Spanner: becoming a SQL system Bacon et al., SIGMOD’17
This week we’ll start digging into some of the papers from SIGMOD’17. First up is a terrific ‘update’ paper on Google’s Spanner which brings the story up to date in the five years since the original OSDI’12 paper.
… in many ways, today’s Spanner is very different from what was described there.
If you had to sum up the change in two words, they would probably be these: “more SQL!”
Of course, as well as being one of the most important internal systems at Google, Spanner is also now available for you to use too in ‘Cloud Spanner‘ form as part of GCP. This paper will give you a deeper understanding of what Spanner can do for you.
Why did Spanner evolve?
A prime motivation for this evolution towards a more “database-like” system was driven by the experiences of Google developers trying to build on previous “key-value” storage systems. [E.g., Bigtable].
Bigtable is still widely used at Google, but for OLTP style applications developers struggled without a strong schema system, cross-row transactions, consistent replication, and a powerful query language. Trying to provide these features on top of Bigtable only went so far.
As a result, we decided to turn Spanner into a full featured SQL system, with query execution tightly integrated with the other architectural features of Spanner (such as strong consistency and global replication).
Just because Spanner embraced SQL though, that doesn’t mean it abandoned scalability goals: “In web companies, scalability has never been subject to compromise, hence all Google’s systems, including Spanner, start there.” The two key challenges in supporting scalability cited by the Spanner team are manageability and transactions.
A scalable data management system must address manageability early on to remain viable. For Spanner, than meant transparent failover across clusters and the ability to reshard data easily upon expanding the system… ACID transactions spanning arbitrary rows/keys is the next hardest challenge for scalable data management systems. Transactions are essential for mission-critical applications, in which any inconsistency, even temporary, is unacceptable. Making ACID work at scale is extremely difficult, and required substantial innovation in Spanner, as discussed in [the original OSDI’12 paper].
There’s plenty of great information in this paper, including a nice succinct overview of Spanner’s overall architecture in section 2. I’m mostly going to focus on three key aspects in this write-up:
- how Spanner supports distributed query execution efficiently
- how Spanner decides which servers should process a query and how it minimises scanning and locking on those servers, using range extraction
- why Spanner expends so much effort to support restartable queries
Distributed query execution
The Spanner SQL query compiler represents distribution using explicit operators in the query algebra tree (following a long line going all the way back to Volcano). The fundamental building block is the Distributed Union operator, which ships a subquery to each relevant shard and concatenates the results.
Distributed Union is a fundamental operation in spanner, especially because the sharding of a table may change during query execution, and after a query restart.
To start with, a Distributed Union operator is inserted immediately above every Spanner table so that global scans are replaced by explicit distributed operations using local scans of table shards. Where possible, Distributed Unions are then pulled up the tree. This has the effect of leaving more of the computation below the distributed union – i.e., work is pushed down so that the maximum amount possible is carried out by the servers responsible for the data shards.
In order for these operator tree transformations to be equivalent, a property we call partitionability must be satisfied for any relational operation F that we want to push down.
This condition states that performing an ordered union of the results of applying F to each shard in table key order gives the same outcome as applying F to the results of a global scan.
Being aware of keys or identity columns of the underlying data set, Spanner can push more complex operations such as grouping and sorting to be executed close to the data where the sharding columns are a proper subset of grouping or sorting columns. This is possible because Spanner uses range sharding.
In addition to range sharding, Spanner supports table interleaving which colocates rows from multiple tables sharing a primary key prefix: all ‘child table’ rows are stored physically next to the ‘parent table’ row they join on. This means that joins between such tables can also be pushed down below the Distributed Union for common sharding keys.
Consider the SQL query

It results in the following distributed execution plan, where the distributed unions initially inserted directly above the Customer and Sales scans have been pulled up and unified almost at the very top of the tree:
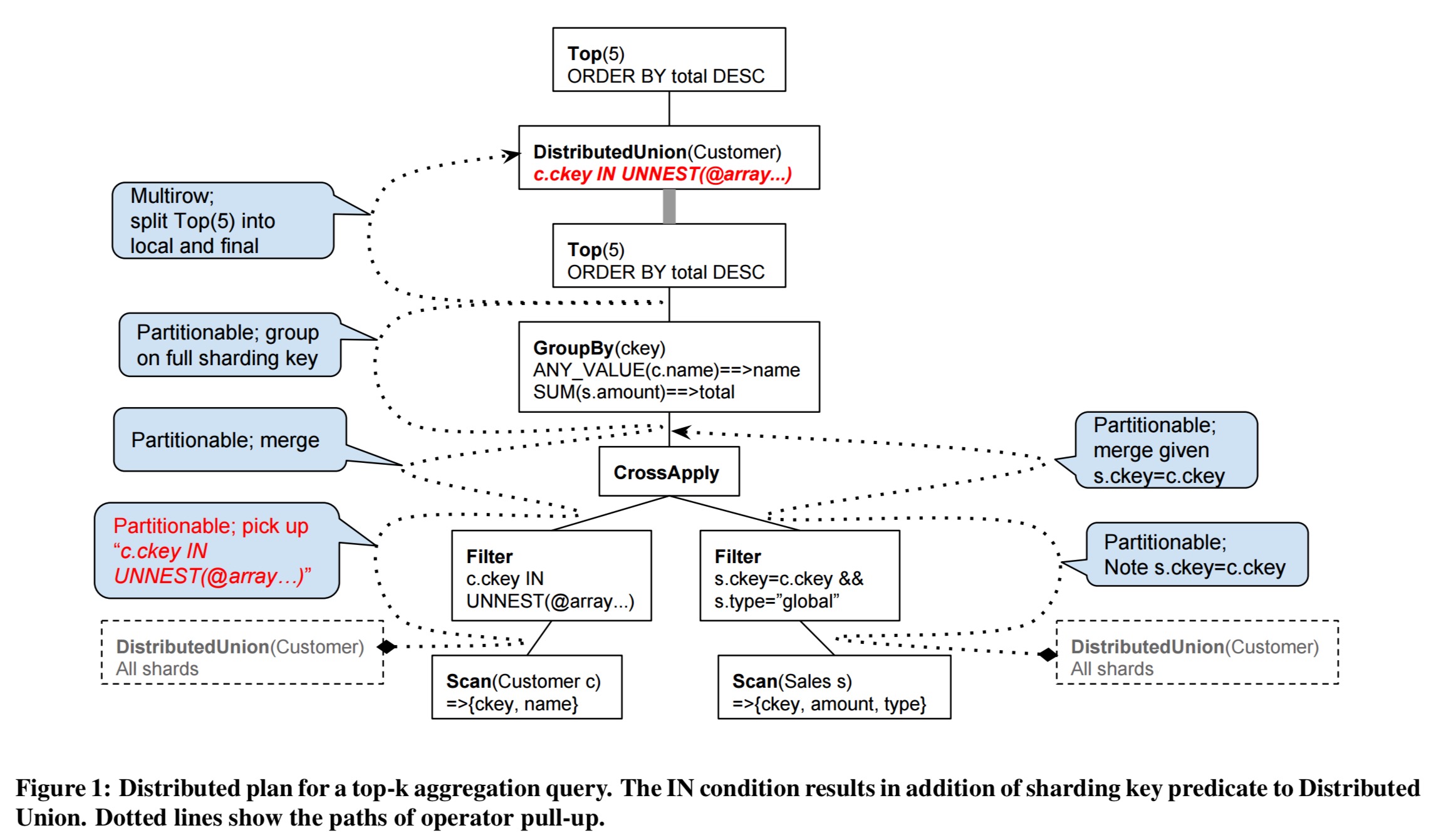
At runtime, Distributed Union minimizes latency by using the Spanner coprocessor framework to route a subquery request addressed to a shard to one of the nearest replicas that can serve the request. Shard pruning is used to avoid querying irrelevant shards. Shard pruning leverages the range keys of the shards and depends on pushing down conditions on sharding keys of tables to the underlying scans.
Range extraction, described below, extracts a set of ranges guaranteed to fully cover all table rows on which a subquery may yield results, and is the heart of shard pruning.
Subqueries are dispatched to every relevant shard in parallel.
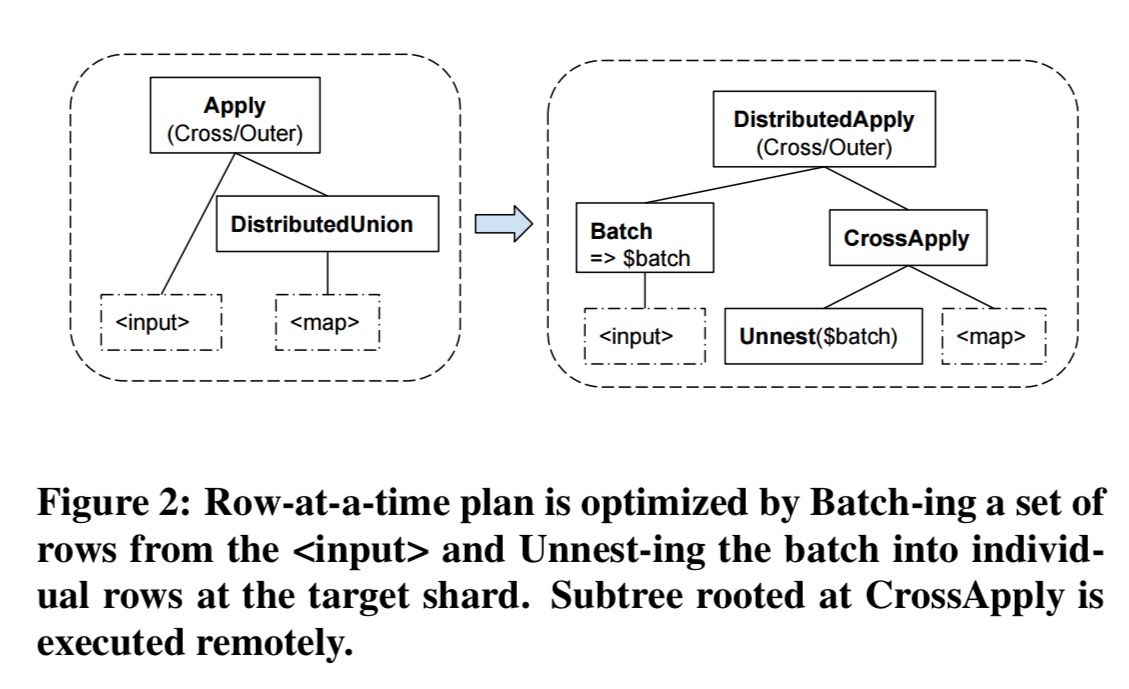
Joins between independently distributed tables could be the subject of a whole other paper. Here the authors focus on one example, the batched apply join which is mostly used to join a secondary index and its independently distributed base table.
Spanner implements a Distributed Apply operator by extending Distributed Union and implementing Apply style join in a batched manner – as two joins, a distributed join that applies batches of rows from the input to remote subquery, and another that applies rows from each batch to the original join’s subquery locally on a shard.
When a client makes a query via the API, Spanner will attempt to route the query directly to the server that owns all or part of the data referenced by the query. The first time the query is submitted, it may go to any server. At this point the query is analysed and a location hint is determined and sent to the client for caching. The location hint enables the client to cheaply compute where to send the query on subsequent executions.
Spanner also has explicit support for the case where the results of a query need to be processed in parallel, using the parallel consumer API. This works in two stages:
The first is to divide the work between the desired number of clients. The API receives a SQL query and the desired degree of parallelism, and returns a set of opaque query partition descriptors. In the second stage, the query is executed on the individual partitions, normally using requests initiated in parallel from separate machines. The parallel-consumer API guarantees that the concatenation of results from all the partitions yields the same unordered set of rows as for the query submitted through the single-consumer API.
Range extraction
Range extraction is the process of analysing a query to determine what portions of tables it references. There are three flavours of range extraction:
- Distributed range extraction figure out which table shards are referenced by a query.
- Seek range extraction determines what fragments of a relevant shard to read from the underlying storage stack.
- Lock range extraction determines what fragments of a table are to be locked (pessimistic txns) or checked for potential pending modifications (snapshot txns).
Our implementation of range extraction in Spanner relies on two main techniques: At compile time, we normalize and rewrite a filtered scan expression into a tree of correlated self-joins that extract the ranges for successive key columns. At runtime, we use a special data structure called a filter tree for both computing the ranges via bottom-up interval arithmetic and for efficient evaluation of post-filtering conditions.
Range computation is in general a conservative approximation as isolating key columns in predicates can be arbitrarily complex and there are diminishing returns. In the worst case, for distribution range extraction, a query may be sent to a shard that ultimately returns no rows.
… the trade-offs of seeks vs scans and granularity of locking involve optimization decisions that can be very tricky and are beyond the scope of this paper.
Restartable queries
Spanner supports automatic query restarts in the event of failures, resharding, and binary rollouts. This is implement inside of the query processor by capturing the distributed state of the query plan being executed using restart tokens. Tokens must be robust to dynamic resharding (ongoing splitting, merging and moving of data). Furthermore, the non-determinism which makes for high performance query execution opportunities complicates restart as results may be returned in a non-repeatable order. Finally, Spanner also support restarts even across the rollout of new server versions which involves ensuring backwards compatibility of the restart token wire format, preserving query plans across query restarts, and backwards compatibility in operator behaviours. It’s a lot of work!
Overall, support for restarts came at a considerable engineering cost. Among other things, it required developing a restart token versioning mechanism, processes that force explicit versioning upon incompatible changes, and a framework to catch incompatibilities. Addressing those challenges was hard, but worth it because transparent restarts improve user-perceived system stability and provide important flexibility in other aspects of Spanner’s design.
Some of the benefits delivered by the query restart mechanism include:
- Hiding transient failures including network disconnects, machine reboots, process crashes, distributed waits, and data movement.
- A simplified programming model that does not require the programmer to code retry loops. (“Retry loops in database client code is a source of hard to troubleshoot bugs, since writing a retry loop with proper backoff is not trivial.”)
- Support for long-running queries instead of paging queries (avoiding the need for sorting solely to support pagination)
- Improved tail latencies for online requests through the minimal amount of work that needs to be redone when restarting queries
- Forward progress guarantees for long-running queries where the running time is comparable to the mean time to (transient) failure.
- Support for recurrent rolling upgrades. “For the past few years of widespread Spanner use inside Google there were very few moments when no Spanner zone was being upgraded to a new version, mostly during the brief holiday lulls.”
The ability to gradually upgrade all machines to a new version within a week or so while running a few versions concurrently has been a cornerstone of Spanner’s development agility.
Other interesting bits and pieces from the paper
Google moved to a standard internal SQL dialect (“Standard SQL”) shared by all of their systems (e.g., Spanner, F1, Dremel, BigQuery). To make this work took quite a bit of effort. Several shared components ensure consistency across systems: the compiler front-end, a library of scalar functions, and a shared testing framework and tests.
Spanner now has a new low-level storage format called Ressi, designed from the ground-up for handling SQL queries over large-scale distributed databases with a mix of OLTP and OLAP workloads. Ressi stores a database as an LSM tree, and divides values into an active file containing only the most recent values, and an inactive file which may contain older versions. This helps to more efficiently support Spanner’s time-versioned semantics.
Despite the critique of one-fits-all systems, combining OLTP, OLAP, and full-text search capabilities in a single system remains at the top of customer priorities. Large-scale deployment and monitoring of multiple systems with different availability guarantees, transactional semantics, rollout cycles, and language and API quirks is a major burden on customers. It is our goal to make Spanner perform well and be cost-effective across a broad spectrum of use cases over time.

6 thoughts on “Spanner: becoming a SQL system”
Comments are closed.