Impala: A modern, open-source SQL engine for Hadoop – Kornacker et al . 2015 (Cloudera*)
This is post 4 of 5 in a series looking at the latest research from CIDR’15. Also in the series so far this week: ‘The missing piece in complex analytics‘, ‘WANalytics, analytics for a geo-distributed, data intensive world‘, and ‘Liquid: Unifying nearline and offline big data integration‘.
The use case should be starting to feel familiar by now: low-latency BI/analytic workloads at scale that aren’t catered for by Hadoop’s batch-oriented frameworks. Now that the industry has figured out that SQL might be useful after all for these workloads (Goes Around, Comes Around – Stonebraker), the race is on to provide lower-latency SQL querying and analytic capabilities on top of Hadoop. Which really means ‘on top of HDFS’ plus some optional integrations with other parts of the Hadoop ecosystem. Impala is Cloudera’s answer for these workloads.
Impala is written in Java (front-end and query planner) and C++ (back-end), can read the majority of widely-used file formats (Parquet, Avro, RCFile), and utilizes standard Hadoop components under the covers.
When it comes to SQL support, Impala’s is CRAP. I should explain what I mean ;). The database community seems to have an affinity for derogatory acronyms! First off there’s CRUD:
- CRUD – a deposit or coating of refuse or of an impure or alien substance; muck. (aka. Create, Read, Update, Delete).
Then there’s the new breed of CRAP data:
- CRAP – excrement ! (aka Create, Read, and APpend, as coined by an ex-colleague at VMware, Charles Fan – note the absence of update and delete capabilities).
Due to the limitations of HDFS as a storage manager, Impala does not support UPDATE or DELETE, and essentially only supports bulk insertions (INSERT INTO … SELECT …)
You can partition a table on creation
CREATE TABLE T (...) PARTITIONED BY (day int, month int)
LOCATION '[hdfs-path]' STORED AS PARQUET;
But “note that this form of partitioning does not imply a collocation of the data of an individual partition: the blocks of the data files of a partition are distributed randomly across HDFS data nodes.”
Architecture Overview
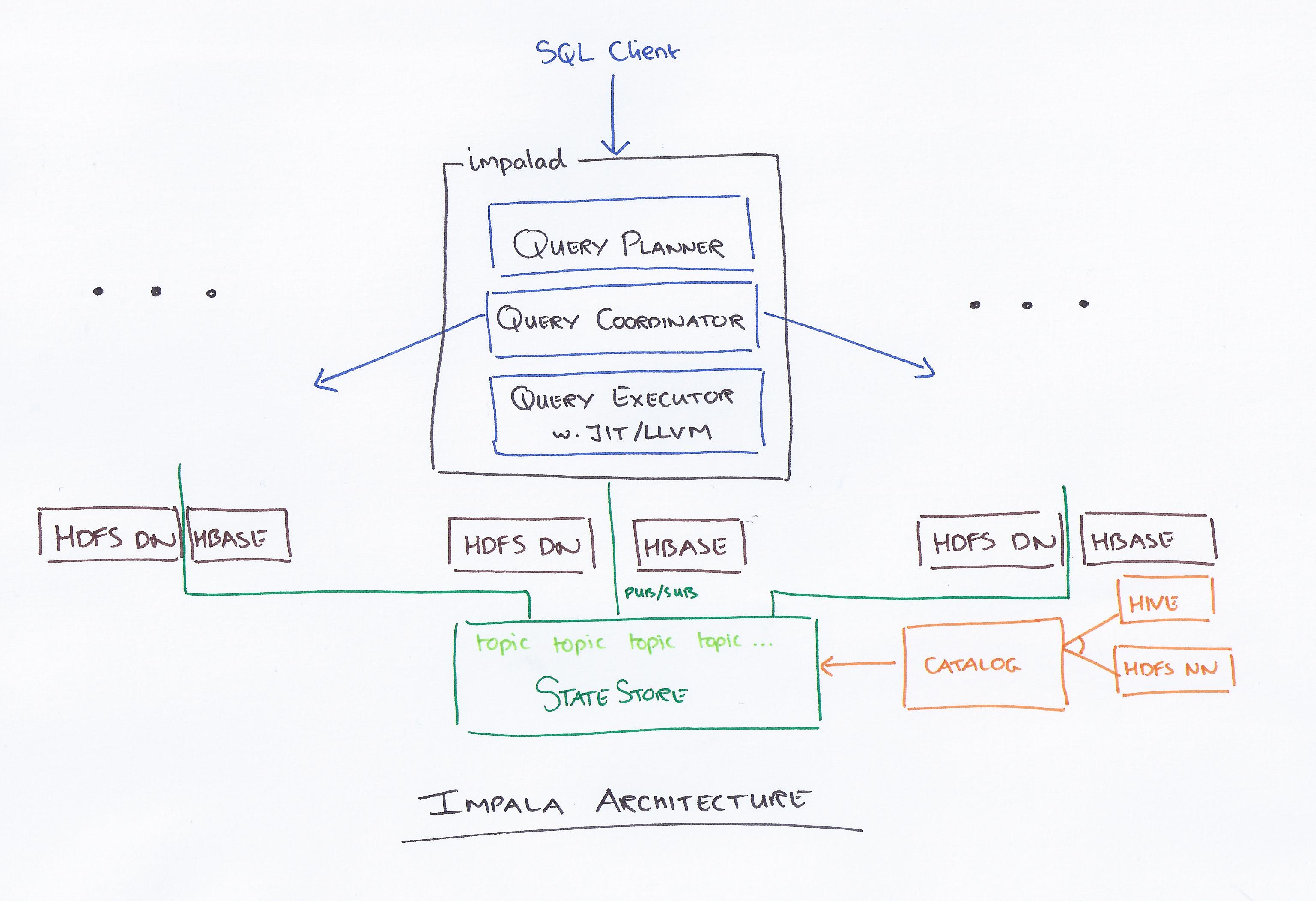
Impala is made up of three services. The main Impala daemon (impalad) accepts queries and orchestrates their execution, and also executes individual query fragments on behalf of other Impala daemons. Impala daemons are symmetric and can all operate in all roles. There is one impalad running on every data node in the cluster, which lets Impala take advantage of data locality.
The Statestore daemon is a metadata publish-subscribe system (a purpose-built pub-sub broker). It publishes metadata to all Impala processes. There is a single statestored instance.
Although there is only a single statestore process in existing Impala deployments, we have found that it scales well to medium sized clusters and, with some configuration, can serve our largest deployments. The statestore does not persist any metadata to disk: all current metadata is pushed to the statestore by live subscribers (e.g. load information).
Which of course begs the question, what happens if the single statestore instance that doesn’t persist anything to disk fails?
There is no built-in failover mechanism in Impala, instead deployments commonly use a retargetable DNS entry to force subscribers to automatically move to the new process instance.
The statestore state is then recreated during the initial subscriber registration phase. (Which sounds like it might be susceptible to flooding, but no further details are given on mechanisms that may be in place to prevent this).
The Catalog daemon serves as the catalog repository and metadata access gateway.
Impala’s catalog service serves catalog metadata to Impala daemons via the statestore broadcast mechanism, and executes DDL operations on behalf of Impala daemons. The catalog service pulls information from third-party metadata stores (for example, the Hive Metastore or the HDFS Namenode), and aggregates that information into an Impala-compatible catalog structure.
The catalog service only loads a skeleton entry for each table it discovers on startup. More detailed table metadata is loaded lazily in the background.
Front end processing
The frontend is a Java SQL parser and cost-based query optimizer.
In addition to the basic SQL features (select, project, join, group by, order by, limit), Impala supports inline views, uncorrelated and correlated subqueries (that are rewritten as joins), all variants of outer joins as well as explicit left/right semi- and anti-joins, and analytic window functions.
The query plan is constructed in the same way as several other systems we have looked at: first a local (single node) plan is created, and then this is optimized for distribution (parallelization and fragmentation).
In the first phase, the parse tree is translated into a non-executable single-node plan tree, consisting of the following plan nodes: HDFS/HBase scan, hash join, cross join, union, hash aggregation, sort, top-n, and analytic evaluation. This step is responsible for assigning predicates at the lowest possible plan node, inferring predicates based on equivalence classes, pruning table partitions, setting limits/offsets, applying column projections, as well as performing some cost-based plan optimizations such as ordering and coalescing analytic window functions and join reordering to minimize the total evaluation cost. Cost estimation is based on table/partition cardinalities plus distinct value counts for each column; histograms are currently not part of the statistics. Impala uses simple heuristics to avoid exhaustively enumerating and costing the entire join-order space in common cases.
The goal of the second phase is to minimize data movement and maximize scan locality. This is also where the join strategies are decided (broadcast or partitioned).
Impala chooses whichever strategy is estimated to minimize the amount of data exchanged over the network, also exploiting existing data partitioning of the join inputs.
Back end processing
Impala’s backend is written in C++ with an execution model styled after Volcano. Execution is pipelined wherever possible which minimizes intermediate memory consumption. Tuples are held in memory by row.
Key to Impala’s performance is LLVM-based code generation, giving performance gains of 5x or more.
(LLVM) allows applications like Impala to perform just-in-time (JIT) compilation within a running process, with the full benefits of a modern optimizer and the ability to generate machine code for a number of architectures, by exposing separate APIs for all steps of the compilation process.
Code is generated for ‘inner loop’ functions that could be executed many times (billions!) for a given query. Without code generation, general purpose routines inevitably contain some inefficiencies. Likewise, when the type of an object instance is known at compile time, code generation can replace a virtual function call with a direct one.
Overall, JIT compilation has an effect similar to custom-coding a query. For example, it eliminates branches, unrolls loops, propagates constants, offsets and pointers, inlines functions. Code generation has a dramatic impact on performance. For example, in a 10-node cluster with each node having 8 cores, 48GB RAM and 12 disks, we measure the impact of codegen. We are using an Avro TPC-H database of scaling factor 100 and we run simple aggregation queries. Code generation speeds up the execution by up to 5.7x, with the speedup increasing with the query complexity.
To get the I/O performance needed, Impala uses an HDFS feature called ‘short-circuit local reads.’ With 12 disks, Impala has been measured as capable of sustaining I/O at 1.2 GB/sec. The recommended storage format is Parquet, “co-developed by Twitter and Cloudera with contributions from Criteo, Stripe, Berkeley AMPlab and LinkedIn.” Parquet was inspired by Dremel’s ColumnIO format and “consistently outperforms by up to 5x all the other formats.”
Resource management
YARN’s centralized architecture is too slow for Impala, so the Impala team implemented an additional admission control system that sits in front of it called Llama (Low-Latency Application MAster). It implements resource caching, gang scheduling, and incremental allocation changes.
If resources for the resource pool are available in Llama’s resource cache, Llama returns them to the query immediately. This fast path allows Llama to circumvent YARN’s resource allocation algorithm when contention for resources is low.
LinkedIn also raised the issue of resource isolation in yesterday’s paper. They use YARN as do the Impala team. Although Llama helps, there is more to be done in this area:
Resource management in an open multi-tenancy environment, in which Impala shares cluster resource with other processing frameworks such as MapReduce, Spark, etc., is as yet an unsolved problem. The existing integration with YARN does not currently cover all use cases, and YARN’s focus on having a single reservation registry with synchronous resource reservation makes it difficult to accommodate low-latency, high-throughput workloads. We are actively investigating new solutions to this problem.
See Quasar for some recent research tackling this problem:
(*) Accel Partners are an investor in Cloudera. I like to think this in no way influenced my technical review of the paper.

4 thoughts on “Impala: a modern, open-source SQL engine for Hadoop”
Comments are closed.