Viewstamped Replication Revisited – Liskov & Cowling 2012
This paper presents an updated version of Viewstamped Replication (referred to as VR from now on). VR works in an asynchronous network like the Internet, and handles failures in which nodes fail by crashing. It supports a replicated service that runs on a number of replica nodes. The service maintains a state, and makes that state accessible to a set of client machines. VR provides state machine replication: clients can run general operations to observe and modify the service state. Thus the approach is suitable for implementing replicated services such as a lock manager or a file system.
What a difference 24 years makes! Here we have the kind of super clear explanation of the Viewstamped Replication protocol that makes you want to break out the editor and start coding it up straight away – if you hadn’t just read Paxos Made Live of course ;). Compared to the original paper that we looked at on Monday, on top of a much clearer explanation this version includes support for reconfiguration (adding or removing group members), several optimisations, and a clean distinction between the ViewStamped Replication (VR) algorithm and any state-machine based distributed system you might build on top.
It differs from Paxos in that it is a replication protocol rather than a consensus protocol: it uses consensus, with a protocol very similar to Paxos, as part of supporting a replicated state machine. Another point is that unlike Paxos, VR did not require disk I/O during the consensus protocol used to execute state machine operations
The lifetime of the system is divided into epochs, and epochs are divided into views. When not changing between views or epochs, the system operates normally . Epoch changes are driven by an administrative action to add or remove group members (this may be automated of course). View changes within an epoch are driven by process or communication failure (assumed to be temporary) amongst the members of the epoch.
There are four interlocking protocols: normal operation, the view-change protocol, the recovery protocol (for a crashed and recovering replica), and the reconfiguration protocol (for moving to a new epoch). VR doesn’t mind what kind of state machine you build on top – the VR protocols look after the distribution aspects, and you supply the state machine (called the service in the paper).
VR ensures reliability and availability when no more than a threshold of f replicas are faulty. It does this by using replica groups of size 2f + 1; this is the minimal number of replicas in an asynchronous network under the crash failure model…. A group of f +1 replicas is often referred to as a quorum and correctness of the protocol depends on the quorum intersection property: the quorum of replicas that processes a particular step of the protocol must have a non-empty intersection with the group of replicas available to handle the next step.
Normal operations
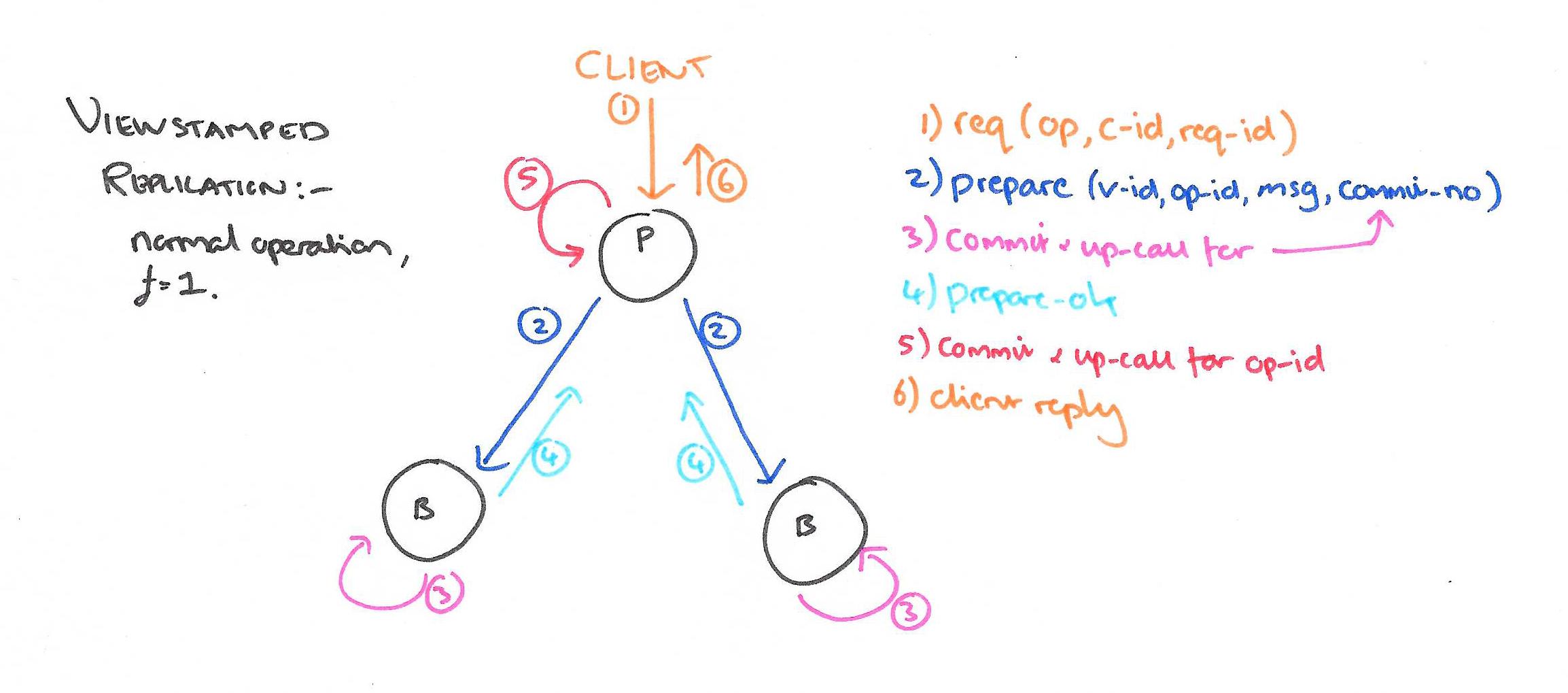
The protocol description assumes all participating replicas are in the same view. Every message sent from one replica to another contains the sender’s current viewnumber. Replicas only process normal protocol messages containing a view-number that matches the view-number they know. If the sender is behind, the receiver drops the message. If the sender is ahead, the replica performs a state transfer: it requests information it is missing from the other replicas and uses this information to bring itself up to date before processing the message.
One of the replicas is the primary, to which client requests are directed. The primary orders requests; the other replicas are backups that simply accept the order chosen by the primary.
Clients each have a unique client-id, and maintain an incrementing request-number for each request they send. A client sends a request message to the primary asking it to perform some operation, passing its client-id and the assigned request-number. If the request-number is not greater than the highest request number the primary has seen for this client it does not process the request (but will resend the response for that request if it is the most recent one it has seen).
Assuming the primary intends to process the request:
- The primary assigns the request the next operation_number and adds it to its log. It then sends a prepare message to each replica with the current view-number, the operation-number, the client’s message, and the commit-number (the operation number of the most recently committed operation). The commit-number is used to piggy-back information about committed operations on the back of prepare requests.
- When a backup receives a prepare message, it first waits until it has processed all operations preceding the operation number (using state catch-up if necessary). Then it adds the request to the end of its log and sends back a prepare-ok message.
- When the primary has received f prepare-ok messages it considers the operation committed. It updates its commit-number and makes an up-call to the service to perform the requested operation. A reply message is then sent to the client.
Normally replicas hear about the commit in the next prepare message. If there is no new request forthcoming in a timely manner the primary may send a commit message to inform them. When a backup learns that an operation has been committed (via either of these two means), it first ensures that it has executed all previous operations, and then executes the operation by performing an up-call to the service layer. (It does not send a reply to the client, the primary has already done this).
Changing views
The keep-alive messages discussed in the original paper are replaced by the regular flow of prepare messages (when the service is busy), or commit messages if it is quiet (it makes sense to have some useful information included in a ‘keep-alive’):
Backups monitor the primary: they expect to hear from it regularly. Normally the primary is sending PREPARE messages, but if it is idle (due to no requests) it sends COMMIT messages instead. If a timeout expires without a communication from the primary, the replicas carry out a view change to switch to a new primary.
Here’s a little curiosity: there is no leader election as such to chose a new primary. Within an epoch the group members are fixed (even though some may be unreachable or failed). Each of these is assumed to have a unique IP address, and leadership rotates around the group in round-robin order of ascending IP addresses. So when a primary fails, each group member already knows which member is expected to be the next primary…
Therefore the view change protocol obtains information from the logs of at least f + 1 replicas. This is sufficient to ensure that all committed operations will be known, since each must be recorded in at least one of these logs; here we are relying on the quorum intersection property. Operations that had not committed might also survive, but this is not a problem: it is beneficial to have as many operations survive as possible.
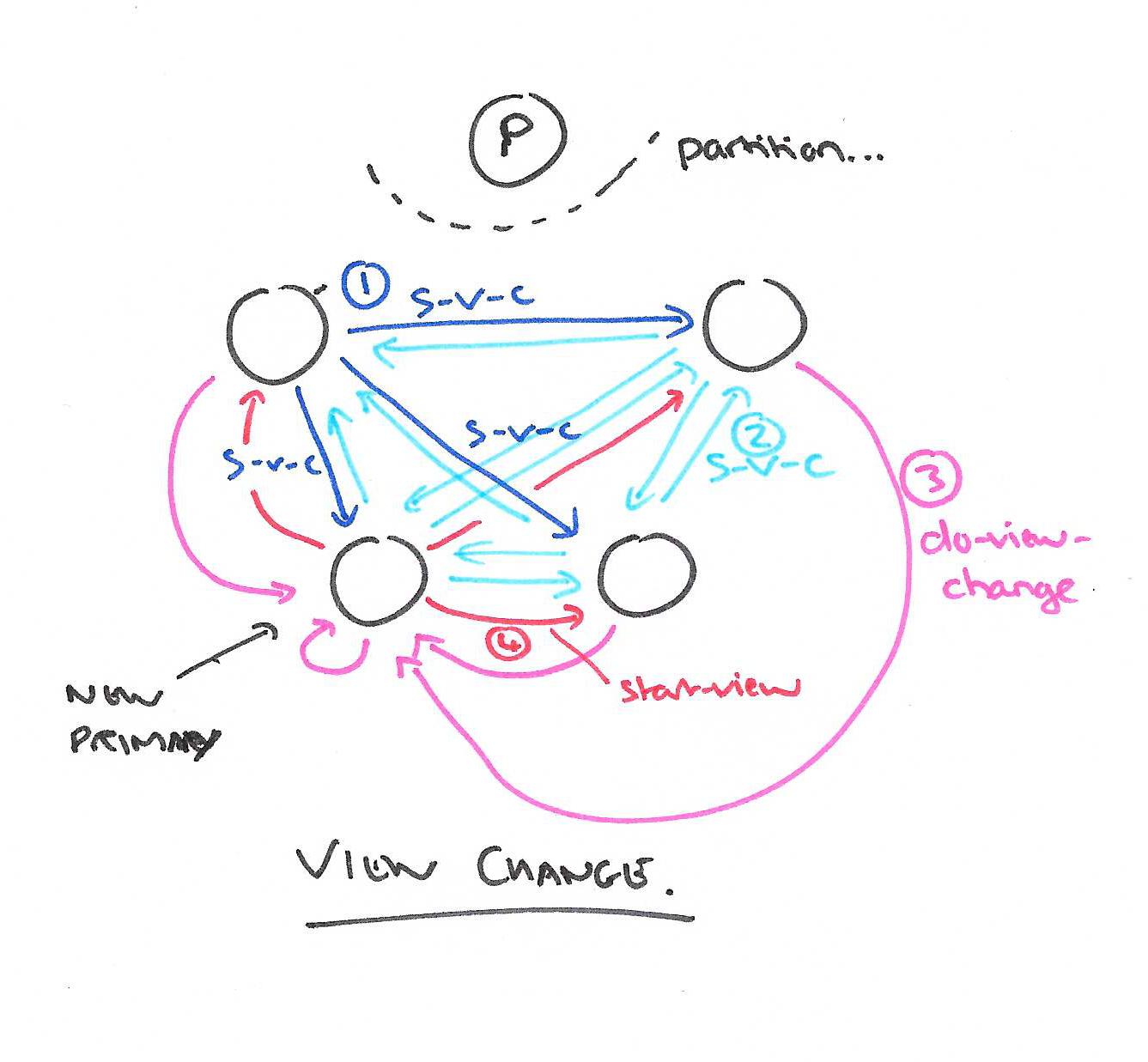
- A replica that independently notices the need for a view change (that is, it hasn’t been told via a message from another replica) advances its view-number, sets its status to view-change, and sends a start-view-change message to all other replicas.
-
When a replica receives a start-view-change message with a given view-number it compares the view-number to its own. If the view-number is higher than its own, it sends start-view-change messages to all replicas with this new view-number as above. If the view-number matches its own, it sends a do-view-change message to the new primary. (Remember, we already know who the new primary is expected to be). As part of the do-view-change message the replica also sends its critical state: the log, most recent operation-number and commit-number, and the number of the last view in which its status was normal.
-
When the new primary has received f+1 do-view-change messages (including from itself), it updates its state to the most recent from the group (there are precise rules – see the full paper for details), and initiates a new view. It does this by setting its state to normal and sending start-view messages to the other replicas. The start-view messages include the most recent state.
At this point the new primary can start processing messages again.
When a replica receives a start-view message it updates its state based on that contained in the message, and sets its status to normal. To get back in sync, the replica sends prepare-ok messages to the new primary for any uncommited operations in its log, and executes in order all operations known to be committed that it hasn’t executed previously.
The protocol described has a small number of steps, but big messages. We can make these messages smaller, but if we do, there is always a chance that more messages will be required. A reasonable way to get good behavior most of the time is for replicas to include a suffix of their log in their DOVIEWCHANGE messages. The amount sent can be small since the most likely case is that the new primary is up to date. Therefore sending the latest log entry, or perhaps the latest two entries, should be sufficient. Occasionally, this information won’t be enough; in this case the primary can ask for more information, and it might even need to first use application state to bring itself up to date.
Recovery
When a replica recovers after a crash it cannot participate in request processing and view changes until it has a state at least as recent as when it failed. If it could participate sooner than this, the system can fail.
One way of achieving this is to synchronously persist state to disk during normal operation, but this will slow down the whole system. Because VR replicates state at other replicas, introducing a recovery protocol enables state to be fetched over the network, which works well so long as replicas are failure indepenent. Unlike the original VR paper’s proposed scheme, the version presented here does not require writing to disk even during a view change.
- The recovering replica creates a new nonce and sends a recovery message including this nonce to all other replicas.
- Only replicas in the normal state respond to this message. The primary will also send its state as part of the response, backups just send an acknowledgement including the nonce.
- When the replica has received f+1 responses with its nonce, including one from the primary, it updates its state based on the primary’s message and changes state back to normal.
To make recovery more efficient (avoid the need to transfer all of the log state), checkpointing can be introduced. This has to be done in conjunction with the service running on top of VR, because the core VR algorithms know nothing of the nature of this state.
Our solution to this problem uses checkpoints and is based on our later work on Byzantine-fault tolerance. Every O operations the replication code makes an upcall to the application, requesting it to take a checkpoint; here O is a system parameter, on the order of 100 or 1000. To take a checkpoint the application must record a snapshot of its state on disk (background writes are fine here); additionally it records a checkpoint number, which is simply the op-number of the latest operation included in the checkpoint.
Application state being fetched from another replica can be efficiently managed using a Merkle tree to bring across only the changed portions from that already known to the recovering replica. Once the recovering node has all the state up to its most recent checkpoint, it can initiate the recovery protocol including the operation-number as of its checkpoint – the primary then transfers only the log from that point on.
Changing Epochs
The approach to handling reconfigurations is as follows. A reconfiguration is triggered by a special client request. This request is run through the normal case protocol by the old group. When the request commits, the system moves to a new epoch, in which responsibility for processing client requests shifts to the new group. However, the new group cannot process client requests until its replicas are up to date: the new replicas must know all operations that committed in the previous epoch. To get up to date they transfer state from the old replicas, which do not shut down until the state transfer is complete.
To accomodate epochs, the view change and recovery protocols are modified so that they do not accept messages from epochs earlier than their own current epoch.
The basic protocol should look familiar by now: after a client has requested an epoch change operation the primary logs it and sends out prepare messages. Replicas respond with prepare-ok messages, and once the primary has f of them, it transitions to a new epoch by sending a start-epoch message. Within the new epoch, the view number is reset back to zero. New members must transfer state from existing replicas to bring themselves up to speed. Members being decommissioned continue processing for a short while:
Replicas being replaced respond to state transfer requests from replicas in the new group until they receive f’ + 1 EPOCHSTARTED messages from the new replicas, where f’ is the threshold of the new group. At this point the replica being replaced shuts down.
While the system is moving from one epoch to the next it does not accept any new requests. This delay can be reduced by ‘warming’ up new nodes by transfering the state to them ahead of the reconfiguration.

Hi,
Great article !!!
I’ ve two questions:
Do you know if exist some blockchain implementation for this consensus or only is a theory that belong to crash failure consensus?
Cachin in the article “Blockchain consensus protocols in the wild” mention that any blockchain is an state machine. However, this concept in your analisys of “SoK: Consensus in the age of blockchain” is only associated to crash failure consensus. Then, what do you think about consider any blockchain implementation like a state machine?
Regards