Architecture of a Database System – Hellerstein, Stonebraker & Hamilton, 2007.
This is a longer read (and hence a slightly longer write-up too) coming in at 119 pages, but it’s written in a very easy style so the pages fly by. It oozes wisdom and experience from every paragraph as Joe Hellerstein and Michael Stonebroker and James Hamilton (how’s that for some respected authorship!) take you through the architecture of a database system (circa. 2007) blending academic and industrial experience and insights. If those who don’t understand history are doomed to repeat it, then this is essential reading!
This paper presents an architectural discussion of DBMS design principles, including process models, parallel architecture, storage system design, transaction system implementation, query processor and optimizer architectures, and typical shared components and utilities…. For a number of reasons, the lessons of database systems architecture are not as broadly known as they should be.
The paper is a guided tour through the main subsystems of a relational database management system, as illustrated in the following figure, which I’ve simplified from the one in the paper. (This is for you Simon ;) ).
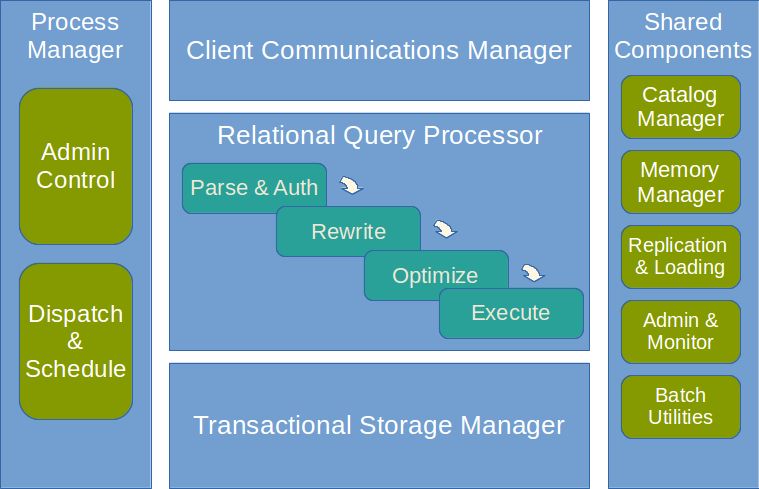
Each of the five main components is given a dedicated section in the paper. I can only hope to give the briefest of outlines in this short summary, I hope it whets your appetite to go ahead and read the whole thing.
Process Models
In this simplified context, a DBMS has three natural process model options. From the simplest to the most complex, these are: (1) process per DBMS worker, (2) thread per DBMS worker, and (3) process pool. Although these models are simplified, all three are in use by commercial DBMS systems today.
Process pool is a variant of process-per-worker, but with a bounded pool of workers (and thus a requestor waits if no process is available). As OS thread support improved, a second variant of this emerged based on a thread pool. Disk I/O buffers and Client Communication buffers are used to move request and results between processes.
As log entries are generated during transaction processing, they are staged to an in-memory queue that is periodically flushed to the log disk(s) in FIFO order. This queue is usually called the log tail. In many systems, a separate process or thread is responsible for periodically flushing the log tail to the disk.
To stop work from over-running the system, every DBMS needs admission control ( a lesson some enterprise systems are still learning!).
…any good multi-user system has an admission control policy, which does not accept new work unless sufficient DBMS resources are available. With a good admission controller, a system will display graceful degradation under overload: transaction latencies will increase proportionally to the arrival rate, but throughput will remain at peak.
You can have admission control ‘at the front door’ to limit the number of client connections, but it is also important to have admission control in the engine room:
The second layer of admission control must be implemented directly within the core DBMS relational query processor. This execution admission controller runs after the query is parsed and optimized, and determines whether a query is postponed, begins execution with fewer resources, or begins execution without additional constraints
There follows a discussion of scaling up and out and a look at shared memory, shared disk, shared nothing and NUMA architectures.
The shared-nothing architecture is fairly common today, and has unbeatable scalability and cost characteristics. It is mostly used at the extreme high end, typically for decision-support applications and data warehouses.
Circa 2007, what models were in use?
- Shared-Memory: All major commercial DBMS providers support shared memory parallelism including: IBM DB2, Oracle, and Microsoft SQL Server.
- Shared-Nothing: This model is supported by IBM DB2, Informix, Tandem, and NCR Teradata among others; Greenplum offers a custom version of PostgreSQL that supports shared-nothing parallelism.
- Shared-Disk: This model is supported by Oracle RAC, RDB (acquired by Oracle from Digital Equipment Corp.), and IBM DB2 for zSeries amongst others.
Relational Query Processor
A relational query processor takes a declarative SQL statement, validates it, optimizes it into a procedural dataflow execution plan, and (subject to admission control) executes that dataflow program on behalf of a client program.
The main tasks for a SQL Parser are:
- check that the query is correctly specified
- resolve names and references
- convert the query into the internal format used by the optimizer
- verify that the user is authorized to execute the query
The query rewrite module, or rewriter, is responsible for simplifying and normalizing the query without changing its semantics. It can rely only on the query and on metadata in the catalog, and cannot access data in the tables.
It performs tasks such as: view expansion; constant arithmetic evaluation; logical rewriting of predicates; semantic optimization (for example, exploiting integrity constraints); sub-query flattening and other heuristic rewrites.
The query optimizer’s job is to transform an internal query representation into an efficient query plan for executing the query. A query plan can be thought of as a dataflow diagram that pipes table data through a graph of query operators.
Each individual query block is then optimized to generate a query plan: “every major DBMS now compiles queries into some kind of interpretable data structure.”
Damn those application programmers: !
Many application programmers, as well as toolkits like Ruby on Rails, build SQL statements dynamically during program execution, so pre-compiling is not an option. Because this is so common, DBMSs store these dynamic query execution plans in the query plan cache. If the same (or very similar) statement is subsequently submitted, the cached version is used. This technique approximates the performance of pre-compiled static SQL without the application model restrictions and is heavily used.
The query executor executes a query plan (who would have thought ;) ).
Most modern query executors employ the iterator model that was used in the earliest relational systems.
There is a nice discussion concerning the different needs of data warehouses, which we don’t have space to go into here. With respect to yesterday’s look at Mesa though, this paragraph shows that some of the underlying ideas go well back:
If one keeps before and after values of updates, suitably timestamped, then one can provide queries as of a time in the recent past. Running a collection of queries as of the same historical time will provide compatible answers. Moreover, the same historical queries can be run without setting read locks.
Storage Management
Since the DBMS can understand its workload access patterns more deeply than the underlying OS, it makes sense for DBMS architects to exercise full control over the spatial positioning of database blocks on disk.
An alternative to raw disk access is to create very large files in the OS file system.
In addition to controlling where on the disk data should be placed, a DBMS must control when data gets physically written to the disk.
Here’s a possible surprise for you: a well-tuned database is typically not I/O bound….
Copying data in memory can be a serious bottleneck. Copies contribute latency, consume CPU cycles, and can flood the CPU data cache. This fact is often a surprise to people who have not operated or implemented a database system, and assume that main-memory operations are “free” compared to disk I/O. But in practice, throughput in a well-tuned transaction processing DBMS is typically not I/O-bound.
As we move from spinning disk to flash, will anything change?
One key technological change is the emergence of flash memory as an economically viable random-access persistent storage technology. Ever since the early days of database system research, there has been discussion of sea-changes in DBMS design arising from new storage technologies replacing disk. Flash memory appears to be both technologically viable and economically supported by a broad market, and presents an interesting intermediate cost/performance trade-off relative to disk and RAM. Flash is the first new persistent storage medium to succeed in this regard in more than three decades, and hence its particulars may have significant impact on future DBMS designs.
Transactions, Concurrency Control, and Recovery
What does it take to become an expert in this area?
The reader wishing to become knowledgeable about these systems should read — at a minimum — a basic undergraduate database textbook, the journal article on the ARIES log protocol, and at least one serious article on transactional index concurrency and logging. More advanced readers will want to consult Gray and Reuter’s textbook on transactions. To really become an expert, this reading has to be followed by an implementation effort.
We are treated to a very approachable discussion of ACID, serializability, and the main concurrency control techniques.
Many people are familiar with the term “ACID transactions,” a mnemonic due to Haerder and Reuter. ACID stands for Atomicity, Consistency, Isolation, and Durability. These terms were not formally defined, and are not mathematical axioms that combine to guarantee transactional consistency. So it is not important to carefully distinguish the terms and their relationships. But despite the informal nature, the ACID acronym is useful to organize a discussion of transaction systems…
Isolation is implemented via a locking protocol; durability via logging and recovery. Isolation and Atomicity via a combination of locking and logging, and consistency by runtime checks in the query optimizer.
Serializability is the well-defined textbook notion of correctness for concurrent transactions. It dictates that a sequence of interleaved actions for multiple committing transactions must correspond to some serial execution of the transactions — as though there were no parallel execution at all…. Isolation is the same idea from the point of view of a single transaction. A transaction is said to execute in isolation if it does not see any concurrency anomalies.
The three broad techniques of concurrency control enforcement are:
- Strict two-phase locking
- Multi-Version Concurrency Control, and
- Optimistic Concurrency Control
The ANSI SQL isolation levels are discussed, as well as some additional isolation levels popularized by commercial systems.
Unfortunately, as noted by Berenson et al., neither the early work by Gray nor the ANSI standard achieve the goal of providing truly declarative definitions. Both rely in subtle ways on an assumption that a locking scheme is used for concurrency control, as opposed to an optimistic or multi-version concurrency scheme. This implies that the proposed semantics are ill-defined.
For recovery, the standard approach is to use a Write-Ahead Logging protocol. “The WAL protocol consists of three very simple rules:”
- Each modification to a database page should generate a log record, and the log record must be flushed to the log device before the database page is flushed.
- Database log records must be flushed in order; log record r cannot be flushed until all log records preceding r are flushed.
- Upon a transaction commit request, a commit log record must be flushed to the log device before the commit request returns successfully.
Many people only remember the first of these rules, but all three are required for correct behavior.
If you are thinking of implementing your own transactional storage system, heed the authors’ warning that:
It is a significant intellectual and engineering challenge to take a textbook access method algorithm (e.g., linear hashing [53] or R-trees [32]) and implement a correct, high-concurrency, recoverable version in a transactional system. For this reason, most leading DBMSs still only implement heap files and B+-trees as transactionally protected access methods; PostgreSQL’s GiST implementation is a notable exception
Shared Components
Here you’ll find an overview of the catalog manager, memory allocator, disk management subsystem, replication, and a look at administration and monitoring.
The first lesson is to use the same format and tools for metadata as you do for the data itself:
By keeping the metadata in the same format as the data, the system is made both more compact and simpler to use: users can employ the same language and tools to investigate the metadata that they use for other data, and the internal system code for managing the metadata is largely the same as the code for managing other tables. This code and language reuse is an important lesson that is often overlooked in early stage implementations, typically to the significant regret of developers later on. One of the authors witnessed this mistake yet again in an industrial setting within the last decade.
For replication there are three basic techniques, but “only the third provides the performance and scalability needed for high-end settings. It is, of course, the most difficult to implement.”
- Physical replication – duplicate the entire database every replication period.
- Trigger-based replication – use triggers to store ‘difference’ records in a special replication table
- Log-based replication.
Log-based replication is the replication solution of choice when feasible. In log-based replication, a log sniffer process intercepts log writes and delivers them to the remote system.
In Conclusion
As should be clear from this paper, modern commercial database systems are grounded both in academic research and in the experiences of developing industrial-strength products for high-end customers. The task of writing and maintaining a high-performance, fully functional relational DBMS from scratch is an enormous investment in time and energy. Many of the lessons of relational DBMSs, however, translate over to new domains. Web services, network-attached storage, text and e-mail repositories, notification services, and network monitors can all benefit from DBMS research and experience. Data-intensive services are at the core of computing today, and knowledge of database system design is a skill that is broadly applicable, both inside and outside the halls of the main database shops.
Enjoy!

Hi Adrian. Thank you for the concise and very well articulated post regarding the science behind DBMS. For completeness sake you might want to add Microsoft APS production to you list of “share-nothing” processing models.