Natural language understanding (almost) from scratch Collobert et al. Journal of Machine Learning Research 2011
Having spent much of last week looking at non-goal driven dialogue systems trained end-to-end, today it’s time to turn our attention to some of the building blocks of natural language processing that a chatbot can take advantage of if you’re capturing intent (for example, to initiate actions) or generating your own responses.
Collobert et al. describe four standard NLP tasks, each of which has well established benchmarks in the community. As of 2011, the state-of-the-art in these tasks used researcher discovered task-specific intermediate representations (features) based on a large body of linguistic knowledge. The authors set out to build a system that could excel across multiple benchmarks, without needing task-specific representations or engineering.
Our desire to avoid task-specific engineered features led us to ignore a large body of linguistic knowledge. Instead we reach good performance levels in most of the tasks by transferring intermediate representations discovered on large unlabeled datasets. We call this approach “almost from scratch” to emphasize the reduced (but still important) reliance on a priori NLP knowledge.
And yes, the neural networks once again turn out to learn as good or better representations all by themselves than human experts can design by hand. Though a little bit of human guidance adds the icing on the cake.
Let’s briefly look at the four NLP building blocks under examination, before studying how Collobert et al. constructed a neural network to excel at them.
Four foundational NLP tasks
Part-of-speech tagging (POS), labels each word with a tag that indicates its syntactic role in a sentence: for example, noun, verb, adverb and so on. We’re pretty good at POS tagging, with the system of Shen et al. 2007 achieving 97.33% accuracy. The overall system built by the authors in this paper is called SENNA (Semantic/Syntactic Extraction using a Neural Network Architecture). SENNA ultimately achieves 97.29% accuracy, but does over the benchmark in 4s using 32MB of RAM, whereas Shen et al.’s system needs 833s and 2.2GB of RAM.
Chunking labels phrases or segments within a sentence with tags that indicate their syntactic role: for example, noun phrase (NP) or verb phrase (VP).
Each word is assigned only one unique tag, often encoded as a begin-chunk (e.g. B-NP) or inside-chunk tag (e.g. I-NP)..
On the CoNLL benchmark, Shen and Sarkar (2005) achieved an “F1” score of 95.23% in 2005. SENNA achieves 94.32%.
Named-entity Recognition (NER) labels recognised entities within the sentence. For example, as a person, location, date, time, company and so on. “As in the chunking task, each word is assigned a tag prefixed by the beginning or inside of an entity.” Ando and Zhang (2005) achieved an F1 score of 89.31%. SENNA achieves 89.59%.
Semantic-role labeling (SRL) “gives a semantic role to a syntactic constituent of a sentence.”
In the PropBank (Palmer et al., 2005) formalism one assigns roles ARG0-5 to words that are arguments of a verb (or more technically, a predicate) in the sentence, e.g. the following sentence might be tagged “[John]ARG0 [ate]REL [the apple]ARG1”, where “ate” is the predicate. The precise arguments depend on a verb’s frame and if there are multiple verbs in a sentence some words might have multiple tags. In addition to the ARG0-5 tags, there there are several modifier tags such as ARGM-LOC (locational) and ARGM-TMP (temporal) that operate in a similar way for all verbs.
A typical SRL system may involve several stages: producing a parse tree, identifying which parse tree nodes represent the arguments of a given verb, and then classifying them to compute the final labels. Koomen et al. (2005) achieved a 77.92% F1 score. SENNA achieves 75.49%, but 10x faster and using an order-of-magnitude less RAM.
POS is the simplest of these tasks, and SRL the most complex. The more complex the task, the more feature engineering has traditionally been required to perform well in it.
Doing away with hand-engineered features
All the NLP tasks above can be seen as tasks assigning labels to words. The traditional NLP approach is: extract from the sentence a rich set of hand-designed features which are then fed to a standard classification algorithm, e.g. a Support Vector Machine (SVM), often with a linear kernel. The choice of features is a completely empirical process, mainly based first on linguistic intuition, and then trial and error, and the feature selection is task dependent, implying additional research for each new NLP task. Complex tasks like SRL then require a large number of possibly complex features (e.g., extracted from a parse tree) which can impact the computational cost which might be important for large-scale applications or applications requiring real-time response. Instead, we advocate a radically different approach: as input we will try to pre-process our features as little as possible and then use a multilayer neural network (NN) architecture, trained in an end-to-end fashion.
Network Architecture
Collobert et al. experimented with two different network architectures: one using a sliding window approach to combining words, and one using a convolutional network layer. In both cases, these combining layers are fed by word vectors. This paper pre-dates the work by Milokov et al. on word vectors, and instead looks up a one-hot word vector representation in a series of lookup tables (one for each word feature) and concatenates the results to give the final vector representation. The lookup table feature vectors are in turn trained by backpropagation. I found the paper a little light on the details of these features and their training (there are various snippets of information scattered across the 47 pages). However, the authors say " Ideally, we would like semantically similar words to be close in the embedding space represented by the word lookup table: by continuity of the neural network function, tags produced on semantically similar sentences would be similar." This is precisely the property of the word vectors introduced by Milokov et al., and in GloVe, and my assumption is that if this work was being reproduced today, those word vectors would be used in place of the lookup table mechanism. It wouldn’t surprise me if there are papers investigating exactly that… if you know of them, please post links/refs in the comments!
The windowing approach assumes that the tag of a word depends mostly on the words surrounding it, and creates a combined feature vector by concatenating the feature vector of the target word and its k neighbours on each side. The overall network looks like this:

The final layer of the network has one node for each candidate tag, each output is interpreted as the score for the associated tag.
The windowing approach performs well for the first three tasks, but does not do so well for SRL. The issue here is that the correct tag for a word may depend on a verb in the sentence outside of the current window. The convolutional network architecture is introduced to try and address this:
It successively takes the complete sentence, passes it through the lookup table layer (1), produces local features around each word of the sentence thanks to convolutional layers, combines these feature into a global feature vector which can then be fed to standard affine layers (4). In the semantic role labeling case, this operation is performed for each word in the sentence, and for each verb in the sentence. It is thus necessary to encode in the network architecture which verb we are considering in the sentence, and which word we want to tag.
(We’ll see tomorrow an approach that uses LSTMs to provide the needed memory).

During training, we need a scoring function to tell the network how well it is doing. A simple approach (described in the paper as ‘word-level log-likelihood’) is just to look at the scores for each word independently. However…
In tasks like chunking, NER or SRL we know that there are dependencies between word tags in a sentence: not only are tags organized in chunks, but some tags cannot follow other tags. Training using a word-level approach discards this kind of labeling information. We consider a training scheme which takes into account the sentence structure: given the predictions of all tags by our network for all words in a sentence, and given a score for going from one tag to another tag, we want to encourage valid paths of tags during training, while discouraging all other paths.
This scoring system is called ‘sentence-level log-likelihood.’
Using multi-task learning , it is possible to train the network on all four tasks at the same time. “While we find worth mentioning that MTL can produce a single unified architecture that performs well for all these tasks, no (or only marginal) improvements were obtained with this approach compared to training separate architectures per task.”
(Almost)
Results so far have been obtained by staying (almost) true to our from scratch philosophy. We have so far avoided specializing our architecture for any task, disregarding a lot of useful a priori NLP knowledge. We have shown that, thanks to large unlabeled datasets, our generic neural networks can still achieve close to state-of-the-art performance by discovering useful features. This section explores what happens when we increase the level of task-specific engineering in our systems by incorporating some common techniques from the NLP literature. We often obtain further improvements. These figures are useful to quantify how far we went by leveraging large datasets instead of relying on a priori knowledge.
(“Almost” here refers to the basic pre-processing of the raw input words, as opposed to starting with no knowledge of words at all for example, and proceeding character by character).
- Adding a suffix feature (the last two characters of every word) gave a small improvement – 0.09% – on POS. The insight for this is that word suffixes in many Western languages are strong predictors of the syntactic function of a word.
- Using a dictionary called a gazetteer containing well known named entities helps with NER (surprise!), improving performance from 88.67% to 89.59%.
- Cascading results (using POS labels as input to chunking, and chunking results as input to SRL) results in modest improvements ( < 1%).
- All of the prior state-of-the-art systems for SRL use parse trees, whereas the approach described in this paper so far does not. Adding parse tree input features did make a meaningful ( > 1%) difference to SRL performance.
The final optimised version of the system is called SENNA (and it is SENNA’s results that I reported at the top of this piece). The features ultimately included in SENNA are:
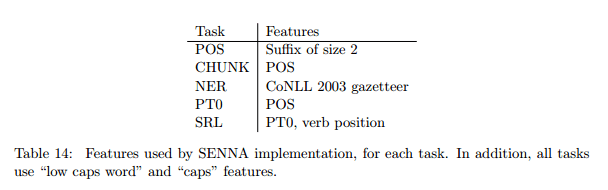
Where PT0 is a Penn Treebank parse tree, and LM2 is a language model with a dictionary of 130,000 words.

4 thoughts on “Natural language understanding (almost) from scratch”
Comments are closed.