A new presumed commit optimisation for two phase commit – Lampson and Lomet 1993.
Two phase commit (2PC) is the protocol used to coordinate distributed transactions. In this paper Lampson and Lomet first recap the basic 2PC protocol in its ‘presumed nothing’ form, then go on to describe the traditional ‘presumed abort’ and ‘presumed commit’ optimizations. Then finally they introduce a new presumed commit protocol that has lower message and log write costs. The secret involves a trade-off (keeping a small amount of state around potentially forever) in return for reduced logging. As you will see in the analysis, the amount of state is tiny and the trade-off looks to be a good one.
In all of the variants we will discuss, there is a coordinator driving the transaction to an agreed outcome, and a number of cohorts (resource managers) that all need to agree on whether to commit or to abort. Of course the tricky bit is that anything can fail at any time…
The basic presumed nothing protocol
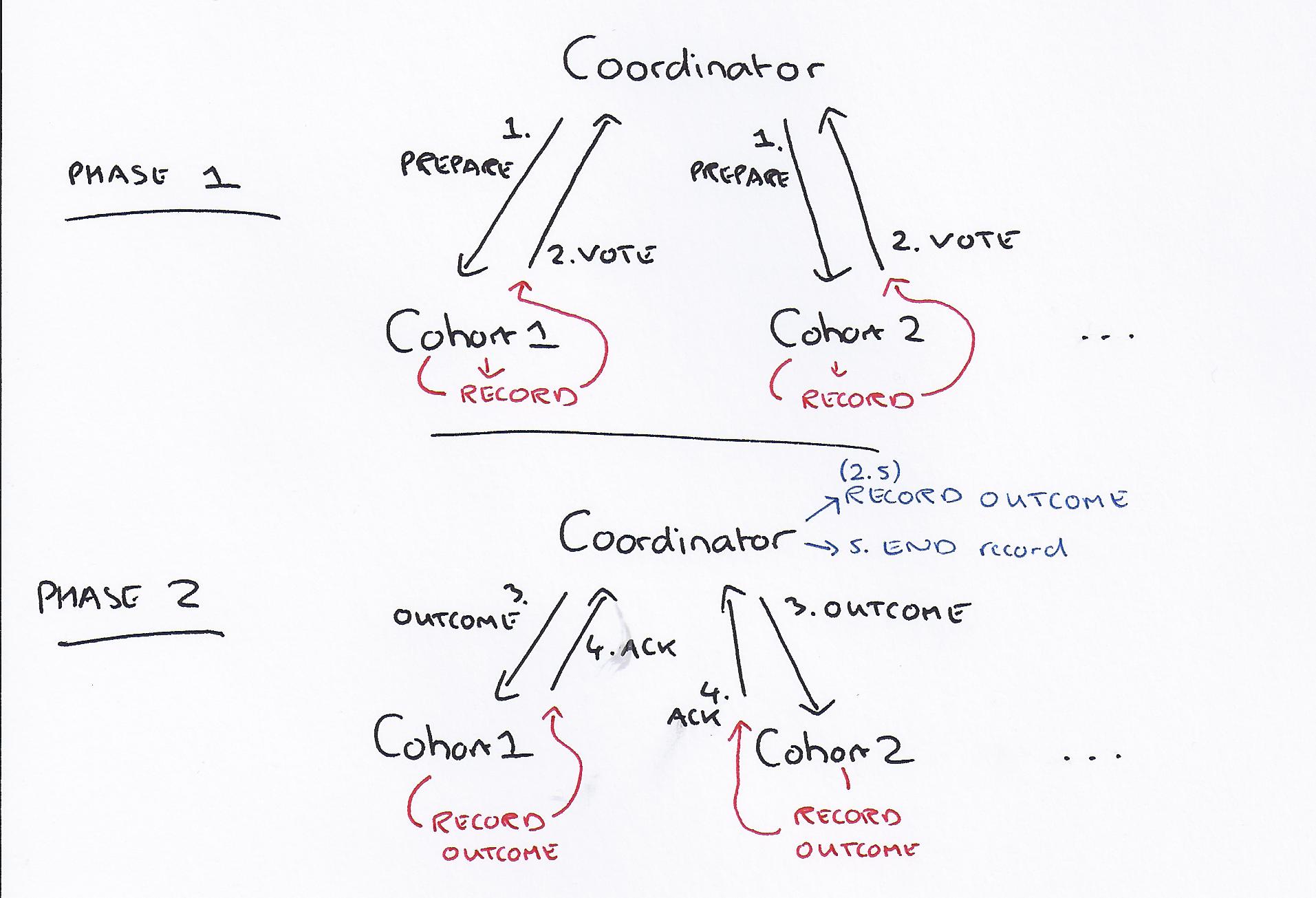
In phase 1:
* The coordinator sends a PREPARE message to all cohorts
* Each cohort may respond with an ABORT-VOTE, or stably record everything needed to later commit the transaction and respond with a COMMIT-VOTE
The coordinator records the outcome in its log (COMMIT iff all cohorts voted to COMMIT, ABORT otherwise).
In phase 2:
* The coordinator sends an outcome message (COMMIT-VOTE or ABORT-VOTE) to all cohorts
* The cohort writes the transaction outcome to its log (after this, it never needs to ask the coordinator for the outcome again if it crashes), and replies with an ACK message.
The coordinator writes an END message to its log, which tells it not to reconstruct in-memory information about the transaction on recovering after a crash.
Cost of the presumed nothing protocol:
To commit a transaction, a PrN coordinator does two log writes, the commit record (forced) and the transaction end record (not forced). In addition, it sends two messages to each of the cohorts, PREPARE and COMMIT. In response, each cohort does two log writes, a prepare record and a commit record (both forced), and sends two messages, a COMMIT-VOTE and a final ACK.
Presumed abort optimization
Once a transaction has aborted, its entry is deleted from the coordinators in-memory database, since a missing entry will be presumed to have aborted. No information needs to be logged about such transactions because there will never be any need to recovery an in-memory state for them.
In summary, PrA aborts a transaction more cheaply than PrN, and it commits one in exactly the same way.
Presumed commit optimization
Presumed commit is kind of the opposite. Instead of assuming that a missing transaction is aborted, we assume it has committed.
For presumed commit (PrC), the coordinator explicitly documents which transactions have aborted. While this has some apparent symmetry with PrA, which explicitly documents committed transactions, in fact there is a fundamental difference. With PrA, we can be very lazy about making the existence of a transaction stable in the log. If there is a failure first, we presume it has aborted. But PrC needs a stable record of every transaction that has started to prepare because missing transactions are presumed to have committed, and a commit presumption is wrong for a transaction that fails early.
When a transaction commits, it is removed from the in-memory database. If a cohort subsequently inquires, it is told the transaction committed (by presumption). Therefore ACKs are avoided for committed transactions (which are much more common than aborted ones).
Bonus: Read-only optimization
If a cohort is read-only it doesn’t need to do any logging and doesn’t care about the transaction outcome, it can send a READ-ONLY-VOTE, release its locks, and forget the transaction.
If all cohorts send a read-only vote then the coordinator doesn’t send an outcome message, and it can freely choose whatever outcome causes the least logging.
Costs of presumed commit vs presumed abort
It is the coordinator logging that makes PrA preferable to PrC. To commit a transaction, a PrC coordinator forces two log records, while PrA forces only one record; its other log write is not forced. The extra forced write is for PrC’s transaction initiation record, and it is needed for every transaction.
But the PrC protocol has an advantage in message costs, therefore if the forced initiation record logging could be avoided, it would be better a option than PrA.
An improved presumed commit protocol
On recovery, instead of having full knowledge about every active transaction, we can get away with limited knowledge about all of the transactions that may have been initiated but not committed. Call this the “Initiated Set” – which may in practice include not only active transactions but also those which were never initiated and those which aborted.
If we assume monotonically increasing transaction ids, we can bound the “Initiated Set” to transactions with ids in some interval. Every transaction in this set has an abort outcome by presumption on recovery. To find the upper bound, we can either take the highest transaction id on the log and add some delta to it (an example is given of 100 tx ids), or we can read its value explicitly from the log. (Which requires periodically writing candidate upper bound tx ids to the log).
The lower bound is written to the log so that we know it after a crash.
We ensure that tidl (the lower bound) is known after a crash by writing it to the log. We can advance tidl whenever that transaction terminates, i.e., either commits or aborts. When this happens we write to the log the new value for tidl along with the commit or abort record that we are writing anyway. Thus it is recorded without extra log writes or forces.
After a crash, transaction ids greater than the lower bound are presumed to have aborted. Transaction ids for transactions initiated after recovery start from the upper bound. The “Initiated Set” at the time of a crash may need to be stored indefinitely.
Even assuming that the system crashes once a day (which is high for a well managed system), and the system is in operation seven days a week, it would take 2000 days or six years to accumulate one megabyte of crash related IN information. The current purchase price (1993) of a megabyte of disk space is two dollars.
(Today, it costs about $0.03 per GB!)
The 2PC protocol begins when the coordinator receives a commit directive from some cohort of the transaction or from the application. The coordinator sends out PREPARE messages to cohorts asking them whether to commit the transaction. No log record is forced, or even written. The coordinator then waits to receive responses from all cohorts.
- If any cohort sends an ABORT-VOTE the coordinator sends an ABORT-VOTE outcome message to all participants. When all ACKS have been received the transaction is deleted from the in-memory database and the lower-bound of the Initiation Set is advanced.
- If all votes are in and the decision is to commit, then the coordinator forces a commit log record. No ACK messages are expected. The lower-bound of the Initiation Set is advanced (if this was the oldest active transaction).
- If all cohorts voted READ-ONLY then the coordinator does not write any log record or send any additional messages.
We have traded the ongoing logging necessary to permit us to always garbage collect our protocol database entries after a coordinator crash for the cost of storing forever a small amount of information about each crash. This appears to be a good trade.

Hi,
Nice article !!!
I have followed this link because, you did reference in the SoK. Then, my question is if you know that exist some blockchain project that implement this class of distributed consensus or the application range for 2pc is only in distributed systems.
Thanks a lot.