Information flow reveals prediction limits in online social activity Bagrow et al., arVix 2017
If I know your friends, then I know a lot about you!
Suppose you don’t personally use a given app/service, and so the provider doesn’t have data on you directly. However, many of your friends do use the app/service, and there’s a way for the provider to find out about the friendship relationship (e.g., you’re in your friends’ contacts). Bagrow et al. study just how much the provider can now infer about you, even without any direct data and of course without any consent on your part. And it turns out that they can infer a lot!
…we estimate that approximately 95% of the potential predictive accuracy attainable for an individual is available within the social ties of that individual only, without requiring the individual’s data.
In other words, whenever you consent to share some of your data with an app or service, and that consent also includes access to your contacts, or social relationship graph, you should also assume that you are consenting to leak some private information about your friends too. Would they give consent?? As we’ve seen with the recent Cambridge Analytics revelations, this can be a very powerful way for a data collector to dramatically grow their set of profiles.
There’s a long-standing saying, “if you’re not paying, you’re not the customer; you’re the product.” While the general public is only just awakening to what that really means, here in 2018 I think we can add couple of additional clauses:
- If you’re paying, and the provider doesn’t have a clear and explicit privacy policy, you’re both the customer and the product.
- If enough of your friends are part of the product, then you’re the product too.
The actual context for this study is the prediction of the words in tweets, based on a dataset of 927 Twitter users, and the 15 most frequent Twitter contacts of each. So strictly we can only say that with just your friends we have 95% of the predictive power over what you’re going to say. But of course, companies learn all sorts of things from your profile (e.g. demographic information). See this post from last year on The Morning Paper, ‘Beyond the words, predicting user personality from heterogeneous information,’ for an example of how your personality can be inferred and then used to manipulate you. I would be very surprised if the ability to infer information about you from your friends did not also extend to these other forms.
Tweets, egos, and alters
For each of the 927 Twitter users (the egos) in the study, all of their public posts (up to a limit of the most recent 3200) were retrieved. From these, the 15 most frequent Twitter contacts (the alters) of each user were determined, and their posts were downloaded as well.
Predicting the written word
The ability to accurately profile and predict individuals is reflected in the predictability of their written text. The predictive information contained within a user’s text can be characterized by three quantities: the entropy rate,
, the perplexity
, and the predictability,
.
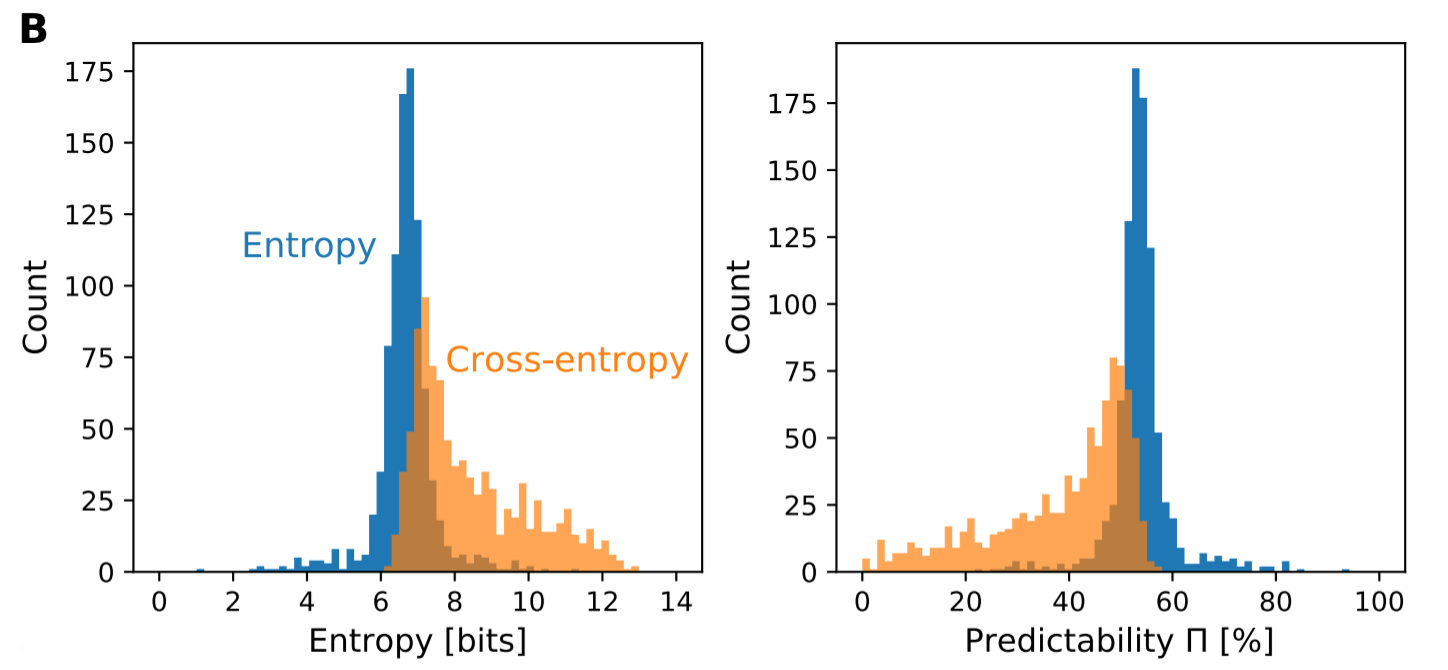
The entropy rate captures the average uncertainty you have about future words, given the text you have already seen. It tells you how many bits h are needed on average to express subsequent words giving the preceding text. Higher entropies equate to less predictable text.
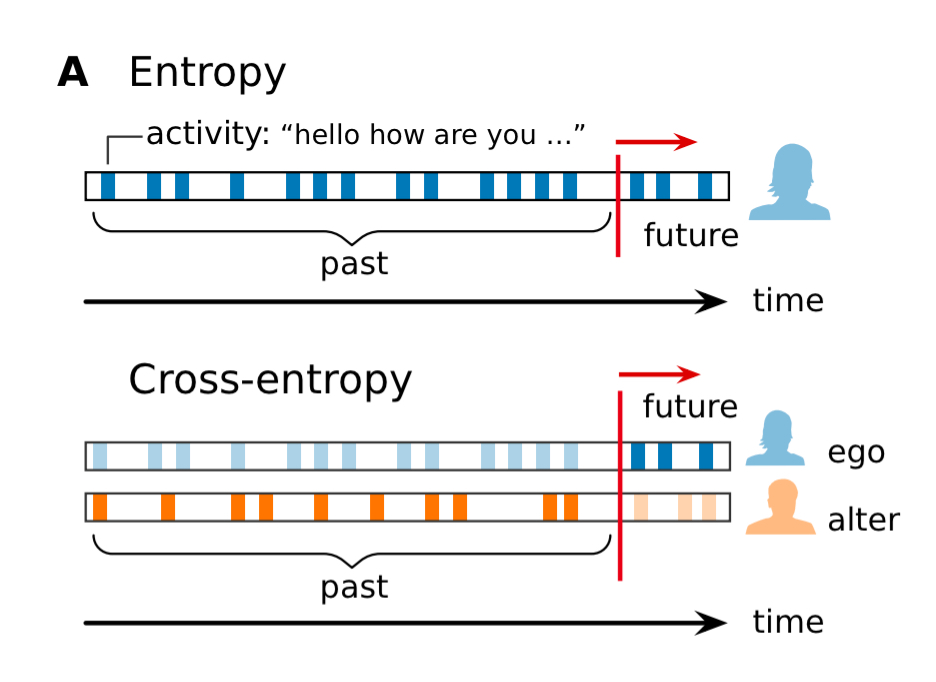
This study looks at entropy rates for an ego (i.e., given the past text tweeted by a user, how well can you predict what comes next), and also cross-entropy rates. With cross-entropy, we are interested in how well you can predict what word comes next for an ego, given only the past texts of an alter).
Perplexity is just another way of expressing the same thing. It tells us that the remaining uncertainty about unseen words is equivalent to choosing uniformly at random from
The predictability,
From alters to egos
If there is consistent, predictive information in the alter’s past about the ego’s future, especially beyond the information available in the ego’s own past, then there is evidence of information flow.
If the cross-entropy (prediction of an ego’s next words using the past text of an alter) is greater than the entropy (prediction using an ego’s own past words) then the increase tells us how much information we lose by only having access to the alter’s information instead of the ego’s.
Here are the results when looking at the egos and the most frequently contacted alter of each (i.e, we’re predicting based on only one ‘friend’). We see a diversity of social relationships: sometimes the ego is well-informed (influenced?) by the alter, while at other times the alter-ego pairs exhibit little information flow.
Things get more interesting when you combine information from multiple alters to try and predict and the future of an ego. First we generalise the notion of cross-entropy to include the combined pasts of multiple alters:
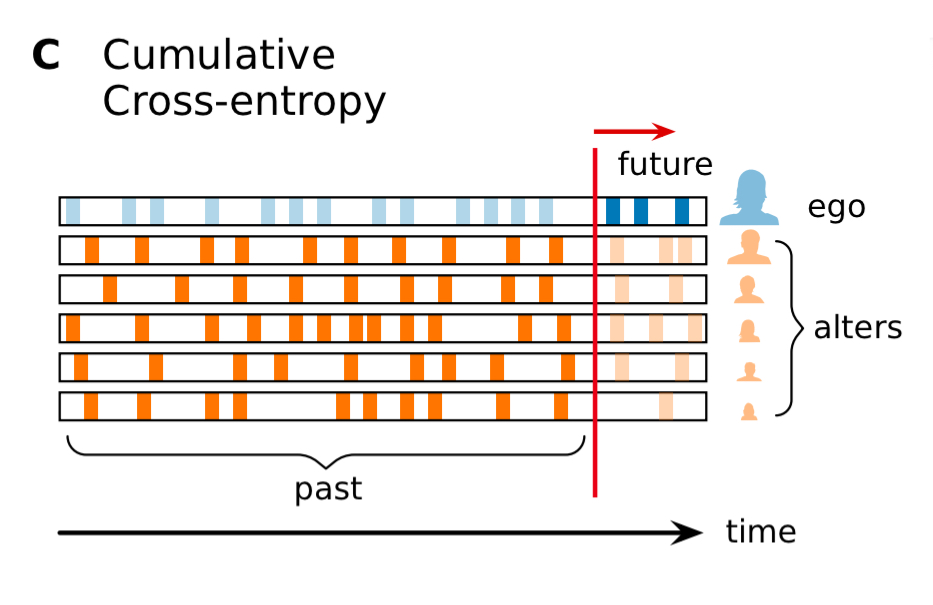
Then we can study how cross-entropy and predictability changes as we add more alters:
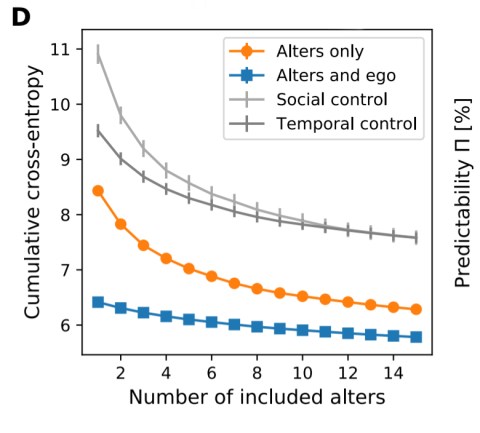
The results show that with enough friends (8-9), you can predict the ego without access to any of the ego’s own data, better than if you did have the ego’s own data, but not that of their alters.
> As more alters were considered, cross-entropy decreased and predictability increased, which is sensible as more potential information is available. Interestingly, with 8-9 alters, we observed a predictability of the ego given the alters at or above the original predictability of the ego alone. As more alters were added, up to our data limit of 15 alters, this increase continued. Paradoxically, this indicated that there is potentially more information about the ego within the total set of alters than within the ego itself. (Emphasis mine) .
Even when the past data of the ego is made available, predictability of the ego still improves as more alters are added (by around 6.9% with 15 alters). That is, the alters and ego is best of all if you can get it, but the alters still add significant information even if you do have the data of the ego. It looks like the saturation point for predictive information is around 61% with alters only, and 64% with alters and ego.
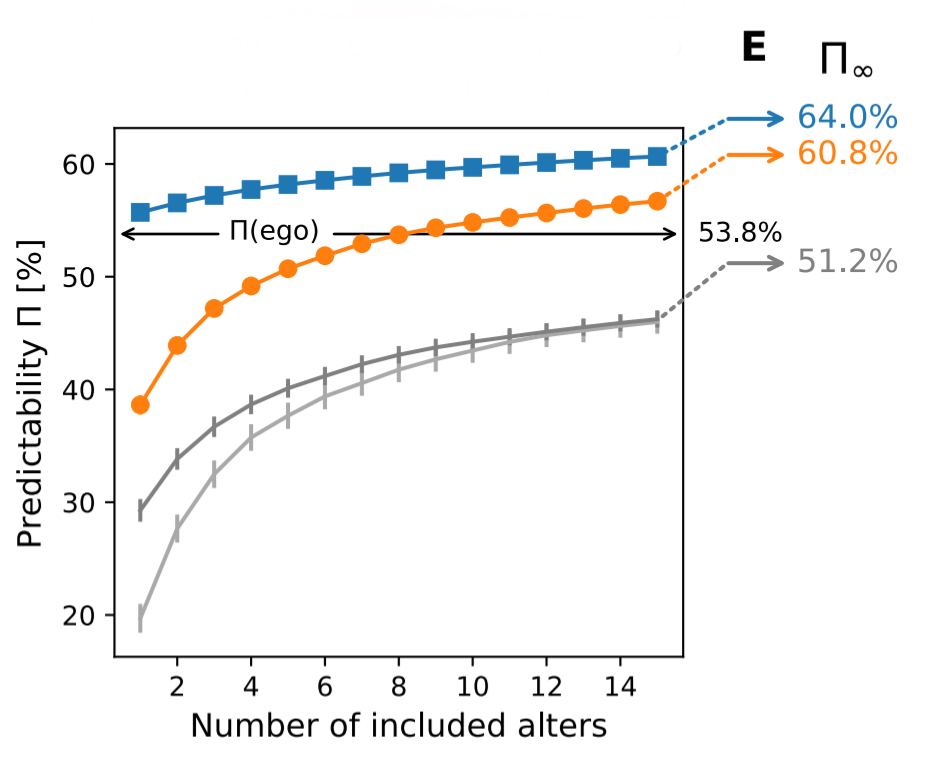
> This may have distinct implications for privacy: if an individual forgoes using a social media platform or deletes her account, yet her social ties remain, then than platform owner potentially possesses 95.1% ± 3.36% of the achievable predictive accuracy of the future activities of that individual.
Controls
Two control tests were done to eliminate confounding factors. The first control (social control) used random pairs of alters and egos (i.e., not a true alter of the ego) to test for predictive information simply from the structure of English. The second control (temporal control) made pseudo-alters for an ego by assembling a random set of posts made at approximately the same time as the real alter’s posts. This tests for egos and alters independently discussing the same events (e.g., current events).
The real alters provided more social information than either control.
Influence follows information flow
Egos who posted 8 times per day on average were approximately 17% more predictable given their alters than egos who posted once per day on average. This trend reverses when considering the activity levels of the alters: highly active alters tended to inhibit information flow, perhaps due to covering too many topics of low relevance to the ego.
Alters with more social ties provided less predictive information about their egos than alters with fewer ties… this decreasing trend belies the power of hubs in many ways: while hubs strongly connect a social network topologically, limited time and divided attention across their social ties bounds the alter’s ability to participate in information dynamics mediated by the social network and this is reflected in the predictability.
Directionality of contact matters too. Egos are more predictable given an alter when that alter frequently contacts the ego. But there is little change in predictability when the ego mentions the alter more or less frequently.
The bottom line
…the ability to repeatedly and accurately predict the text of individuals provides considerable value to the providers of social media, allowing them to develop profiles to identify and track individuals and even manipulate information exposure. That information is so strongly embedded socially underscores the power of the social network: by knowing who are the social ties of an individual and what are the activities of those ties, our results show that one can in principle accurately profile even those individuals who are not present in the data.
For a very sobering example of the extent to which friend information is harvested, see this twitter thread and accompanying discussion on HN. I’m one of those people who have never had a Facebook account. I’m under no illusions that Facebook doesn’t have a profile of me though.

Fascinating and contextually opportune… wonder how the fallout of triage between Regulation Net Neutrality/Facebook/Cambridge Analytica might impose on such learning algorithms….