In Search of an Understandable Consensus Algorithm (Extended Edition) – Ongaro & Ousterhout 2014
This is part 9 of a ten part series on consensus and replication.
Here’s something to be grateful for: a consensus algorithm with a primary goal of being understandable! The authors also claim it provides a better foundation (than previous algorithms) for building distributed systems.
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos; this makes Raft more understandable than Paxos and also provides a better foundation for building practical systems.
Raft is closest in spirit to Viewstamped Replication but with several new features:
- Strong leadership in which log entries only ever flow from the leader to other servers.
- Randomized timers during leader election
- A joint consensus approach for managing membership changes.
In addition to the prose description in this paper, it has been formally specified in TLA+ together with a proof of the safety of its consensus mechanism.
Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply log entries to their state machines.
Raft makes 5 key guarantees:
- Election Safety at most one leader can be elected in a given term.
- Leader Append-Only a leader never overwrites or deletes entries in its log, it only appends
- Log Matching if two logs contain an entry with the same index and term, then the logs are identical up to that index
- Leader Completeness if a log entry is committed in a given term, then that entry wil be committed in the logs of the leaders for all higher-numbered terms.
- State Machine Safety if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
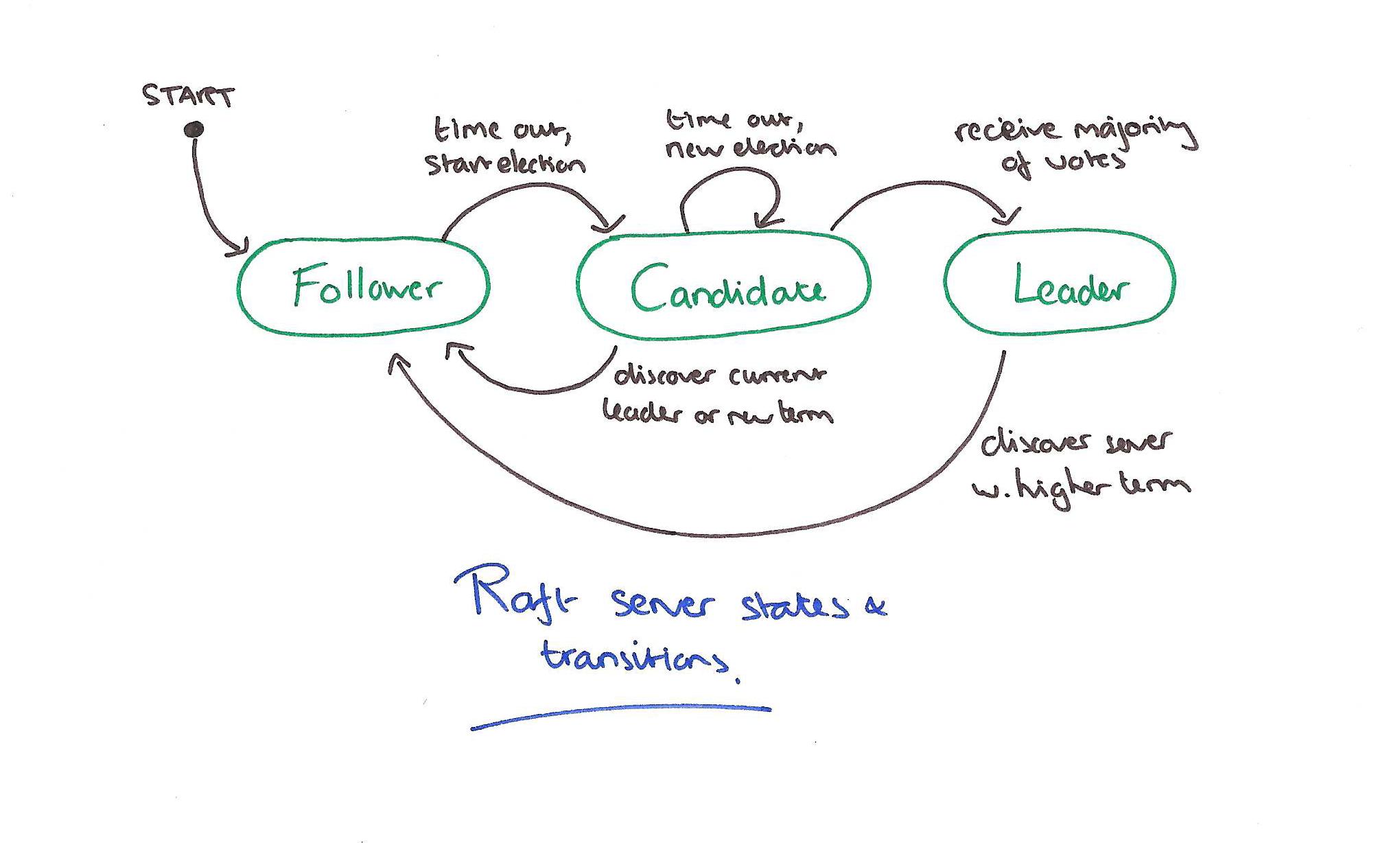
Raft divides time into terms, each beginning with an election. If a candidate wins the election, they stay as leader for the rest of the term. If an election results in a split vote then the term ends with no leader and a new term begins. Term numbers increase monotonically over time, and are exchanged in every communication. Servers may in one of three states: leader, follower, or candidate. If a leader or candidate determines that their own term number is behind, it will immediately revert to follower status.
Raft’s basic consensus algorithm depends on only two message (RPC) types: RequestVote and AppendEntries. RequestVote messages are initiated by candidates during elections, and AppendEntries messages are initiated by leaders to transfer log entries, and as a heartbeat. A third message type, InstallSnapshot is also used for transferring snapshots between servers.
The full Raft paper is very readable, and runs to 18 pages. I will focus on the core algorithm in this post, but its well worth going on to read the full paper if you have interest.
Leader Election
Servers start up as followers, and remain in this state so long as they receive periodic AppendEntries RPCs (a leader can send an AppendEntries RPC with no log entries to act as a heartbeat). If a follower receives no communication for longer than the election timeout period then it begins an election.
- The follower increments its current term, transitions to candidate status, and sends RequestVote RPCs to to each of the other servers. If it receives votes from a majority of the servers for the same term, it transitions to leader. It then sends heartbeat messages to all other servers to establish its authority.
- A server in candidate status may also receive RequestVote RPCs. If the term is less than the server’s own, the message is rejected. Otherwise the candidate recognises the leader as legitimate and returns to follower state.
- If the candidate neither wins nor loses, it times out and starts another round of RequestVote RPCs.
When a server in one of the leader or follower states receives a RequestVote RPC it responds as follows:
- If the term in the vote is less than its own, it rejects the vote as above.
- If the server has not already voted for someone else in this term, and the candidate’s log is at least as up to date as its own, it grants the vote.
Randomized election timeouts are used to ensure that split votes are rare and that they can be resolved quickly. Each candidate resets its election timeout to a random value from some fixed interval (e.g 150-300ms) at the start of each election.
Leader election is the aspect of Raft where timing is most critical. Raft will be able to elect and maintain a steady leader as long as the system satisfies the following timing requirement: broadcastTime ≪ electionTimeout ≪ MTBF. In this inequality broadcastTime is the average time it takes a server to send RPCs in parallel to every server in the cluster and receive their responses.
Raft RPCs typically take 0.5ms to 20ms (including the time taken to persist information to stable storage), so election timeout is likely to be somewhere between 100ms and 500ms.
Elections are an example of how understandability guided our choice between design alternatives. Initially we planned to use a ranking system: each candidate was assigned a unique rank, which was used to select between competing candidates… We made adjustments to the algorithm several times, but after each adjustment new corner cases appeared. Eventually we concluded that the randomized retry approach is more obvious and understandable.
Log Replication
When the leader receives a client request, it appends the command to its log as a new entry and then issues AppendEntries RPCs to replicate the entry to all other servers. When the entry has been safely replicated to a majority of servers, the leader applies the entry to its state machine and returns the result to the client. The leader retries AppendEntries RPCs indefinitely until all followers eventually store all log entries. Each log entry stores a state machine command along with the term number of the term when the entry was received by the leader.
Commiting an entry also commits all previous entries in the leader’s log, including entries created by previous leaders. Once a follower learns that a log entry has been committed, it applies the log entry to its local state machine (in log order).
Raft maintains the following properties, which together constitute the Log Matching Property: (1) If two entries in different logs have the same index and term, then they store the same command; (2) If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
When sending an AppendEntries RPC, the leader includes the index and term of the entry in its log that immediately precedes the new entries. If the follower does not find a matching entry, then it refuses the new entries.
The consistency check acts as an induction step: the initial empty state of the logs satisfies the Log Matching Property, and the consistency check preserves the Log Matching Property whenever logs are extended. As a result, wheneverAppendEntries returns successfully, the leader knows that the follower’s log is identical to its own log up through the new entries.
Leader and follower crashes can leave logs in an inconsistent state, which is resolved by forcing followers’ logs to duplicate the leader’s.
To bring a follower’s log into consistency with its own, the leader must find the latest log entry where the two logs agree, delete any entries in the follower’s log after that point, and send the follower all of the leader’s entries after that point. All of these actions happen in response to the consistency check performed by AppendEntries RPCs.
The mechanism to find the latest log entry that matches is simple: if the logs don’t match, a follower will reject an AppendEntries RPC. The leader then retries AppendEntries starting from one entry earlier in its own log. Eventually this process reaches a point where the logs match.
With this mechanism, a leader does not need to take any special actions to restore log consistency when it comes to power. It just begins normal operation, and the logs automatically converge in response to failures of the Append-Entries consistency check. A leader never overwrites or deletes entries in its own log (the Leader Append-Only Property).
If a leader crashes before commiting an entry, future leaders will attempt to finish replicating it. However, a future leader cannot safely conclude that such an entry is commited once it is stored on a majority of servers (see the paper for an example sequence illustrating why this may be the case). To eliminate such problems, …
… Raft never commits log entries from previous terms by counting replicas. Only log entries from the leader’s current term are committed by counting replicas; once an entry from the current term has been committed in this way, then all prior entries are committed indirectly because of the Log Matching Property.
Cluster Membership Changes
For the configuration change mechanism to be safe, there must be no point during the transition where it is possible for two leaders to be elected for the same term. Unfortunately, any approach where servers switch directly from the old configuration to the new configuration is unsafe. It isn’t possible to atomically switch all of the servers at once, so the cluster can potentially split into two independent majorities during the transition.
Raft handles this via an intermediate state called joint consensus, which combines both the old and the new configurations.
- Log entries are replicated to all servers in the union
- Any server from either configuration can serve as leader
- Agreement requires separate majorities from both the old and the new configuration.
Once the joint consensus state has been commited, the leader can create a log entry describing the new configuration and replicate it to the cluster, thus completing the transition. The rules surrounding how this all works can be found in the paper, and are perhaps the subtlest part of the overall protocol.
Bonus items
This extended edition of the paper contains extra sections on log compaction (using the InstallSnapshot RPC to bring a follower that has fallen behind the leaders snapshot point back up to speed), and on client interactions.
When a follower receives a snapshot with this RPC, it must decide what to do with its existing log entries. Usually the snapshot will contain new information not already in the recipient’s log. In this case, the follower discards its entire log; it is all superseded by the snapshot and may possibly have uncommitted entries that conflict with the snapshot. If instead the follower receives a snapshot that describes a prefix of its log (due to retransmission or by mistake), then log entries covered by the snapshot are deleted but entries following the snapshot are still valid and must be retained.
If a server crashes after commiting an item, but before responding to the client (or the reply is lost, or delayed), then the client may resubmit the request. If clients assign unique serial numbers to each command then the state machine can track these and respond immediately without re-executing a request if it sees a duplicate.
Finally, we have guidance on how to ensure linearizable reads:
Linearizable reads must not return stale data, and Raft needs two extra precautions to guarantee this without using the log. First, a leader must have the latest information on which entries are committed. The Leader Completeness Property guarantees that a leader has all committed entries, but at the start of its term, it may not know which those are. To find out, it needs to commit an entry from its term. Raft handles this by having each leader commit a blank no-op entry into the log at the start of its term. Second, a leader must check whether it has been deposed before processing a read-only request (its information may be stale if a more recent leader has been elected). Raft handles this by having the leader exchange heartbeat messages with a majority of the cluster before responding to read-only requests.

8 thoughts on “In Search of an Understandable Consensus Algorithm”
Comments are closed.