RFP: When RPC is faster than server-bypass with RDMA Su et al., EuroSys’17
Every system that works with RDMA faces a choice of how best to use it: IP emulation mode, two-sided request-reply calls (RPC), one-sided calls, or even dropping down to the datagram level. We’ve seen a number of papers weighing in on this debate. One-sided RDMA calls (which completely bypass the remote CPU) are faster individually, but if you need more than one of them to get the job done, a two-sided call can be quicker. FaRM and DrTM chose one-sided RDMA, RAMCloud chose RPC. FaaSST chose an RPC-style mechanism implemented over datagrams (and if you want ultimate speed, FaaSST really is fast!).
In this paper the authors choose to stick with the reliable connection queue pair type (i.e., not using unreliable connections and datagrams as FaaSST does). They then systematically explore the trade-offs between RPCs and one-sided RDMA calls, and end up making that trade-off not at design time, but at run time, through a new approach they call the Remote Fetching Paradigm (RFP). Imagine a design that can switch as needed between client polling and server push, and you won’t be far wrong.
In tests, RFP ends up performing significantly better than approaches that choose to use all RPCs or all one-sided operations.
RDMA properties and trade-offs
The most straightforward port for most applications is to use the RPC interfaces. This looks just like you’d expect an RPC to look, and involves the remote server in processing the request and sending back a reply. In the paper this is denoted as server-reply.
One-sided RDMA operations totally bypass the CPU and OS kernel on remote machines, denoted server-bypass.
While relieving the server CPU from handling network packets can achieve better performance, it relies on developers to design specific data structures and algorithms, so that one-sided RDMA operation is feasible for a given problem… This becomes a dilemma between redesign cost and performance. More importantly, these special data structures are usually application-specific.
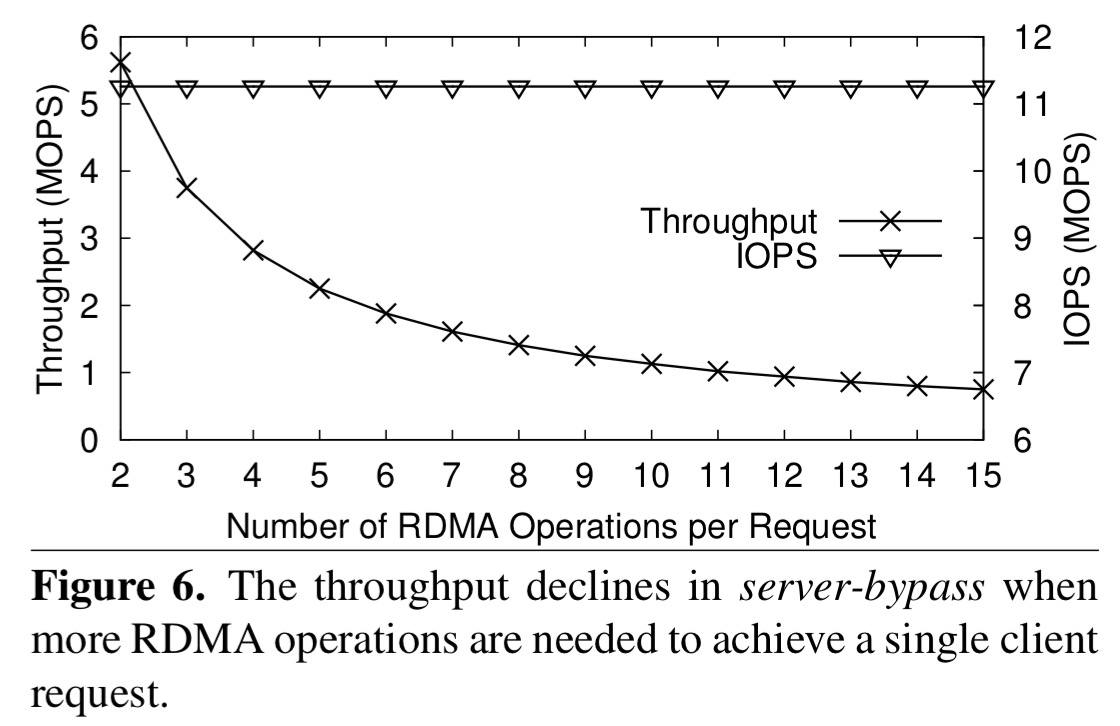
There’s another problem with the server-bypass mode, which the authors term bypass access amplification. It’s a fancy way of saying that you often need to make multiple 1-way reads to achieve a single objective.
The root cause is that CPU processing on the server is bypassed and multiple clients need to coordinate their access to avoid data access conflict with more RDMA operation rounds. Moreover, they may also need additional RDMA operations for meta-data probing to find where the data is stored on the server.
As we’ve seen before, once you start needing to make multiple one-ways calls, it might have been quicker just to do an RPC in the first place.
Viewed from the perspective of the server, we also need to consider in-bound vs out-bound asymmetry. It’s much cheaper to receive an in-bound RDMA operation than it is to send an out-bound reply. The RDMA Network Interface Card (RNIC) tested by the authors could sustain 5x more IOPS in-bound than it could out-bound.
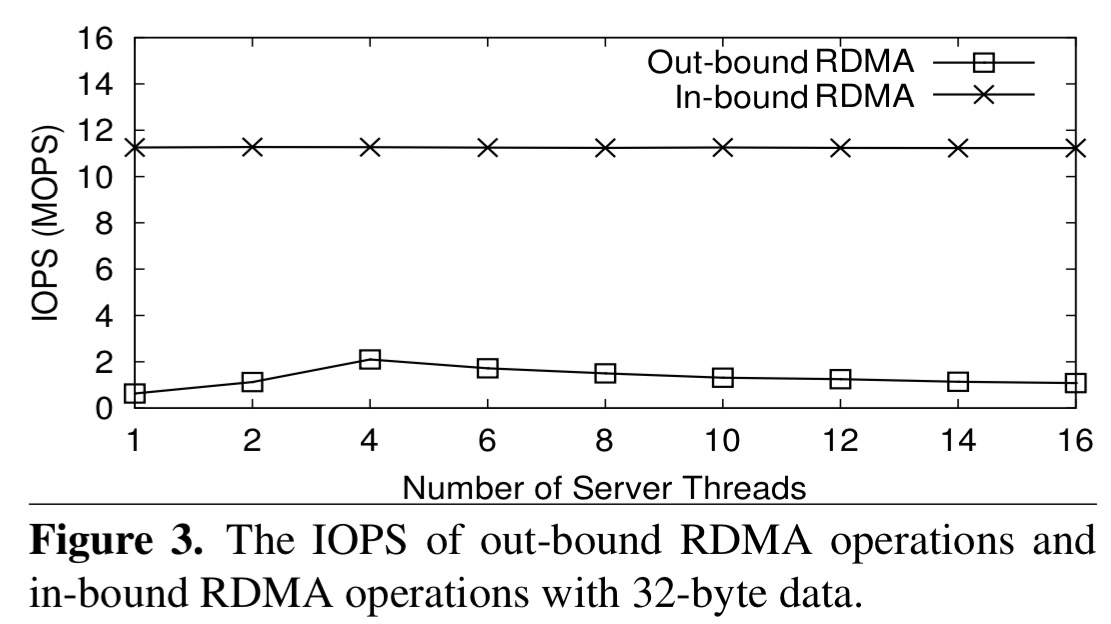
This explains why server-reply is suboptimal: besides not bypassing the server’s CPU, it also requires the server to issue RDMA operations, which is bounded by the limit of out-bound RDMA. The latter is quickly saturated while the in-bound IOPS are far from being saturated by client requests.
RFP design
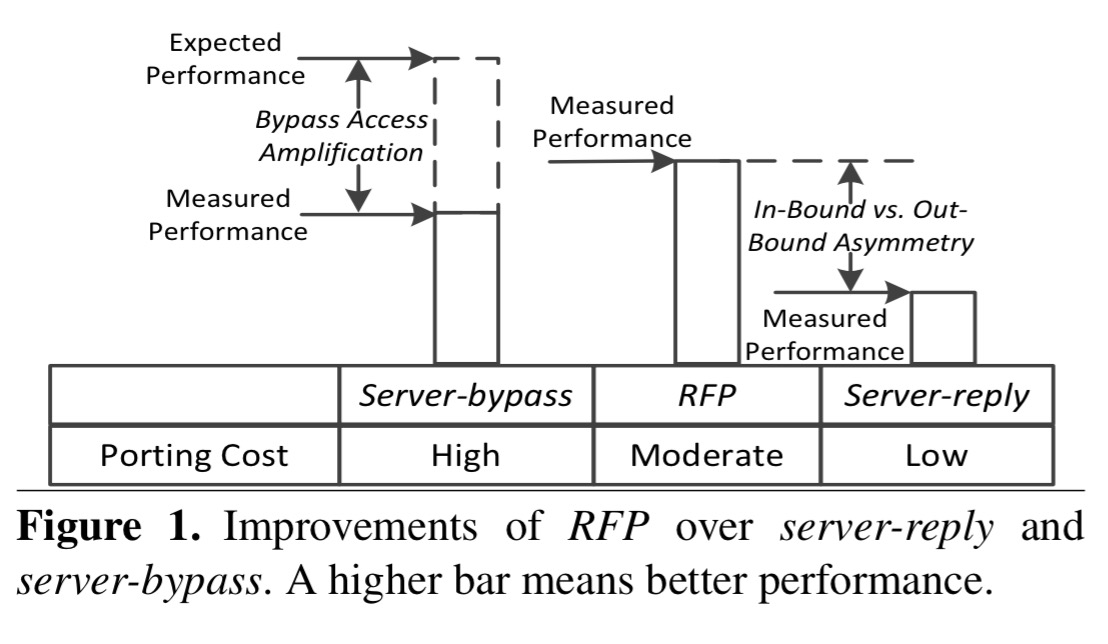
RFP provides an RPC style interface to ease porting costs, and introduces client polling for results. This prevents the server from needing to make outbound RDMA calls to reply to inbound requests. Like RPC, but unlike one-sided calls, it does however involve the server in request processing. Instead of sending a reply to the client, the server puts the reply in memory in a pre-agreed buffer. The client using one-sided RDMA reads to poll the buffer until it obtains the result. Compared to server-reply and server-bypass, it looks like this:

And here’s another perspective on it, this time considering porting costs and measured performance:
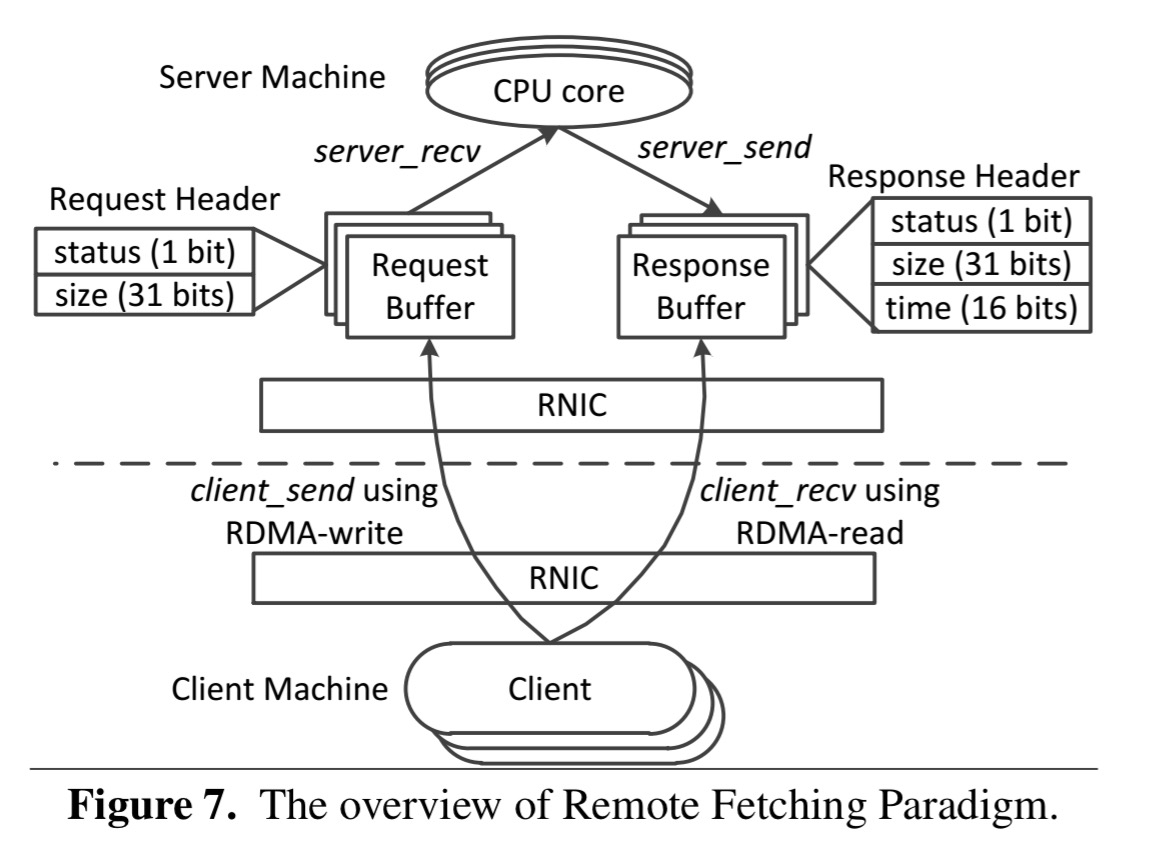
In terms of programming model, RFP clients use client_send to send their requests to the server’s memory through RDMA_Write and the server uses server_recv to get requests from local memory buffers and process them. The server then calls server_send to write the results into local memory buffers. The client uses client_recv to remotely fetch the results from the server’s memory.
The buffer to use is established when the client first registers itself to the server.
In summary, RFP combines the strength of the other two paradigms, while it also avoids their weakness. Firstly, RFP relies on the server to process the requests, which 1) avoids the need to design application-specific data structures, meaning that it can be used to adapt many legacy applications with only moderate programming cost; 2) it solves the bypass access amplification problem.
There’s one twist in the tale that we haven’t covered yet. If the server reply takes a (comparatively) long time, we’ll be wasting client-side CPU and in-bound IOPS repeatedly polling.
RFP therefore uses a hybrid mechanism to achieve a good trade-off among latency, throughput, and clients’ CPU consumption. The mechanism starts from using repeated remote fetching and then automatically switches to server-reply if it detects the number of retries is larger than a certain threshold R [across two consecutive RPC calls].
Tuning RFP
In additional to finding a suitable value for R, we also need to configure F, the size of the memory buffer that is fetched by the client. So long as the result size is less than F, a client can retrieve the response header and payload data with a single read. Otherwise an additional read is needed to fetch the remaining data.
Section 3.2 in the paper describes how to choose these parameters. The search space is small enough that RFP can do an exhaustive search to find the values of F and R that maximise throughput.
Evaluation
Evaluation is done with an eight machine InfiniBand cluster, where each machine has eight cores. The team implemented an in-memory key-value store called Jakiro which was tested with a variety of workloads: uniformly distributed and read intensive, skewed, write-intensive, and with different value sizes. Comparisons are undertaken against Pilaf, a state-of-the-art in memory key-value store using server-bypass, a version of Jakiro set to always use server-reply (ServerReply), and an RDMA-based memcached also using server-reply.
For a uniform read-intensive workload, Jakiro achieves peak throughput of 5.5 MOPS. Here’s how Jaxiro stacks up against Pilaf on a 50% GET workload:
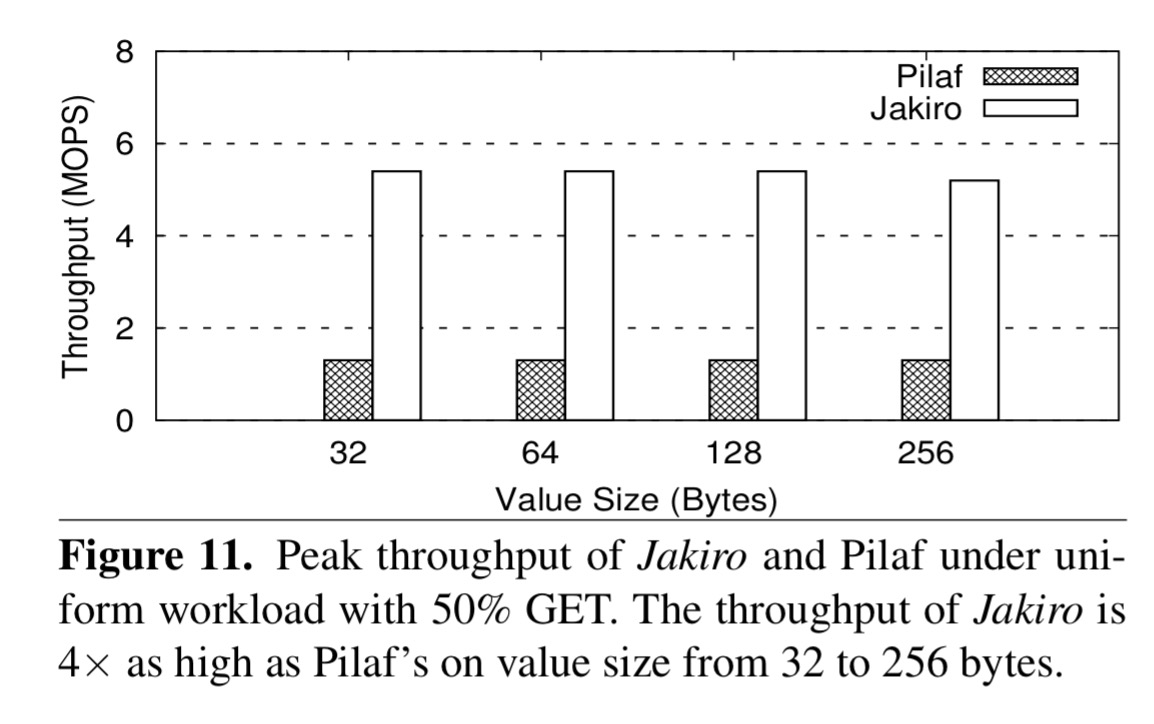
And here’s the comparison with the server-reply based systems:
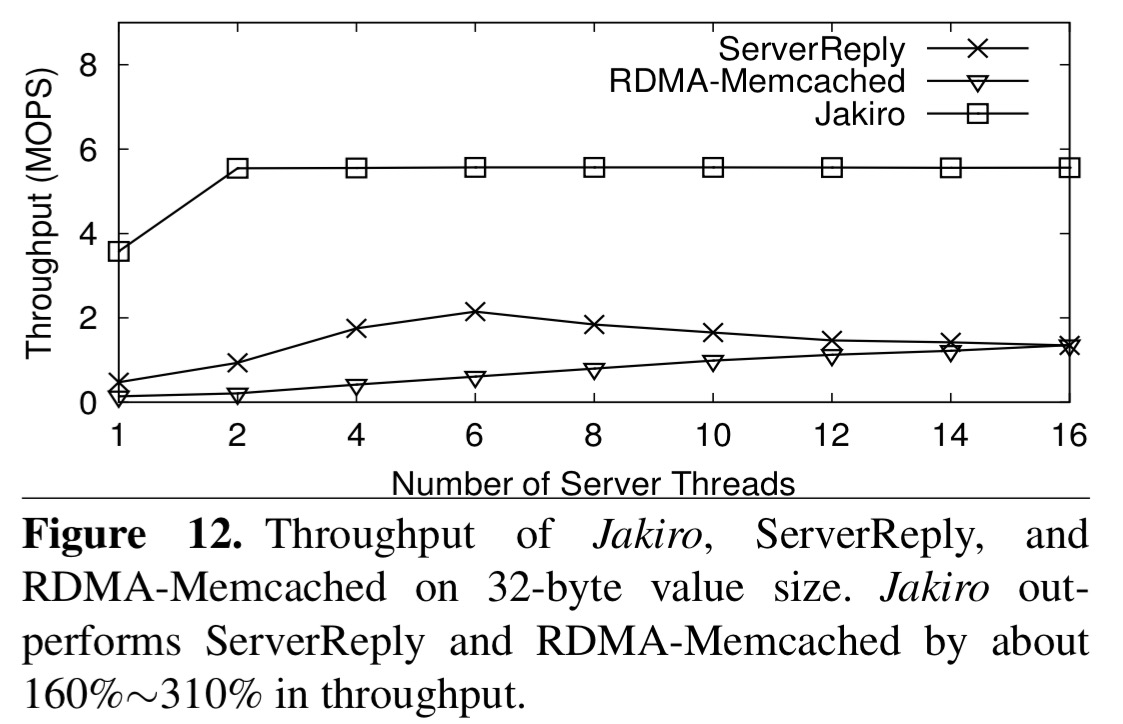
The peak throughput of Jakiro is 5.5 MOPS, about 158% higher than ServerReply (2.1 MOPS), and about 310% higher than RDMA-Memcached (1.3 MOPS).
If we look instead at latency, we see that Jakiro has very tightly-bounded latency that beats the other approaches everywhere other than at the very low-latency end of the spectrum:
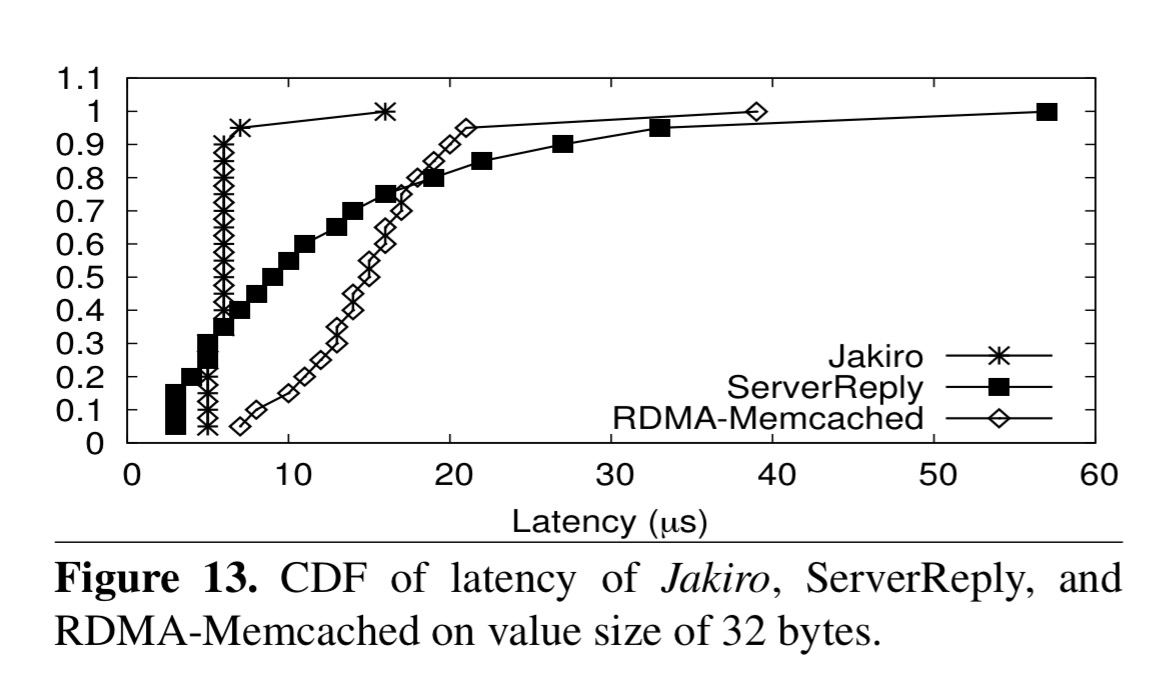
As the amount of time the server takes to process each request goes up, Jakiro’s advantage over the server-reply scheme falls away since it also switches to using server-reply.
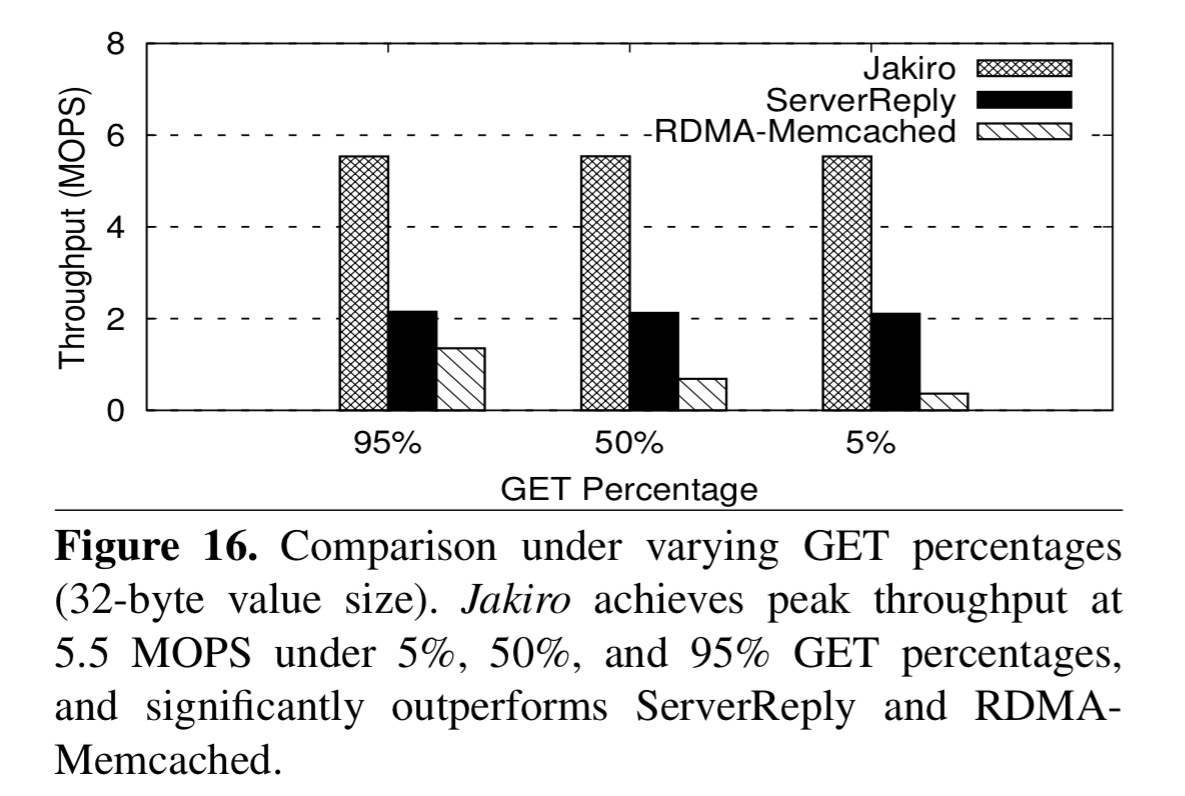
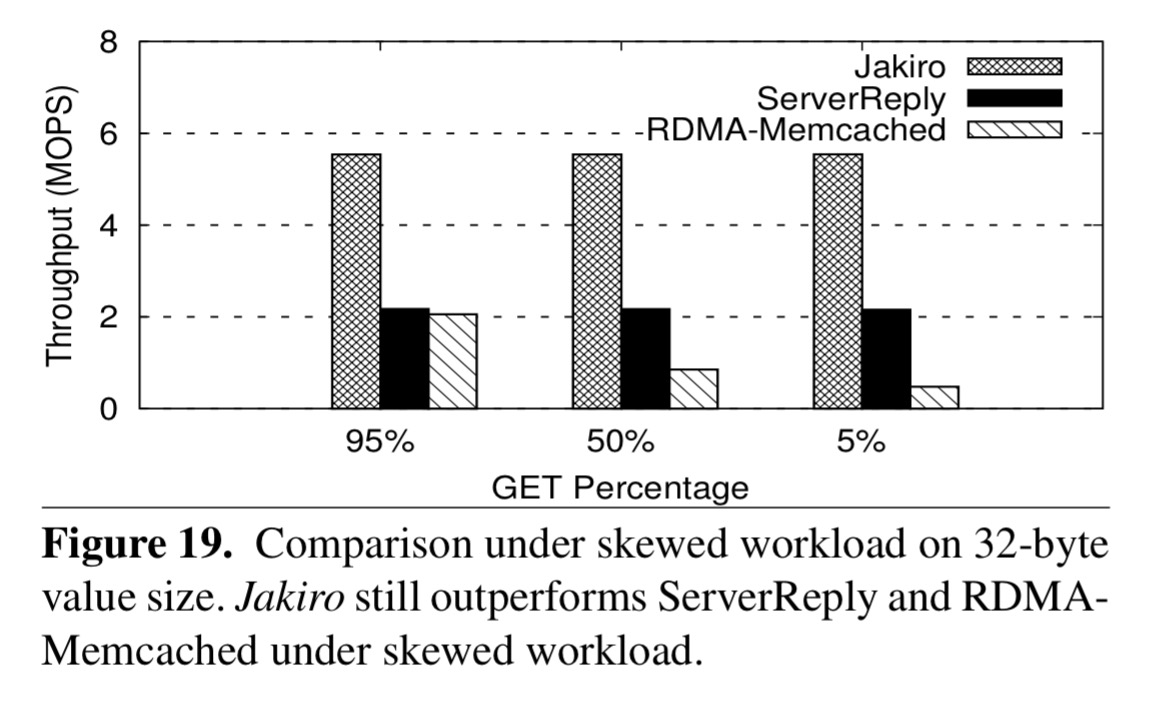
Jakiro holds its advantage through varying GET percentages, and for skewed workloads:
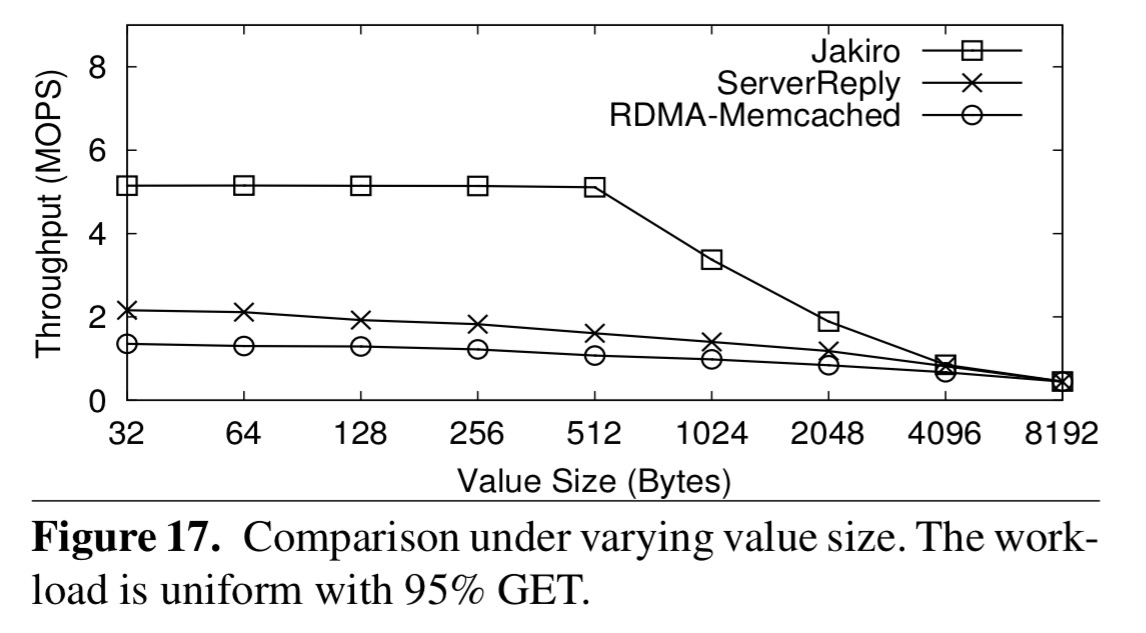
With varying value sizes, Jakiro’s advantage is greater with smaller values, and is lost by the time we reach 8K values.
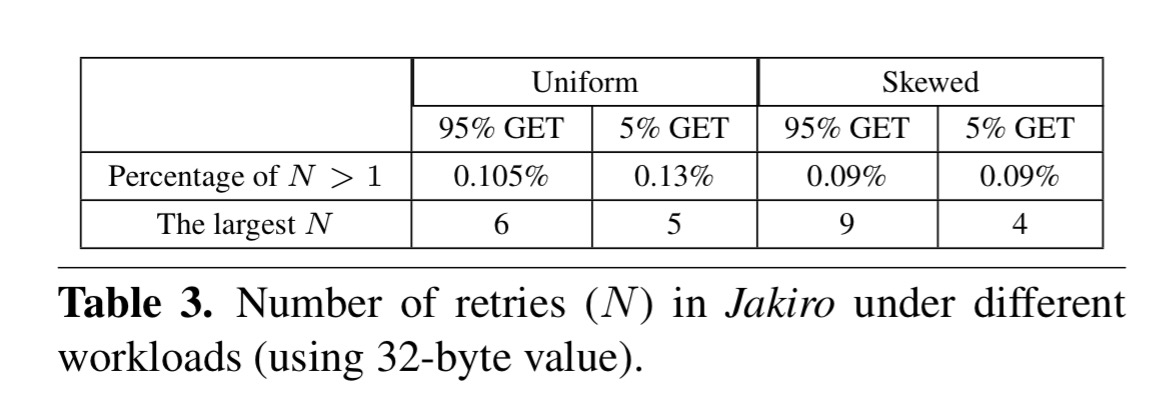
Finally, we can see how many retries Jakiro actually ended up using for client fetch across a variety of workloads. It’s very rare that more than one is needed.
By making the server involved in request processing, RFP is able to support traditional RPC interface based applications. By counter-intuitively making clients fetch results from server’s memory remotely, RFP.makes good usage of server’s in-bound RDMA and thus achieves higher performance. Experiments show 1.6x ~ 4x improvement of RFP over server-reply and server-bypass. We believe RFP can be integrated into many RPC-based systems to improve their performance without much effort.

In our published measurements (papers here: http://www.cs.cmu.edu/~akalia/), there is little to no performance asymmetry between inbound and outbound RDMA. We have measured >20 Mops for 32-byte reliable outbound WRITEs on ConnectX-3; RFP reports only ~2 Mops (Figure 3).
The reason for this 10x difference is that in RFP’s experiments, server threads issue one RDMA write at a time, waiting for an ACK before issuing the next write.
Awesome practical interface to RDMA: https://www.usenix.org/system/files/conference/atc18/atc18-aguilera.pdf