End-to-end learning of semantic role labeling using recurrent neural networks Zhou & Xu International joint conference on Natural Language Processing, 2015
Collobert’s 2011 paper that we looked at yesterday represented a turning point in NLP in which they achieved state of the art performance on part-of-speech tagging (POS), chunking, and named entity recognition (NER) using a neural network in place of expert crafted systems and algorithms. For the semantic role labeling (SRL) task though, Collobert et al. had to resort to including parsing features. With today’s paper, that final hold-out task also falls to the power of neural networks, and the authors (from Baidu research) achieve state-of-the-art performance taking only original text as input features. They out-perform previous state-of-the-art systems, that were based on parsing results and feature engineering, and which relied heavily on linguistic knowledge from experts.
Zhou & Xu’s solution uses an 8 layer bi-directional RNN (an LSTM to be precise). Using an LSTM architecture enables cells to store and access information over long periods of time. We saw last week the technique of processing sequences both forward and backward, and combining the results in some way (e.g. concatenation):
In this work, we utilize the bi-directional information in another way. First a standard LSTM processes the sequence in (a) forward direction. The output of this LSTM layer is taken by the next LSTM layer as input, processed in (the) reverse direction. These two standard LSTM layers compose a pair of LSTMs. Then we stack LSTM layers pair after pair to obtain the deep LSTM model. We call this topology a deep bi-directional LSTM (DB-LSTM) network. Our experiments show that this architecture is critical to achieve good performance.
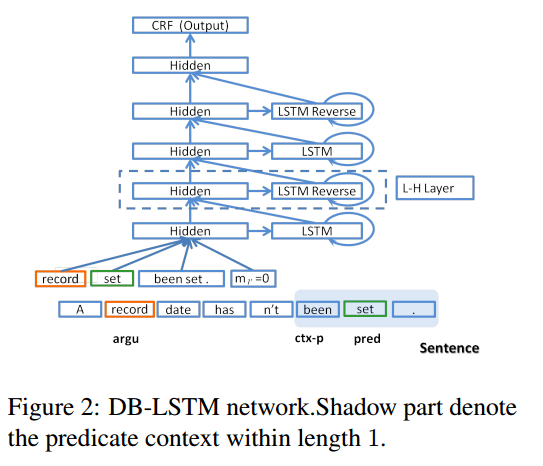
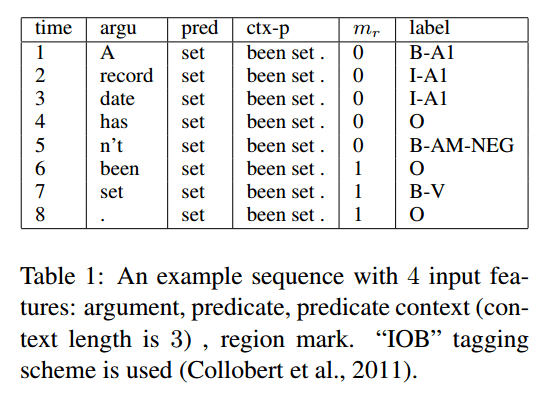
Sentences are processed word by word. The model uses four features:
- predicate (or verb) – if a sentence has multiple predicates it will be processed multiple times, once for each
- argument – the word currently being processed as we move along the sentence
- predicate-context (ctx_p), the n words either side of the predicate
- region-mark – a boolean (0 or 1) value indicating whether the current argument falls within the predicate-context region.
The output is is the semantic role of each word. For the sentence “A record date hasn’t been set.”, this results in the following feature inputs and outputs:
Pre-trained word representations are used for the argument and predicate word representations.
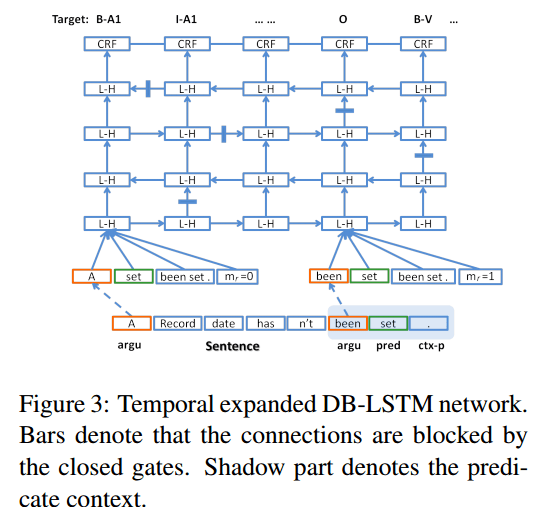
The above four features are concatenated to be the input representation at the time step for the following LSTM layers… As in traditional methods, we employ CRF (Lafferty et al., 2001) on top of the network for the final prediction. It takes the representations provided by the last LSTM layer as input to model the strong dependence among adjacent tags.
Here’s a temporal expanded version of the model (4 layers shown), with L-H representing a hidden LSTM layer.
Contribution of features and layers to model performance
Overall the model is evaluated on the CoNLL-2005 shared task and achieved an F1 score of 81.07 (outperforming the previous state-of-the-art). On CoNLL-2012 an even better F1 score of 81.27 was obtained. It’s also efficient, capable of processing 6.7K tokens per second.
A very nice evaluation section builds up to the full solution, making clear the contributions made by different parts of the system:
- A small model with only one 32-node LSTM layer, randomly initialised word embeddings, and a predicate context length of 1 (no region mark feature) gave F1 = 49.44.
- With predicate context length 5 the same model improves to F1 = 56.85.
- Adding the region mark feature then improves F1 to 58.71
- Switching to pre-trained word embeddings improved F1 to 65.11
- Adding a reversed LSTM layer improves F1 to 72.56
- Moving to 4, 6, and 8 layers respectively increases F1 to 75.74, 78.02, and 78.28.
- Increasing the size of the hidden layers from 32 to 64 and then 128 nodes gives an F1 score of 80.28.
- Tuning the meta-parameters (relaxing weight decay and decreasing learning rate) gives the final results of 81.07 on CoNLL-2005 and 81.27 on CoNLL-2012.
In our experiments, increasing the model depth is the major contribution to the final improvement. With (a) deep model, we achieve strong ability of learning semantic rules without worrying about over-fitting even on such a limited training set… It is encouraging to see that deep learning models with end-to-end training can outperform traditional models on tasks which are previously believed to heavily depend on syntactic parsing. However, we recognize that semantic role labeling itself is an intermediate step towards the language problems we really care about, such as question-answering, information extraction, etc. We believe that end-to-end training with some suitable deep structure yet to be invented might be proven to be effective at solving these problems.

We tried to implement this paper here: https://market.mashape.com/pragmacraft/semantic-role-labeling
We tried to implement this paper here: https://market.mashape.com/pragmacraft/semantic-role-labeling