Liquid: Unifying Nearline and Offline Big Data Integration – Fernandez et al. 2015
This is post 3 of 5 in a series looking at the latest research from the CIDR ’15 conference. Also in the series so far this week: ‘The missing piece in complex analytics‘ and ‘WANalytics: analytics for a geo-distributed, data intensive world‘.
We argue that it is time to rethink the architecture of a data integration stack. Rather than using the legacy MapReduce/(H)DFS model for data integration, we describe Liquid – a new nearline data integration stack used at LinkedIn.
LinkedIn’s Liquid deployment runs in 5 datacenters and ingests over 50TB of input data a day, producing over 250TB of output (including replication). There are about 30 different clusters, comprising ~300 machines in total hosting over 25,000 topics and 200,000 partitions. Let’s take a look at why Liquid is needed, and how it works…
Web companies such as LinkedIn are dealing with very high volumes of append-only data, “which becomes expensive to integrate using proprietary, often hard-to-scale data warehouses.” (See Mesa for Google’s solution to the data-warehousing problem). So organizations create their own data integration stacks for storing data and serving it to back-end data processing systems.
Modern web companies have specialized data processing systems that can be classified as online, nearline, and offline. At LinkedIn, the resource distribution for back-end systems according to these classes is approximately 25%, 25%, and 50%, respectively. Online systems, e.g. for processing business transactions, are handled by front-end relational databases and serve results within milliseconds. Nearline systems typically operate in the order of seconds, and offline systems within minutes or hours.
Examples of nearline systems include those that query social graphs, search data, normalize data, or monitor change. The sooner they provide results, the higher the value to end users. With multiple stages in processing pipelines, the latency per stage starts to add up.
Fundamentally, DFS-based stacks do not support low-latency processing because they have a high overhead per stage: they are designed for coarse-grained data reads and writes.
Additional issues the authors cite with the DFS based approach include the need to support incremental processing (fine-grained access to data and explicit incremental state), and the need for resource isolation:
Despite recent efforts to control resources in clusters, it is challenging to maintain resource isolation during low latency processing without over-provisioning the infrastructure.
Liquid is designed for low latency, cost-effective, incremental processing with high availability and resource isolation. “It annotates data with metadata such as timestamps or software versions, which back-end systems can use to read from a given point. This rewindability property is a crucial building block for incremental processing and failure recovery.”
The well-known Lambda architecture was rejected since “developers must write, debug, and maintain the same processing code for both the batch and stream layers, and the Lambda architecture increases the hardware footprint.” Likewise the Kappa architecture, while it requires only a single processing path, “has a higher storage footprint, and applications access stale data while the system is re-processing data.”
Liquid has two cooperating layers: a messaging layer based on Apache Kafka, and a processing layer based on Apache Samza.
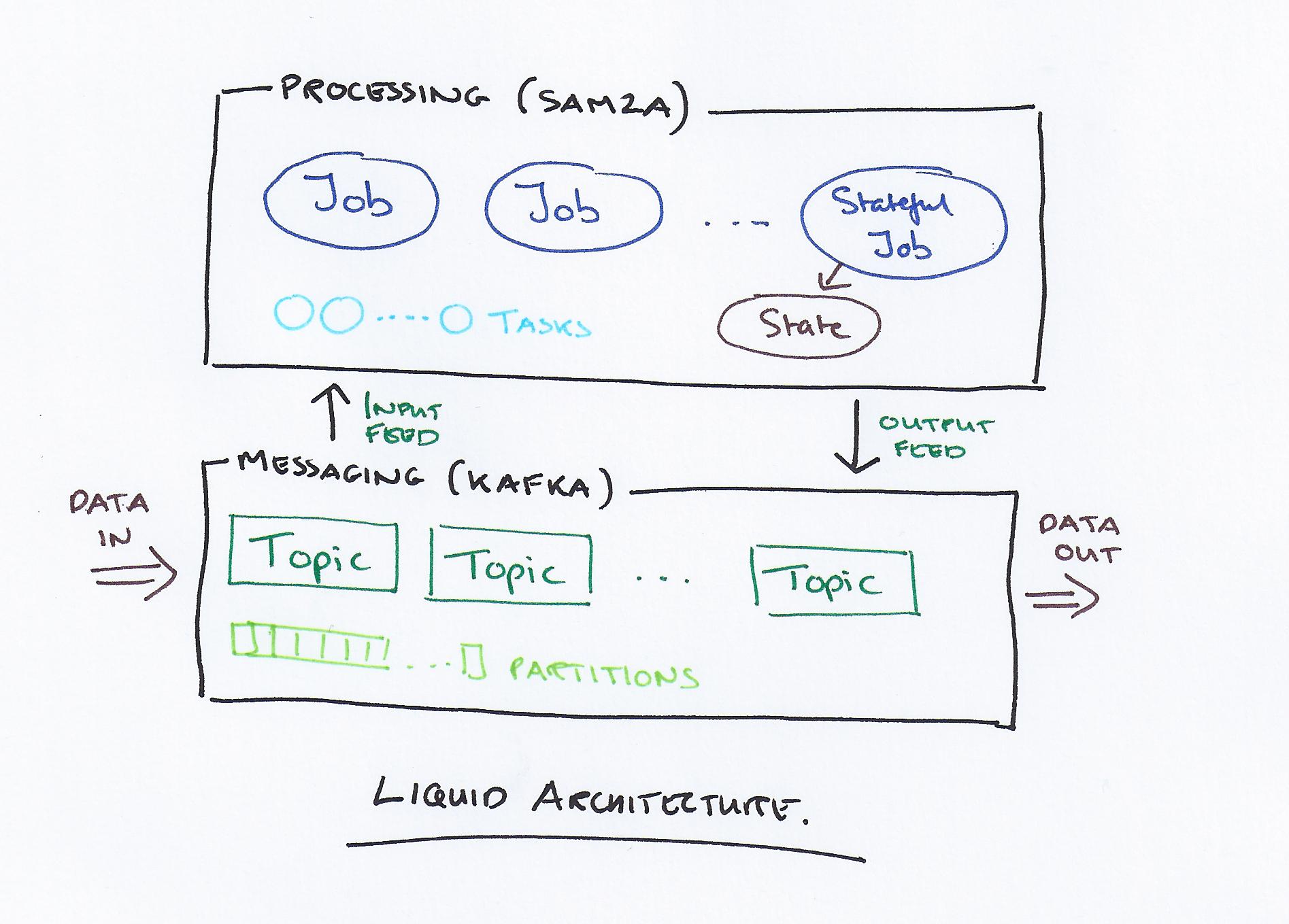
The processing layer (i) executes ETL-like jobs for different back-end systems according to a stateful stream processing model; (ii) guarantees service levels through resource isolation; (iii) provides low latency results; and (iv) enables incremental data processing. A messaging layer supports the processing layer. It (i) stores high-volume data with high availability; and (ii) offers rewindability, i.e. the ability to access data through metadata annotations.
The layers communicate through feeds (topics in a pub/sub model). There are raw data feeds, and derived data feeds – the latter contain lineage information which is stored by the messaging layer.
The goal of data integration is to make data available to an entire organization. Each team in an organization is only interested in consuming part of that data, and they only need to produce data of certain types. Therefore they should be able to do this while being unaware of other irrelevant data. A publish/subscribe model fits this requirement.
Topics are divided into partitions, which are distributed across a cluster of brokers. Topics are realized as distributed commit logs – each partition is append-only and keeps an ordered, immutable sequence of messages with a unique identifier called an offset.
The distributed commit log is a crucial design feature of the messaging layer: (i) its simplicity helps create a scalable and fault-tolerant system; and (ii) its inherent notion of order allows for fine-grained data access. While the append-only log only guarantees a total order of messages per topic-partition but not across partitions, we observe that, in practice, this is sufficient for most back-end applications.
Consumers can checkpoint their last consumed offsets to save their progress and facilitate recovery.
The processing layer executes jobs, which embody computation over streams. Jobs can be divided into tasks that process different partitions of a topic in parallel. Jobs can communicate with each other, forming a dataflow processing graph.
All jobs are decoupled by writing to and reading from the messaging layer, which avoids the need for a back-pressure mechanism. This is an important design-decision that improves the operational robustness of the system.
High-throughput writes are enabled by OS-level file system caching and an ‘anti-caching‘ design. The head of the log is maintained in memory for back-end systems that need low-latency access. High-throughput reads are supported by an incrementally maintained index file which records the chunks of the log at which requested offsets are stored. A log retention period bounds the amount of data that is stored per topic.
This [log retention] period is usually expressed in terms of time, e.g. one month’s worth of data, but for operational reasons it may also be configured as a maximum log size.
For applications that only require the last update with a given key, log compaction can periodically scan logs and discard all but the most recent data for each key.
All partitions handled by a lead broker are replicated across follower brokers. ZooKeeper is used to maintain the subset of followers above a configurable minimum up-to-date threshold, and leader election takes place from amongst this set in the event of leader failure.
The messaging layer provides at-least-once semantics, “there is an ongoing effort to design and implement support for exactly-once-semantics.” The processing layer uses Linux containers managed by Apache YARN, and to avoid frequent invocation of the garbage collector in the JVM, state is managed off-heap using RocksDB.
Some of the real-world use cases for Liquid at LinkedIn include:
- Data cleaning and normalization
- Site speed monitoring:
With Liquid, when a client visits a webpage, an event is created that contains a timestamp, the page or resource loaded, the time that it took to load, the IP address location of the requesting client and the content delivery network (CDN) used to serve the resource. These events are consumed by Liquid, which groups them by location, CDN, or other dimensions. Based on this data, Liquid can feed back-end applications that detect anomalies: e.g. CDNs that are performing particularly slowly, or increased loading times from specific client locations. Back-end applications can consume already pre-processed data that divides user events per session. As a result, back-end applications can detect anomalies within minutes as opposed to hours, permitting a rapid response to incidents.
- Call graph assembly – for dynamic web pages that are built from thousands! of REST calls. Liquid is used to to detect latency problems within seconds rather than hours. Each event produced by the REST calls is stored in the messaging layer with a unique id per user call (assigned by the front-end system). The processing layer processes these events to create the call graph. This is turn is used in production to monitor the site.
- Operational analysis of metrics, alerts, and logs.
Lots of companies use Kafka, but Storm seems to be more widely used than Samza for stream processing. Here’s what the authors have to say about Storm:
Systems such as Storm are general stream processing platforms that execute distributed dataflow graphs, but they do not support stateful processing. In contrast, Liquid’s processing layer implements a stateful stream processing model, as realized by streams such as SEEP, in order to support richer computation over continuous data.
Storm’s Trident interface is a higher-level abstraction on top of Storm that does add primitives for incremental processing and state. The paper makes no comment on Trident.
New kid on the block, but also not mentioned in the paper, is Spark Streaming which supports state. See the Spark Streaming + Kafka Integration Guide for information on using Spark Streaming and Kafka together.

3 thoughts on “Liquid: Unifying nearline and offline big data integration”
Comments are closed.