a general purpose black-box optimization platform.
- But you’re still not done yet! All those machine learning models you’ve been optimising need to be trained, validated and served somehow. You need a machine learning platform. That’s the topic of today’s paper choice, which describes the machine learning platform inside Google, TFX.
(In a similar manner, if anyone knows of a good paper capturing at a high level what a state-of-the-art security platform looks like, please let me know).
Just to be clear here, I’m not saying you necessarily need to build your own versions of all of these platforms. It’s more about embracing their use as part of your everyday practices, and if you can do that by renting then for many organisations that’s going to be the best choice.
Why do I need a machine learning platform?
The code that implements your machine learning model is only a tiny part of what goes into using machine learning in production systems. We looked at some of the lessons learned in deploying machine learning at scale previously in ‘Machine learning: the high-interest credit-card of technical debt.’ Data needs to be transformed and validated, model validation needs to be coupled with data validation so that bad (yet validated) models don’t reach production, and you need a scalable serving infrastructure. The key components of a machine learning platform (TFX) are illustrated in the figure below:
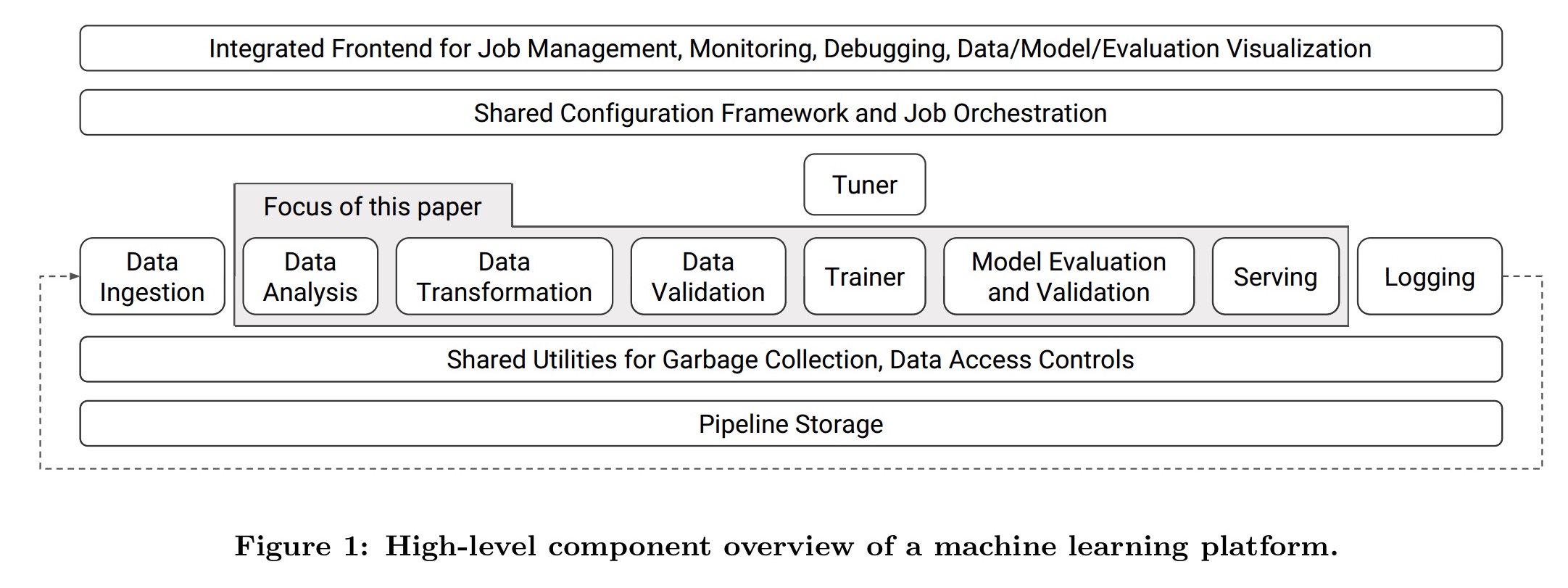
Our platform provides implementations of these components that encode best practices observed in many production pipelines… by integrating the aforementioned components into one platform, we were able to standardize the components, simplify the platform configuration, and reduce the time to production from the order of months to weeks, while providing platform stability that minimizes disruptions.
(Emphasis mine).
Data analysis, transformation, and validation
You’re only as good as your data. Capturing data anomalies early before they propagate downstream saves a lot of wasted time later on.
Small bugs in the data can significantly degrade model quality over a period of time in a way that is hard to detect and diagnose (unlike catastrophic bugs that cause spectacular failures and are thus easy to track down), so constant data vigilance should be a part of any long running development of a machine learning platform.
To establish a baseline and monitor for changes, TFX generates a set of descriptive statistics for each dataset fed to the system. These include feature presence and values, cross-feature statistics, and configurable slices. These statistics need to be computed efficiently at scale and can be expensive to compute exactly on large training data. In this case, distributed streaming algorithms giving approximate results can be used.
TFX also includes a suite of data transformations supporting feature wrangling. As an example, TFX can generate feature-to-integer mappings, known as vocabularies. It’s easy to mess things up when transformations differ in subtle ways between training and serving. TFX automatically exports any data transformations as part of the trained model to help avoid these issues.
To perform validation, TFX relies on a schema providing a versioned description of the expected data. The schema describes features and their expected types, valency, and domain. TFX can help users to generate the first version of their schema automatically.
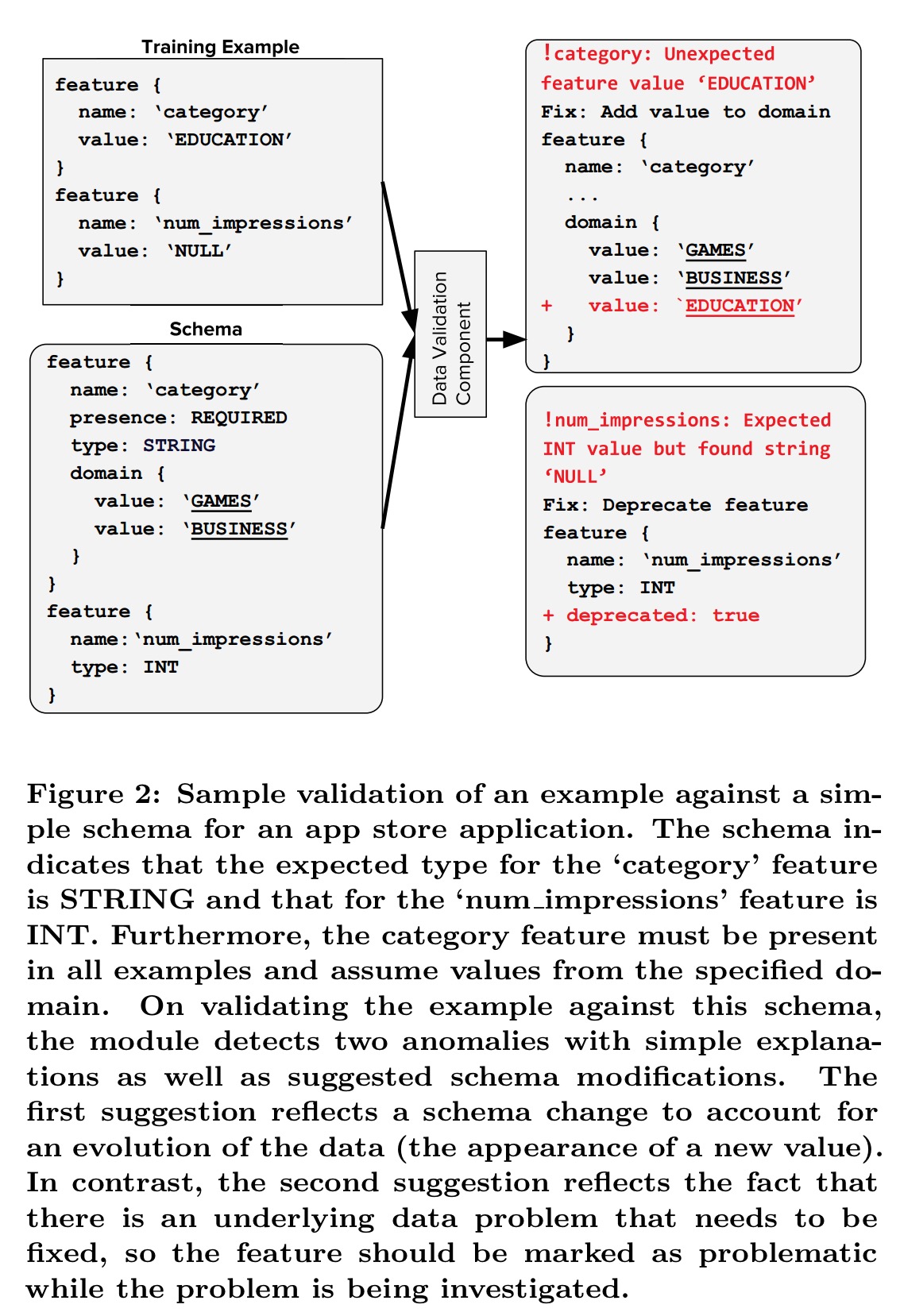
TFX takes care to provide useful and informative anomaly alerts so that users don’t become blind to them.
We want the user to treat data errors with the same rigor and care that they deal with bugs in code. To promote this practice, we allow anomalies to be filed just like any software bug where they are documented, tracked, and eventually resolved.
Training
Once your modelling code (written in TensorFlow of course) is integrated with TFX, you can easily switch learning algorithms. Continuously training and exporting machine learning models is a common production use case, yet in many scenarios it is too time and resource intensive to retrain models from scratch each time.
For many production use cases, freshness of machine learning model is critical… A lot of such use cases also have huge training sets (O(100B) data points) which may take hours (or days in some cases) of training… This results in a trade-off between model quality and model freshness. Warm-starting is a practical technique to offset this trade-off and, when used correctly, can result in models of the same quality as one would obtain after training for many hours, in much less time and fewer resources.
Warm starting is built into TFX, and the ability to selectively warm-start features of a network has been implemented and open-sourced in TensorFlow. When training a new version of a network using warm starting, the parameters corresponding to warm-start features are initialised from a previously trained version of the model, and fine tuning begins from there.
Evaluation and validation
TFX contains a model evaluation and validation component designed to ensure that models are ‘good’ before serving them to users.
Machine-learned models are often parts of complex systems comprising a large number of data sources and interacting components, which are commonly entangled together. This creates large surfaces on which bugs can grow and unexpected interactions can develop, potentially to the detriment of end-user experiences via the degradation of the machine-learned model.
How are new models rolled out to production? Via A/B testing of course! Models are first evaluated on held-out data to determine if they are promising enough to start a live test, with TFX providing proxy metrics that can approximate business metrics. For models that pass this test, teams progress to product-specific A/B experiments to determine how the models actually perform on live traffic and relevant business metrics.
Once a model is launched to production and is continuously being updated, automated validation is used to ensure thatthe updated models are good. We validate that a model is safe to serve with a simple canary process. We evaluate prediction quality by comparing the model quality against a fixed threshold as well as against a baseline model (e.g., the current production model).
If a model update fails validation it is not pushed to serving, and an alert is generated for the owning product team. Initially teams weren’t sure whether they needed or wanted the validation functionality, but after encountering real issues in production which validation could have prevented, they all of a sudden became very keen to switch it on!
Serving
TensorFlow Serving provides a complete serving solution for machine-learned models to be deployed to production environments. Production serving needs, among other things, low-latency and high efficiency. For most models a common TensorFlow data format is used, but for data intensive (vs CPU intensive) networks such as linear models a specialized protocol buffer parser was built with lazy parsing.
While implementing this system, extreme care was taken to minimize data copying. This was especially challenging for sparse data configurations. The application of the specialized protocol buffer parser resulted in a speedup of 2-5 times on benchmarked datasets.
TFX and Google Play
One of the first teams within Google to move onto the TFX platform was Google Play, who use it for their recommender system. This system recommends relevant Android apps to Play app users when they visit the store homepage. The training dataset has hundreds of billions of examples, and in production the system must handle thousands of queries per second with strict latency requirements (tens of milliseconds).
As we moved the Google Play ranking system from its previous version to TFX, we saw an increased velocity of iterating on new experiments, reduced technical debt, and improved model quality.
Next step: explanations?
… as machine learning becomes more prevalent, there is a strong need for understandability, where a model can explain its decision and actions to users [and a legal requirement in many cases with new legislation such as GDPR – AC]. We believe the lessons we learned from deploying TFX provide a basis for building an interactive platform that provides deeper insights to users.

Reblogged this on #ai #ml #big #better #data #retail #sales #marketing #innovation #newfutureishere plz use me ref: for +GrowByData vacancies: Email: inquiries@growbydata.com For more details visit: http://www.growbydata.com/career-overview.php and commented:
TFX: A TensorFlow-based production scale machine learning platform