Towards federated learning at scale: system design Bonawitz et al., SysML 2019
This is a high level paper describing Google’s production system for federated learning. One of the most interesting things to me here is simply to know that Google are working on this, have a first version in production working with tens of millions of devices, and see significant future expansion for the technology (‘we anticipate uses where the number of devices reaches billions’).
So what exactly is federated learning?
Federated Learning (FL) is a distributed machine learning approach which enables training on a large corpus of decentralized data residing on devices like mobile phones. FL is one instance of the more general approach of “bringing the code to the data, instead of the data to the code” and addresses the fundamental problems of privacy, ownership, and locality of data.
Note that this beyond using an on-device model to make predictions based on local data. Here we’re actually training the model in a distributed fashion, using data collected on the devices, without the data ever leaving those devices. The FL system contains a number of privacy-enhancing building blocks, but the privacy guarantees of any end-to-end system will always depend on how they are used.
At the core of the system is a federated learning approach called Federated Averaging, with an optional extension for Secure Aggregation. The bulk of the paper is about the practicalities of running these algorithms at scale across a large fleet of devices: managing device availability, coordinating activity over unreliable networks and devices, building and deploying training workflows, and troubleshooting when things go wrong.
Federated Averaging
There’s a good high-level overview of federated learning on Google’s AI blog. Devices download the current model, improve it by learning using data local to the phone, and then send a small focused model update back to the cloud, where it is averaged with other user updates to improve the shared model. No individual updates are stored in the cloud, and no training data leaves the device.
The Federated Averaging algorithm addresses one of the key challenges in making this practical: reducing the communication volume (by 10-100x) between the model server and the devices. “The key idea is to use the powerful processors in modern mobile devices to compute higher quality updates than simple gradient steps.”

Secure Aggregation
Secure aggregation was introduced in a 2017 paper by Bonawitz et al., ‘Practical secure aggregation for privacy-preserving machine learning.’ The core idea is to make individual device updates opaque to the server, only revealing the sum after a sufficient number of updates have been received. Devices upload cryptographically masked updates and the server computes a sum over those updates. In a finalisation round the devices then reveal sufficient cryptographic secrets for the server to unmask the aggregated model update.
We can deploy Secure Aggregation as a privacy enhancement to the FL service that protects against additional threats within the data center by ensuring that individual devices’ updates remain encrypted even in memory.
The costs associated with Secure Aggregation are quadratic in the number of users, limiting the maximum size of a secure aggregation to hundreds of users. To scale beyond this, the FL service uses multiple secure aggregation groups, and then aggregates the group results into a final aggregate (without using Secure Aggregation for this last part).
The Federated Learning Protocol
The FL system overall comprises a set of devices (e.g., Android phones) that can run FL tasks, and a cloud-based FL server which coordinates their activities. Each FL task is associated with an FL population (globally unique name to identify a learning problem or application being worked on). Within a task a device receives an FL plan, which includes a TensorFlow graph and instructions for how to execute it.
One of the key challenges is picking a set of devices to work on a specific FL task, given that synchronous communication is required for the task duration.
From the potential tens of thousands of devices announcing availability to the server during a certain time window, the server selects a subset of typically a few hundred which are invited to work on a specific FL task. We call this rendezvous between devices and server a round. Devices stay connected to the server for the duration of the round.
Once a round is established, the server sends the current global model parameters and any other necessary state to the devices as an FL checkpoint. The devices perform their local computation and send an update back in FL checkpoint form.
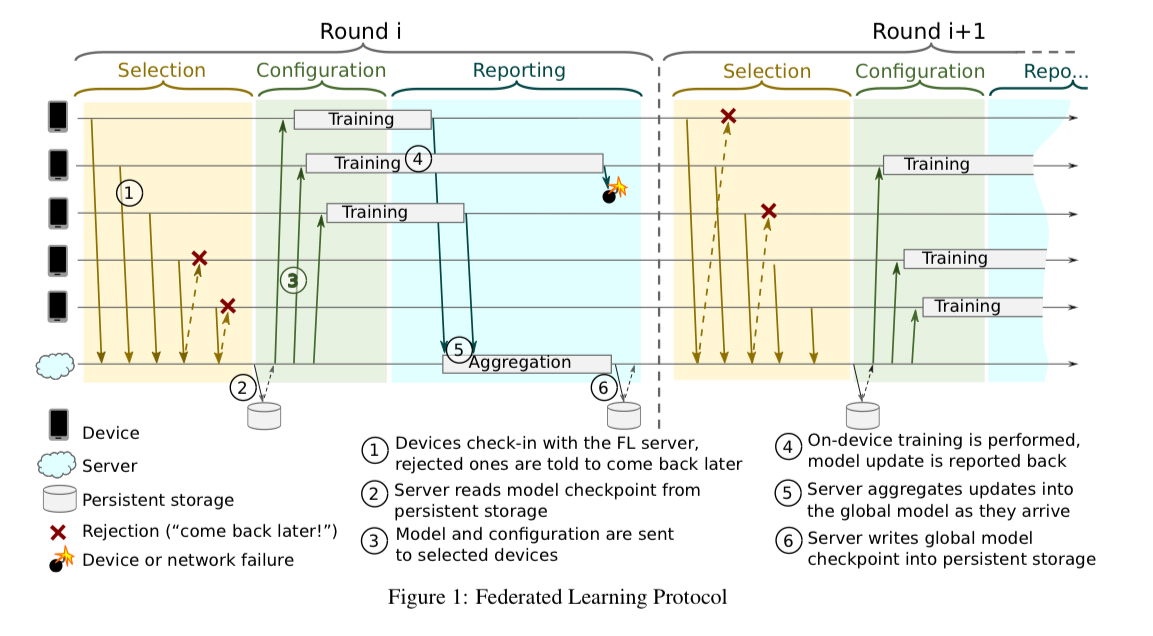
As the round progresses, devices report their updates. If enough devices report in time the round will be successfully completed and the server will update its global model, otherwise the round is abandoned.
Within the FL Server (which is itself a distributed system of course), it’s the job of selectors to identify devices for a round. Jobs will only be invoked on phones that are idle, charging, and connected to an unmetered network such as WiFi. A running job will abort if these conditions are no longer met. To allow for dropouts, if a model update needs K responses to be valid, 1.3K devices are selected to participate in the round. A flow-control mechanism called pace steering helps to ensure that just enough devices are connected to the server at any one time to meet these needs.
Pace steering is based on the simple mechanism of the server suggesting to the device the optimum time window to reconnect. The device attempts to respect this, modulo its eligibility.
With smaller groups, pace steering helps to ensure enough devices are online. With large groups, pace steering helps to randomise device check-in times, avoiding thundering herds.
Developing models using federated learning
Compared to the standard model engineer workflows on centrally collected data, on-device training poses multiple novel challenges…
- Individual training examples are not directly inspectable
- Models cannot be run interactively but must instead be compiled into FL plans to be deployed via the FL server
- Model resource consumption and runtime compatibility must be verified automatically by the infrastructure
Model engineers define FL tasks in Python, and initial hyperparameter exploration can be done locally in simulation using proxy data. The modelling tools support deployment of FL tasks to a simulated FL server and fleet of cloud jobs emulating devices. The FL Plan is also represented by a Python program.
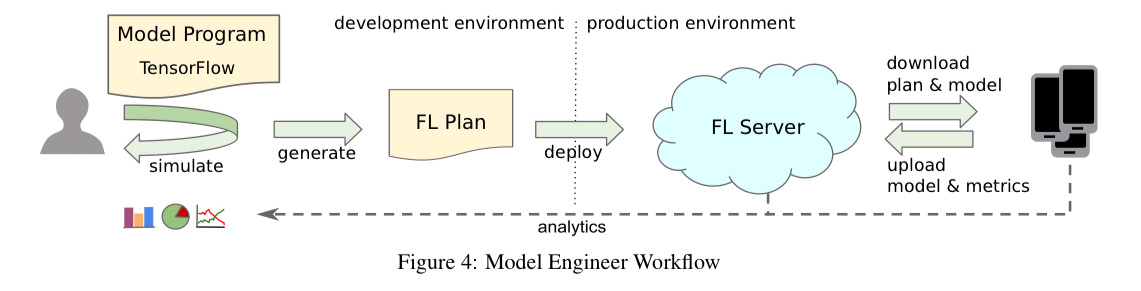
In contrast to data-center training, where the TensorFlow runtime and graphs can generally be rebuilt as needed, devices may be running a version of the TensorFlow runtime that is many months older than what is required by the FL plan generated by modelers today.
The FL infrastructure generates versioned plans for each task. These transform the computation graph of the original plan to achieve compatibility with a given deployed version.
Use cases so far
FL at Google has been used for on-device item ranking (e.g. search results), content suggestion (for on-device keyboards), and next-work prediction. It has been in production for over a year.
We designed the FL system to elastically scale with the number and sizes of the FL populations, potentially up into the billions. Currently the system is handling a cumulative FL population size of approximately 10M daily active devices, spanning several different applications.
Up to 10K devices have been observed participating simultaneously. For most models, receiving updates from a few hundred devices per round has been sufficient. On average, between 6% and 10% of devices drop out of any given round due to changes in network conditions or eligibility.
Towards a general purpose on-device data processing framework
Beyond just ML, expect to see more on-device computation from Google in the future:
We aim to generalize our system from Federated Learning to Federated Computation, which follows the same basic principles as described in this paper, but does not restrict computation to ML with TensorFlow, but general MapReduce like workloads. One application area we are seeing is in Federated Analytics, which would allow us to monitor aggregate device statistics without logging raw device data to the cloud.

One thought on “Towards federated learning at scale: system design”
Comments are closed.