Beyond the words: predicting user personality from heterogeneous information Wei et al., WSDM 2017
Here’s a very topical paper! You may have seen the recent Motherboard piece, “The data that turned the world upside down,” describing how personality profiling was used to provide tailored messages to voters in the recent American elections. In the interest of balance, here’s the less widely read counterpoint: “The myth that British data scientists won the election for Trump.” In today’s paper, Wei et al. look at the how to generate more accurate personality profiles (underpinned by the same OCEAN model) by combining data from a variety of sources: words used in social media posts, use of emoticons, the avatars that users chose for themselves, and how users respond to posts/tweets in their timelines. The good news is that they’re not trying to use their improved method as a Weapon of Mass Manipulation to influence who gets to hold one of most powerful offices in the world. Instead they suggest personality knowledge can be exploited in good old e-commerce too!
Taking insurance companies as an example, it is easier to persuade users positive in agreeableness to buy their insurance. By comparison, users negative in agreeableness are less likely to accept the promotion.
The authors also build a chatbot, DiPsy, that uses background analysis of Weibo and WeChat account data (the user gives permission during the onboarding process) combined with conversational interactions to refine a personality profile of the user.
Currently, DiPsy serves as a personalized chatbot to evaluate user personality. Due to the wide use of personality in mental health examination, we hope to build DiPsy as a digital psychologist to diagnose, and treat users’ mental process through digital footprints and natural conversations in the near future. By determining users’mental status, DiPsy is able to conduct cognitive behavioral therapy (CBT) or early intervention to help at-risk users alleviate/manage their problems by changing the way they think and behave in a variety of therapeutic contexts.
So, used in an individual context and with explicit consent, automated personality profiling may be a useful tool. Used at large scale to automatically profile people based on public information (i.e. without explicit consent) and target messaging for them feels quite different. If you can’t buy personality-profile enriched consumer datasets in the data market yet (I didn’t go looking), I’m confident it’s only a matter of time…
Anyway, let’s get back to looking at the technology, which is what you probably came here for! There’s prior art in looking at the words people use to try and predict personality, but not much exploration of what else in our ‘digital traces’ much be useful to that end.
With the rise of web and social media, individuals are generating considerable digital traces besides users’ language features. Currently, the sequential text data in users’ social media contents are utilized for predicting user preferences and characteristics. However, to the best of our knowledge, there has been little exploration of how to predict user personality by leveraging the heterogeneous information embedded in these digital traces.
For personality profiling the “Big Five” OCEAN model is used, which scores people on attributes of Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. Using data collected from thousands of volunteers alongside ‘ground truth’ personality profiles of them collected using traditional questionnaire techniques, the authors discovered that there is indeed personality signal not just in the words we use in our tweets, but also in our use of emoticons, our selection of avatars, and the way we respond to messages in our timelines. For example, users that score highly in Agreeableness tend to use more smileys, and users that score highly in Neuroticism use more theatrical emoticons to exaggerate their emotions:

And here’s what your choice of avatar may be revealing about you:

The personality prediction model, which uses an ensemble of different methods, is designed to classify users that are biased towards either extreme positivity or negativity in one or more of the Big Five attributes, since this information and these users are most valuable for targeting.
Use too many 😀😀😀 smileys in your tweets and you’ll be pushing up your Agreeableness score, which could increase your chances of being targeted by advertising 🤔!
Each of the four basic inputs (tweet text, avatars, emoticons, and response patterns) are fed into their own classifiers which are then combined using a stacked generalization-based ensemble to give the final Big Five personality prediction for a user. The resulting system is called HIE, for Heterogeneous Information Ensemble.
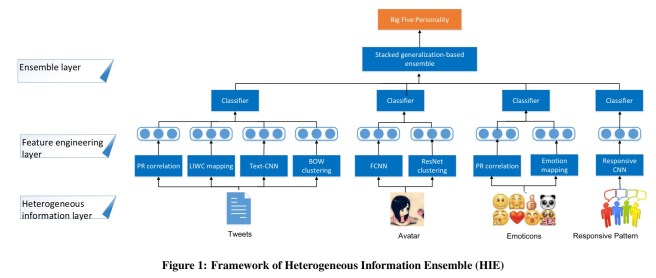
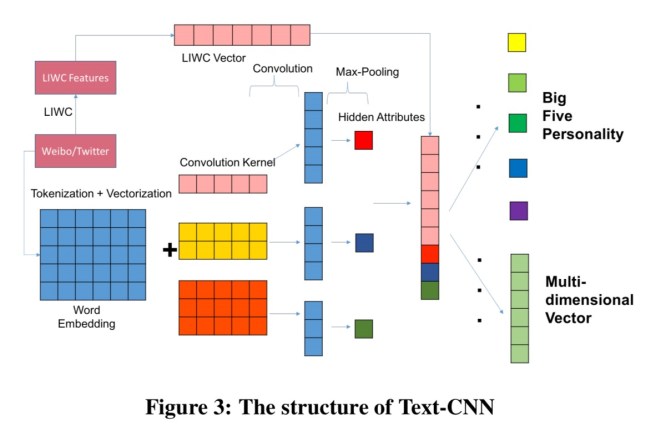
Predicting personality from tweets
Tweet features for input to the classifier are engineered in four ways:
- Classic LIWC (Linguistic Inquiry and Word Count), the state-of-the-art lexicon based method
- Pearson correlation. For each of the OCEAN dimensions, the Pearson correlation between each word and the targeted personality is determined, and the resulting top 2000 words are used to assist personality prediction.
- A bag-of-words approach which compensates for “LIWC’s limited capability to represent user’s linguistic patterns in short and informal texts” (i.e., tweets). The top 1,500 (Chinese) words and all punctuation are put in the bag. K-means clustering is then used to cluster the bag-of-words formatted data, and the number of items within each cluster (one cluster per trait) is used as the representation of the user.
- A deep CNN model tuned for text:
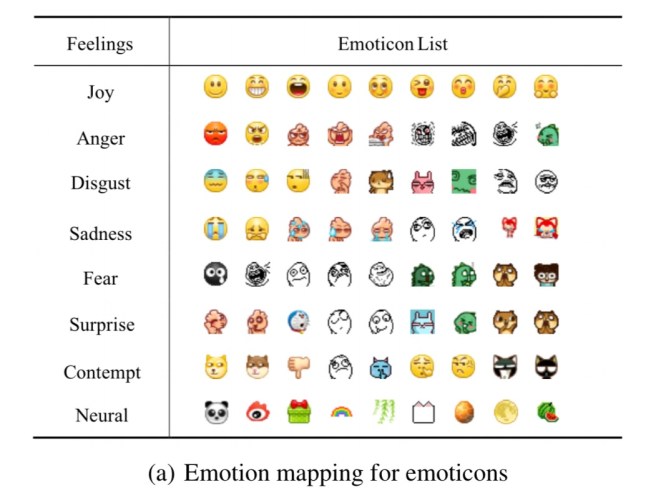
Predicting personality from emoticons
The two emoticon strategies are Pearson correlation and emotion mapping. For Pearson correlation, the analysis is based on the top 50 emoticons that are strongly correlated with user personality. For emotion mapping, the 495 different types of emoticons are mapped into 8-dimension vectors, representing 8 different emotions drawn from Ekman’s emotion atlas.
Predicting personality from avatars
Avatar features are engineered through two model routes: a deep fully connected network and k-means clustering. Both make use of ResNets (Residual Networks, not the networks you find on college campuses!) to encode avatar images into 256-dimensional vectors.
… there are some interesting findings in the usage of avatars and emoticons. For instance, introverts tend to cover their face or show side face. Users high in Openness are more likely to use avatars with their friends, while users low in Openness prefer avatars with themselves only.
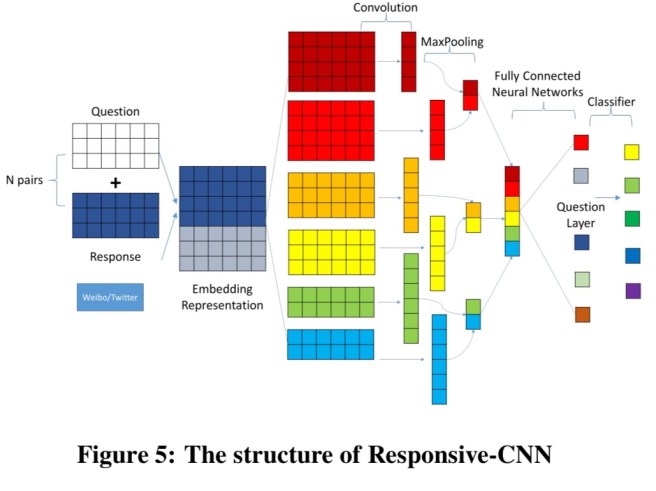
Predicting personality from response patterns
We emphasize great importance on the responsive pattern. In psychology studies, it is believed that different reactions to the
same scenarios during interaction reflect differences in user personality.
Each tweet is embedded into a vector by taking an average over word vectors for the words in the tweets (this simple scheme outperformed more complex approaches such as using RNNs). This is then combined with question-answer (tweet/retweet) vectors encoding the following interaction scenarios:
- A user tweets a message and his/her fans or followers comment on it
- A user retweets someone else’s message
- A user comments on someone else’s message
Overall HIE prediction accuracy
Here’s a look at how well HIE does (when using just tweets and avatars) compared to the state-of-art IBM Watson Personality Insights algorithm and the Mypersonality Facebook application algorithm:
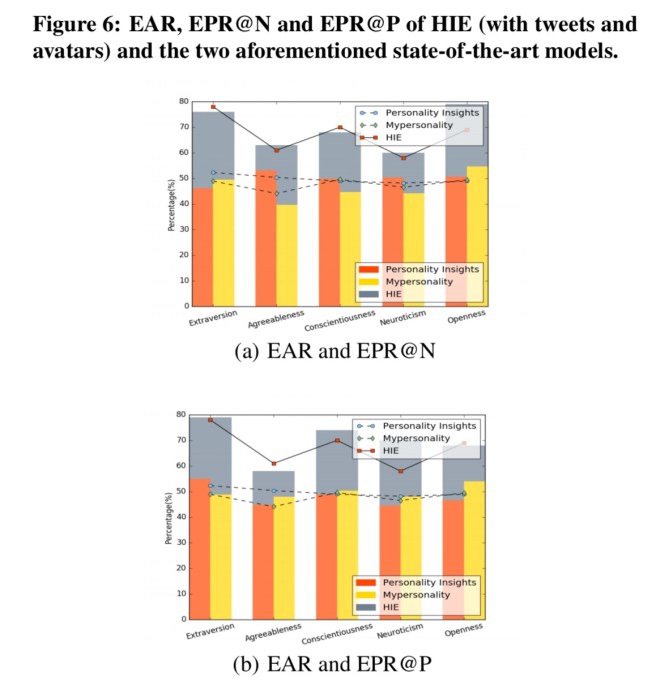
Here EAR stands for Extreme Accuracy Rate, and is the precision score for predicted extreme users (positive or negative). EPR@P is the precision score for predicted positive extreme users, and EPR@N is the precision score for predicted negative extreme users.
Due to the demands for personalized services, reliability of predicted results is more important than detecting all potential individuals in a specific personality category. HIE perfectly meets this need of real-world usage. Depicted in Table 7.3.3 (below), we notice that users with high probability scores are aggregated in the two ends of the confidence interval. Moreover, users with extremely low scores are on the left end while users with extremely high scores are on the right end. It shows the ability of HIE to accurately distinguish the targeted extreme users from the others.
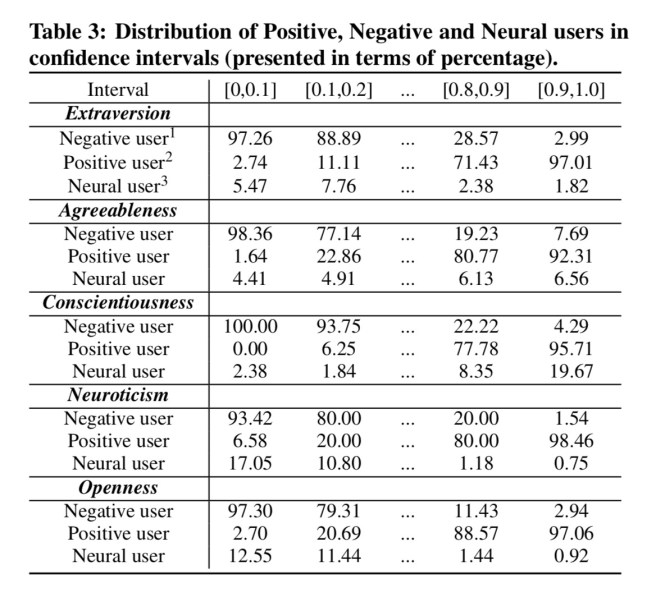
(I think the ‘neural’ users are also ‘neutral’ ;) ).

6 thoughts on “Beyond the words: predicting user personality from heterogeneous information”
Comments are closed.