FaSST: Fast, scalable and simple distributed transactions with two-sided (RDMA) datagram rpcs Kalia et al., OSDI 2016
Back in January I wrote a short piece entitled ‘All change please’ looking at some of the hardware changes making their way to our datacenters and the implications. One of those changes is super-fast networking (as exploited by e.g., the NOPaxos paper we looked at last week). As we approach the end of the year, it seems fitting to revisit that topic with FaSST…
… recent systems have shown that transactions can be fast in the datacenter. The key enablers are high-speed networks and lightweight network stacks (i.e., kernel bypass). In addition these systems exploit Remote Direct Memory Access (RDMA) for its low latency and CPU efficiency.
As the saying goes, “there are two sides to every argument.” But there aren’t two sides to every RDMA call, as RDMA also offers a super-fast ‘one-sided’ call which completely bypasses the remote CPU. RDMA actually offers three different modes of communication:
- One-sided RDMA (CPU bypass) which provides read, write, and two atomic operations fetch_and_add, and compare_and_swap.
- An MPI interface with SEND/RECV verbs, and
- An IP emulation mode that enables socket-based code to be used unmodified
Some of the systems that blew my mind in this space include FaRM, DrTM, and RAMCloud. FaRM and DrTM both use one-sided RDMA in an attempt to go as fast as possible. RAMCloud is tuned for ultra-low latency (not throughput) and actually doesn’t use one-sided RDMA, instead preferring RPC style communication which in their benchmarks came out better when multiple one-sided calls would otherwise be needed.
FaSST targets high-speed, low-latency key-value transaction processing with throughputs of several million transactions/sec and average latencies around one hundred microseconds on common OLTP benchmarks with short transactions with up to a few tens of keys. Achieving this performance requires in-memory transaction processing, and fast userspace network I/O with polling (i.e., the overhead of a kernel network stack or interrupts is unacceptable). We assume commercially available network equipment: 10-100Gbps of per-port bandwidth and approx. 2 μs end-to-end latency.
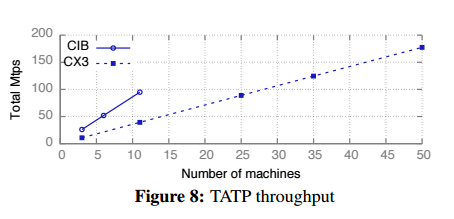
FaSST turns out to be well named! Compared to FaRM, it achieved 3.55M tps per machine in a 50-node cluster on an OLTP benchmark (TATP), whereas FaRM ‘only’ achieves 1.9M tps in the same setting. (And on a more powerful cluster, FaSST achieved 8.7Mtps/machine!). On the Smallbank OLTP benchmark DrTM achieves 0.93M tps/machine, FaSST outperforms it by over 1.68x on an equivalent cluster, and by over 4.5x on a more powerful cluster.

The FaSST experiments were conducted on two different clusters. The ‘CX3’ cluster has Intel SandyBridge CPUs with 8 cores and ConnectX-3 NICs, configurations up to 69 nodes were used in the experiments. The ‘CIB’ cluster has 11 nodes with a more powerful Connect-IB NIC with 2x more bandwidth and around 4x higher message rate. This cluster also uses more powerful 14-core Intel Haswell CPUs.
Say you wanted to do 100M tps, you can get there with just over 11 nodes in CIB.
What’s the secret to FaSST’s great performance? Not using one-sided RDMA! The authors show that even though one-sided RDMA looks like the theoretically fastest option, when matched to the needs of transactional applications it’s not such a good fit, and an RPC-based approach can fare better.
A key contribution of this work is FaSST RPCs: an all-to-all RPC system that is facts, scalable, and CPU-efficient. This is made possible by using RDMA’s datagram transport that provides scalability, and allows “Doorbell batching” which saves CPU cycles by reducing CPU-initiated PCIe bus transactions. We show that FaSST RPCs provide (1) up to 8x higher throughput, and 13.9x high CPU efficiency than FaRM’s RPCs, and (2) 1.7-2.15x higher CPU efficiency, or higher throughput, than one-sided READs, dependent on whether or not the READs scale to clusters with more than a few tens of nodes.
FaSST itself is a (prototype) transaction processing system built on top of FaSST RPCs. Its design is largely inspired by FaRM, so I’m going to concentrate on the FaSST RPC mechanism itself in this write-up.
RDMA background
Current commodity RDMA implementations (e.g., Infiniband, RoCE, iWarp) use the Virtual Interface Architecture (VIA). VIA is connection-oriented, requiring a connection to be made between a pair of virtual interfaces before they are allowed to communicate. A virtual interface is represented by a queue pair (QP) consisting of a send queue and a receive queue. SEND and RECV are two-sided verbs and require the involvement of the CPU at both ends. READ, WRITE, and ATOMIC are one-side verbs and bypass the remote CPU to operate directly on remote memory.
RDMA transports can be connected or connectionless. Connected transports offer one-to-one communication between two queue pairs: to communicate with N remote machines, a thread must create N QPs. These transports provide one-sided RDMA and end-to-end reliability, but do not scale well to large clusters. This is because NICs have limited memory to cache QP state, and exceeding the size of this state by using too many QPs causes cache thrashing. Connectionless (datagram) transports are extensions to the connection-oriented VIA, and support fewer features than connected transports: they do not provide one-sided RDMA or end-to-end reliability. However, they allow a QP to communicate with multiple other QPs, and have better scalability than connected transports as only one QP is needed per thread.
Current RDMA implementations offer three main transports: reliable connected (RC), unreliable connected (UC), and unreliable datagram (UD). Only connected transports provided one-sided verbs.

The tortoise and the hare
How a slower communication primitive ends up being faster…
RPCs use more CPU and are slower than one-sided RDMA operations, yet it turns out that in the context of an overall system they can be faster, simpler, and more scalable.
Let’s talk about speed and simplicity first, and then come back to scalability.
Although READs can outperform similarly-sized RPCs on small clusters, RPCs perform better when accounting for the amplification in size or number of READs required to access real data stores.
The point is, it can be hard to do everything you need in a transactional system with a single READ, but once you get beyond a small number of READS, an RPC mechanism can be quicker (the RAMCloud team reached the same conclusion).
RPCs allow access to partitioned data stores with two messages: the request and the reply. They do not require message size amplification, multiple round trips, or caching. The simplicity of RPC-based programming reduces the software complexity required to take advantage of modern fast networks in transaction processing: to implement a partitioned, distributed data store, the user writes only short RPC handlers for a single-node data store…
The scalability advantage comes from limits in the NIC’s queue pair cache. The ideal is that a core has exclusive access to a QP (the overhead of sharing can dramatically reduce the per-core throughput, e.g., by 5.4x in experiments conducted by the authors). With a connected transport, N machines, and T threads at each machine we’d need N*T queue pairs at every machine to guarantee exclusive access, which quickly grows to be too many for the NIC. But using the datagram transport it is possible to create one datagram QP that can communicate with all remote cores.
Once you’ve chosen to use RPCs, datagrams offer a second advantage over connected transports in that you can implement Doorbell batching to reduce CPU use:
User processes post operations to the NIC by writing to a per-QP Doorbell register on the NIC over the PCIe bus, specifying the number of new operations on that QP. This write is relatively expensive for the CPU because it requires flushing the write buffers, and using memory barriers for ordering….
Using datagram QPs, it is possible to batch requests and ring the doorbell only once, regardless of the individual message destinations within the batch. With connected QPs the process must ring one doorbell for every destination.
FaSST RPCs
FaSST’s RPCs are designed for transaction workloads that use small (~100 byte) objects and a few tens of keys.
Since RDMA network latency is on the order of 10µs under load (much higher than the time spent in computation) FaSST uses coroutines to hide network latency. About 20 coroutines per thread turns out to be sufficient. Each thread is responsible for one RPC endpoint, which is serviced by the coroutine pool. One ‘master’ coroutine polls the network to identify newly arrived request and response packets, it then buffers response packets for ‘worker’ coroutines until all needed responses are available and then invokes the worker.
Workers operate on batches of b ≥ 1 requests. Requests are initially created without performaning any network I/O, and then an RPC function is invoked to send them.
Operating on batches of requests has several advantages. First, it reduces the number of NIC Doorbells the CPU must ring from b to 1, saving CPU cycles. Second, it allows the RPC layer to coalesce messages sent to the same destination machine.
FaSST also uses response batching, assembling a batch of B response packets and then sending them with one doorbell ring. Batching is opportunistic, the master does not wait for a batch of packets to accumulate before sending responses to avoid latency.
A circular buffer of RECV queue descriptors allows re-use without needing to create new descriptors and update a queue each time. Packet loss is detected by the master coroutine, which keeps a response counter for each worker.
If a packet is lost, the master never receives all responses for the worker; it never invokes the worker again, preventing it from issuing new requests and receiving more responses.
After timeout seconds the master kills the entire FaSST process on its machine. That sounds pretty draconian, and as the authors admit, “restarting a process on packet loss requires packet losses to be extremely rare.” And with this kind of network it turns out that indeed they are:
- A 46 hour stress test sending over 100 trillion RPC packets did not lose a single packet!
- Over about 50PB of data transfer (across several experiments) not a single packet was lost.
- Some packets are reordered though – about 1500 packets out of 100 trillion.

In our published measurements (papers here: http://www.cs.cmu.edu/~akalia/), there is little to no performance asymmetry between inbound and outbound RDMA. We have measured >20 Mops for 32-byte reliable outbound WRITEs on ConnectX-3; RFP reports only ~2 Mops (Figure 3).
The reason for this 10x difference is that in RFP’s experiments, server threads issue one RDMA write at a time, waiting for an ACK before issuing the next write.
That’s a really important piece of information, thank you!
I just read the paper, you are impressive that completes the coding alone, and makes it open-sourced! The work is really awesome!