Encapsulation of parallelism in the volcano query processing system – Graefe ’89.
You may have picked up on the throwaway line in the Impala paper: “The execution model is the traditional Volcano-style with Exchange operators.” So what exactly is the ‘traditional Volcano style’, and what are ‘exchange operators’? Today’s choice is the paper that first introduced the concept, back in 1989.
A uniform interface between operators, e.g., scan, select, or join, makes Volcano extensible by new operators. It includes an exchange operator that allows intra-operator parallelism on partitioned datasets and both vertical and horizontal inter-operator parallelism. All other operators are programmed as for single- process execution; the exchange operator encapsulates all parallelism issues, including the translation between demand-driven dataflow within processes and data-driven dataflow between processes, and therefore makes implementation of parallel database algorithms significantly easier and more robust.
In Volcano, queries are expressed as complex algebra expressions, and the operators are query processing algorithms. Every operator is implemented as an iterator per Hellerstein et al: ‘Most modern query executors employ the iterator model that was used in the earliest relational systems’ (‘Architecture of a Database System‘). The iterators support a simple open-next-close protocol. An iterator can hold internal state, so that one algorithm (operator) can be used multiple times in a query.
An operator does not need to know what kind of operator produces its input, and whether its input comes from a complex query or from a simple file scan. We call this concept anonymous inputs or streams… Streams represent the most efficient execution model in terms of time (overhead for sychronizing operators) and space (number of records that must reside in memory concurrently) for single process query evaluation.
Given this, the way that Volcano introduces parallelism is very simple: just introduce (transparently) a new operator, called the exchange operator at any desired point in a query tree.
The module responsible for parallel execution and synchronization is the exchange iterator. Notice that it is an iterator with open, next, and close procedures; therefore, it can be inserted at any one place or at multiple places in a complex query tree.
The exchange operator can be used to implement pipelined parallelism (called vertical parallelism in the paper), bushy parallelism (processing different subtrees of a complex query tree in parallel), and intra-operator parallelism (partitioning the dataset and processing partitions in parallel for a single operator).
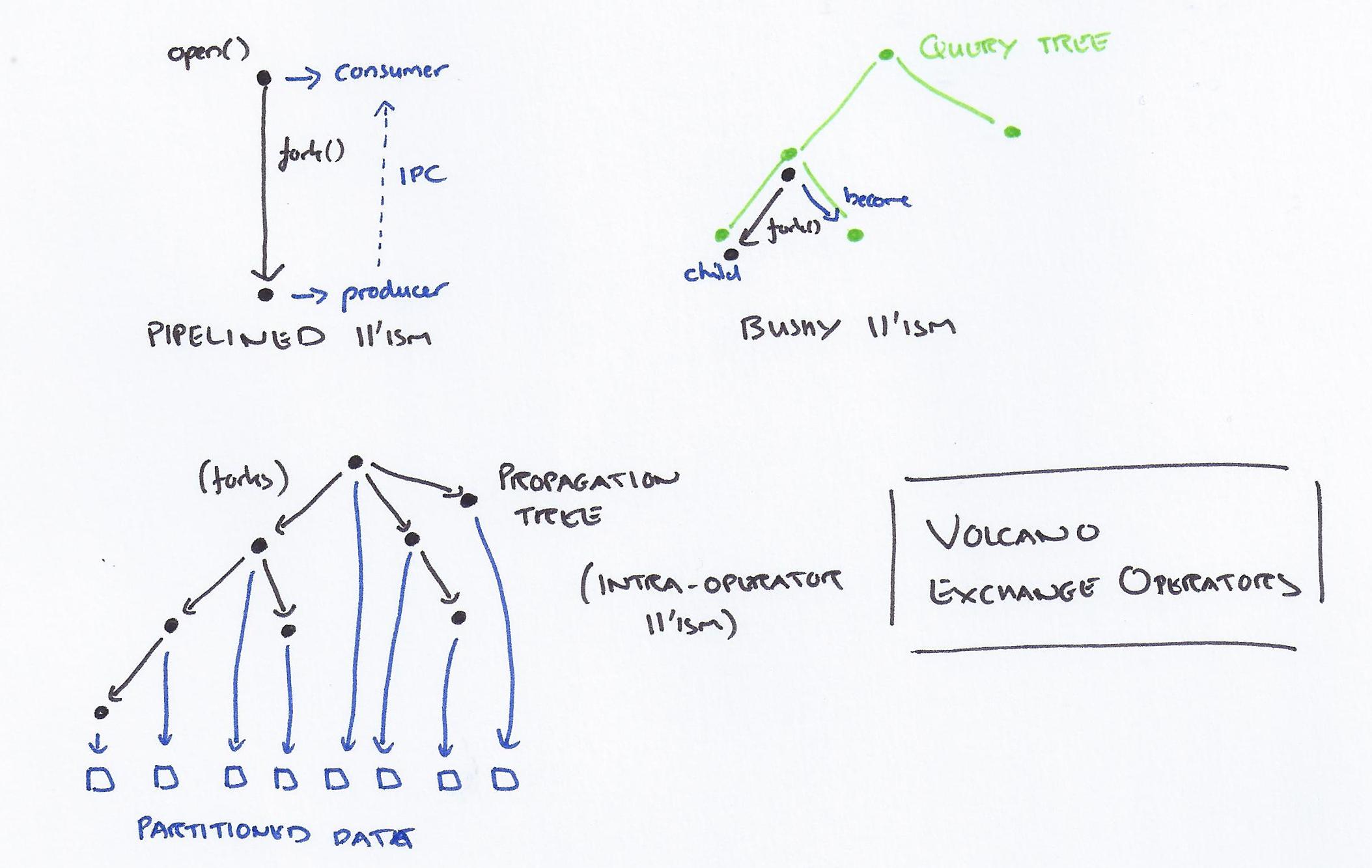
For pipelined parallelism, the open procedure of the exchange operator forks a new process, with the parent process acting as the consumer, and the child process as the producer.
The exchange operator in the consumer process acts as a normal iterator, the only difference from other iterators is that it receives its input via inter-process communication.
Bushy parallelism is also implemented via simple exchange operator insertion:
Bushy parallelism can easily be implemented by inserting one or two exchange operators into a query tree. For example, in order to sort two inputs into a merge-join in parallel, the first or both inputs are separated from the merge-join by an exchange operation. The parent process turns to the second sort immediately after forking the child process that will produce the first input in sorted order. Thus, the two sort operations are working in parallel.
For intra-operator parallelism a process group operates on partitions in parallel. When the query tree is opened the first process is the master. A propagation tree then forks the other processes needed (one per partition):
When we changed our initial implementation from forking all producer processes by the master to using a propagation tree scheme, we observed significant performance improvements. In such a scheme, the master forks one slave, then both fork a new slave each, then all four fork a new slave each, etc. This scheme has been used very effectively for broadcast communication and synchronization in binary hypercubes.
Whereas normal operators use a demand-driven dataflow (iterators calling next), exchanges use data-driven dataflows (eager evaluation). This removes some communication overhead. Flow control / back-pressure can be added ‘using a additional semaphore’ if producers are significantly faster than consumers.
A variation on this theme was implemented as part of a parallel sort algorithm:
When the exchange operator is opened, it does not fork any processes but establishes a communication port for data exchange. The next operation requests records from its input tree, possibly sending them off to other processes in the group, until a record for its own partition is found. This mode of operation also makes flow control obsolete. A process runs a producer (and produces input for the other processes) only if it does not have input for the consumer. Therefore, if the producers are in danger of overrunning the consumers, none of the producer operators gets scheduled, and the consumers consume the available records.
The key benefit of the exchange operator technique is that is allows query processing algorithms to be coded for single-process execution but run in a highly parallel environment without modifications. It’s a small step from the single host, multiple process model described in the paper to a multiple node parallel processing engine.

5 thoughts on “Encapsulation of parallelism in the Volcano query processing system”
Comments are closed.