Just say NO to Paxos overhead: replacing consensus with network ordering Li et al., OSDI 2016
Everyone knows that consensus systems such as Paxos, Viewstamped Replication, and Raft impose high overhead and have limited throughput and scalability. Li et al. carefully examine the assumptions on which those systems are based, and finds out that within a data center context (where we can rely on certain network properties), we can say NO to the overhead. NO in this case stands for ‘Network Ordering’.
This paper demonstrates that replication in the data center need not impose such a cost by introducing a new replication protocol with performance within 2% of an unreplicated system.
If you have a completely asynchronous and unordered network, then you need the full complexity of Paxos. Go to the other extreme and provide totally ordered atomic broadcast at the network level, and replica consistency is trivial. Providing totally ordered atomic broadcast though requires moving pretty much the exact same coordination overhead just to a different layer.
So at first glance it seems we just have to pay the coordination price one way or another. And you’d think that would be true for any division of responsibility we can come up with. But Li et al. find an asymmetry to exploit – there are certain properties that are stronger than completely asynchronous and unordered, but weaker than totally ordered atomic, which can be implemented very efficiently within the network.
Our key insight is that the communication layer should provide a new ordered unreliable multicast (OUM) primitive – where all receivers are guaranteed to process multicast messages in the same order, but messages may be lost. This model is weak enough to be implemented efficiently, yet strong enough to dramatically reduce the costs of a replication protocol.
That really only leaves us with three questions to answer: (i) can we implement OUM efficiently in a modern data center, (ii) does OUM meaningfully simplify a replication protocol, and (iii) does the resulting system perform well in practice.
We’ll take each of those questions in turn over the next three sections. The TL;DR version is: Yes, yes, and yes.
By relying on the OUM primitive, NOPaxos avoids all coordination except in rare cases, eliminating nearly all the performance overhead of traditional replication protocols. It provides _throughput within 2% and latency within 16µs of an unreplicated system, demonstrating that there need not be a tradeoff between enforcing strong consistency and providing maximum performance.
Can OUM be implemented efficiently?
Ordered unreliable multicast skips the difficult problem of guaranteeing reliable delivery in the face of a wide range of failures, but does provide an in-order guarantee for the messages it does deliver.
- There is no bound on the latency of message delivery
- There is no guarantee that any message will ever be delivered to any recipient
- If two messages m and m’ are multicast to a set of processes R, then all processes in R that receive m and m’ receive them in the same order.
- If some message m is multicast to some set of processes, R, then either (1) every process in R receives m or a notification that there was a dropped message before receiving the next multicast, or (2) no process in R receives m or a dropped message notification for m.
The asynchrony and unreliability properties are standard in network design. Ordered multicast is not: existing multicast mechanisms do not exhibit this property.
An OUM group is a set of receivers identified by an IP address. For each OUM group there are one or more sessions. The stream of messages sent to a particular group is decided into consecutive OUM sessions, and during a session all OUM guarantees apply. (They sound similar to the more familiar consensus algorithm notion of an epoch). Sessions are generally long-lived, but failures may cause them to end, in which case we can use a more expensive protocol to switch to a new session.
One easy to understand design for OUM would simply be to route all traffic for a group through a single sequencer node that adds a sequence number to every packet before forwarding it. That of course would be a crazy bottleneck and single point of failure… or would it??
Adding the sequencer itself is straightforward using the capabilities of modern SDNs. But how do we achieve high throughput, low latency, and fault-tolerance?
Each OUM group is given a distinct address in the data center network that senders use to address messages to the group. All traffic for this group is routed through the group’s sequencer. If we use a switch itself as the sequencer, and that switch happens to be one through which nearly all of the traffic passes anyway (i.e., a common ancestor of all destination nodes in the tree hierarchy to avoid increasing path lengths) then there is almost zero added overhead.
In 88% of cases, network serialization added no additional latency for the message to be received by a quorum of 3 receivers; the 99th percentile was less than 5µs of added latency.
Because the sequencer increments its counter by one on each packet, the client libOUM library can easily detect drops and return drop-notifications when it sees gaps in the sequence numbering.
Using a switch as a sequencer is made possible by the increasing ability of data center switches to perform flexible, per-packet computations.
A whole new class of switch architectures provide the needed programmability, exposed through high-level languages like P4, and provides orders-of-magnitude lower latency and greater reliability than using an end-host for the same functionality. Such programmable switches will be commercially available within the next year, but they’re not here yet. In the meantime, it’s possible to implement the scheme as a middlebox using existing OpenFlow switches and a network processor. An implementation using a Cavium Octeon II CN68XX network processor imposed latency of 8µs in the median case, and 16µs in the 99th percentile.
Such switches and network processors are very unlikely to become the bottleneck – even a much slower end-host sequencer using RDMA can process close to 100M requests per second – many more than any single OUM group can process.
If a sequencer fails, the controller selects a different switch and reconfigures the network to use it.
During the reconfiguration period, multicast messages may not be delivered. However, failures of root switches happen infrequently, and rerouting can be completed within a few milliseconds, so this should not significantly affect system availability.
Adding session numbers in front of the sequencer count numbers ensures that the rare failures of switches can always be detected. Changing sessions is done using a Paxos-replicated controller group.
Does OUM meaningfully simplify replication?
NOPaxos, on Network-Ordered Paxos, is a new replication protocol which leverages the Ordered Unreliable Multicast sessions provided by the network layer.
Here’s the intution: a traditional state machine replication system must provide two guarantees:
- Ordering: if some replica processes request a before b, no replica processes b before a.
- Reliable delivery: every request submitted by a client is either processed by all replicas or none.
In our case, the first of these two requirements is handled entirely by the OUM layer.
NOPaxos is built on top of the guarantees of the OUM network primitive. During a single OUM session, requests broadcast to the replicas are totally ordered but can be dropped. As a result, the replicas have only to agree on which requests to execute and which to permanently ignore, a simpler task than agreeing on the order of requests. Conceptually, this is equivalent to running multiple rounds of binary consensus. However, NOPaxos must explicitly run this consensus only when drop-notifications are received. To switch OUM sessions (in the case of sequencer failure), the replicas must agree on the contents of their shared log before they start listening to the new session.
Details of the four sub-protocols that comprise NOPaxos (normal operations, gap agreement, view change, and periodic synchronisation) are given in section 5.2 of the paper.
Read the fine print, and you’ll discover that only the session leader actually executes requests (single master), and replicas log all requests but do not always know which ones have actually been executed / accepted at any given point in time (and therefore can’t be used reliably as read slaves either). Therefore we’re really looking at replication for availability and reliability, but not for scalability.
During any view, only the leader executes operations and provides results. Thus, all successful client REQUESTs are committed on a stable log at the leader, which contains only persistent client REQUESTs. In contrast, non-leader replicas might have speculative operations throughout their logs. If the leader crashes, the view change protocol ensures that the new leader first recreates the stable log of successful operations. However, it must then execute all operations before it can process new ones. While this protocol is correct, it is clearly inefficient.
Therefore, as an optimization, NOPaxos periodically executes a synchronization protocol in the background. This protocol ensures that all other replicas learn which operations have successfully completed and which the leader has replaced with NO-OPs. That is, synchronization ensures that all replicas’ logs are stable up to their syncpoint and that they can safely execute all REQUESTs up to this point in the background
Does the resulting system perform well in practice?
NOPaxos itself achieves the theoretical minimum latency and maximum throughput: it can execute operations in one round trip from client to replicas, and does not require replicas to coordinate on requests.
The evaluation compared NOPaxos to Paxos, Fast Paxos, Paxos with batching, and Speculative Paxos, as well as against an unreplicated system providing no fault tolerance.
Fig. 5 below shows how the systems compare on latency and throughput:
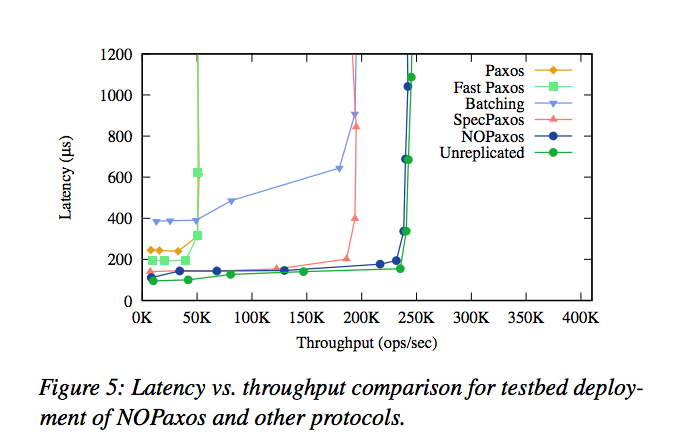
And here’s an evaluation of a distributed in-memory key-value store running on top of all of these algorithms:
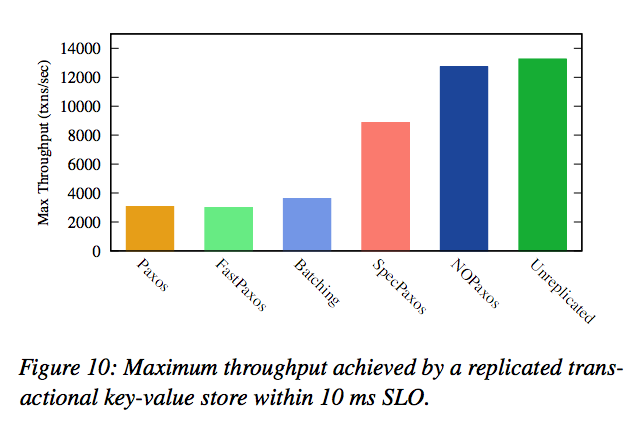
NOPaxos outperforms all other variants on this metric: it attains more than 4 times the performance of Paxos, and outperforms the best prior protocol, Speculative Paxos, by 45%. Its throughput is also within 4% of an unreplicated system.

Isn’t it just the RAFT?
First, how is RAFT different than Paxos/Viewstamped Replication in you opinion?
IMHOP, RAFT is not a Paxos, maybe already a NOPaxos because this paper seems to describe the RAFT again…
“@CS PhD” ‘s comment is what I want to say, https://blog.acolyer.org/2016/12/08/just-say-no-to-paxos-overhead-replacing-consensus-with-network-ordering/#comment-8987
Isn’t it just the RAFT?
Network ordering, and its counterpart Commitment Ordering have been
known for a long time in the industry and have been used in commercial
products, such as Informix XPS and Tandem ServerNet and NonStop-SQL.
It is fascinating to see how every two decades or so “new” methods and
algorithms are discovered by researchers who never take one moment
to find out what previous generations had done.
Can you point us to some papers?
I am afraid not. Vendors of proprietary, closed source
systems were not motivated to publish descriptions of
their technologies they viewed as highly competitive
differentiators. I happen to know them as a result of
having worked on the projects I mentioned.
ServerNet hardware was pretty well documented in
patent applications and in some papers, however I
do not recall anything ever being published about
the software, and I was the software architect.
Likewise, I do not recall any papers describing the
internal architecture and protocols of Informix XPS.
There may have been a few presentations at the
IUG (Informix User Group) conferences, however
those would not usually describe the architecture
in depth and would most likely be charts showing
the major system components. Serializability is a
complex and difficult topic even for developers —
no one would bother end users with such detail.
Commitment ordering is well documented in a
series of papers published by DEC, and the
Wikipedia page is a good starting point. DEC
also patented CO and ECO, and the patents
just expired this year.
Hope this answers your question, at least to
the extent it can be answered publicly. Please
feel free to e-mail me privately for more details.
@Deep Blue, you can’t accuse researchers for not taking one moment to find out what the previous generations had done, if those previous generations never shared what they had done (as you admit below) :)
This sounds like RAFT, with partial implementation of the leader in hardware. Most of what the RAFT leader does is simply forward messages to replicas with sequence numbers. In the case the replica has missed a message, the leader re-forwards the missing prefix of the log. It makes sense, but I wonder if most of the gains are really due to not having a linux kernel in the way.
Agree
Would be interesting to see how it compares against Flexible Paxos (https://blog.acolyer.org/2016/09/27/flexible-paxos-quorum-intersection-revisited/)…
Maybe they can be combined?
Reading this reminded me of the Time-Less Datacenter https://www.youtube.com/watch?v=IPTlTmH-YvQ
One major difference of NOPaxos against Paxos variants is that NOPaxos does not/cannot assure the property called Uniform agreement: if the leader processes a request and then crashes, that request may not be processed in that order by the reconstituted system (with a new leader). Consequently, 1-server abstraction of a replicated system cannot be maintained: clients will receive at most 2f+1 REPLYs for every request sent to the replicated systems and have to do the (f+1) verification.
in normal case, if leader reply to the client, but client has only receive n(n < f+1), then what? if this client do not re commit the request, the paper do not mention it